Join us for the latest webinar on AI Agent Wars – The Hype, Hope, and Hidden Risks on 7/24
Register
Product
Fiddler AI Observability
Why Fiddler AI Observability
Overview of key capabilities and benefits
Agentic Observability
Unified multi-agent visibility with hierarchical analysis and insights
Fiddler Trust Service
Guardrails and LLM application monitoring with Fiddler Trust Models
LLM Observability
AI Observability for end-to-end LLMOps
ML Observability
Deliver high performing AI solutions at scale
Model Monitoring
Detect model drift, assess performance and integrity, and set alerts
NLP and CV Monitoring
Monitor and uncover anomalies in unstructured models
Explainable AI
Understand the ‘why’ and ‘how’ behind your models
Analytics
Connect predictions with context to business alignment and value
Responsible AI
Mitigate bias and build a responsible AI culture
See Fiddler in action
Ready to get started?
Request demo
Solutions
Use Cases
Government
Safeguard citizens and national security
AI Governance, Risk Management, and Compliance (GRC)
Enhance AI governance, mitigate risks, and meet compliance standards
Customer Experience
Deliver seamless customer experiences
Lifetime Value
Extend the customer lifetime value
Lending and Trading
Make fair and transparent lending decisions
Partners
Amazon SageMaker AI
Unified MLOps for scalable model lifecycle management
Google Cloud
Deploy safe and trustworthy AI applications on Vertex AI
NVIDIA NIM and NeMo Guardrails
Monitor and protect LLM applications
Databricks
Accelerate production ML with a streamlined MLOps experience
Datadog
Gain complete visibility into the performance of your AI applications
Become a partner
Case Studies
U.S. Navy decreased 97% time needed to update the ATR models
Integral Ad Science scales transparent and compliant AI products with AI Observability
Tide drives innovation, scale, and savings with AI Observability
See customers
Pricing
Pricing Plans
Choose the plan that’s right for you
Plan Comparison
Compare platform capabilities and support across plans
Platform Pricing Methodology
Discover our simple and transparent pricing
FAQs
Pricing answers from frequently asked questions
Build vs Buy
Key considerations for buying AI Observability solution
Contact Sales
Have questions about pricing, plans, or Fiddler?
Resources
Learn
Resource Library
Discover reports, videos, and research
Docs
Get in-depth user guides and technical documentation
Blog
Read product updates, data science research, and company news
AI Forward Summit
Watch recordings on how to operationalize production LLMs, and maximize the value of AI
Connect
Events
Find out about upcoming events
Webinars
Learn from industry experts on pressing issues in MLOps and LLMOps
Contact Us
Get in touch with the Fiddler team
Support
Need help with the platform? Contact our support team
The Ultimate Guide to LLM Monitoring
Learn how enterprises should standardize and accelerate LLM application development, deployment, and management
Read guide
Company
Company
About Us
Our mission and who we are
Customers
Learn how customers use Fiddler
Careers
We're hiring!
Join fiddler to build trustworthy and responsible AI solutions
Newsroom
Explore recent news and press releases
Security
Enterprise-grade security and compliance standards
Featured News
Top 10 AI Companies Shaping the Tech World
Bloomberg: AI-Equipped Underwater Drones Helping US Navy Scan for Threats
AI Observability: The Key to Unlocking the Full Potential of Large Language Models
The insideBIGDATA IMPACT 50 List for Q3 2024
We're on a mission to build trust into AI
Join us
Request demo
Run free guardrails
Fiddler Blog
Krishna Gade, Kirti Dewan, Karen He
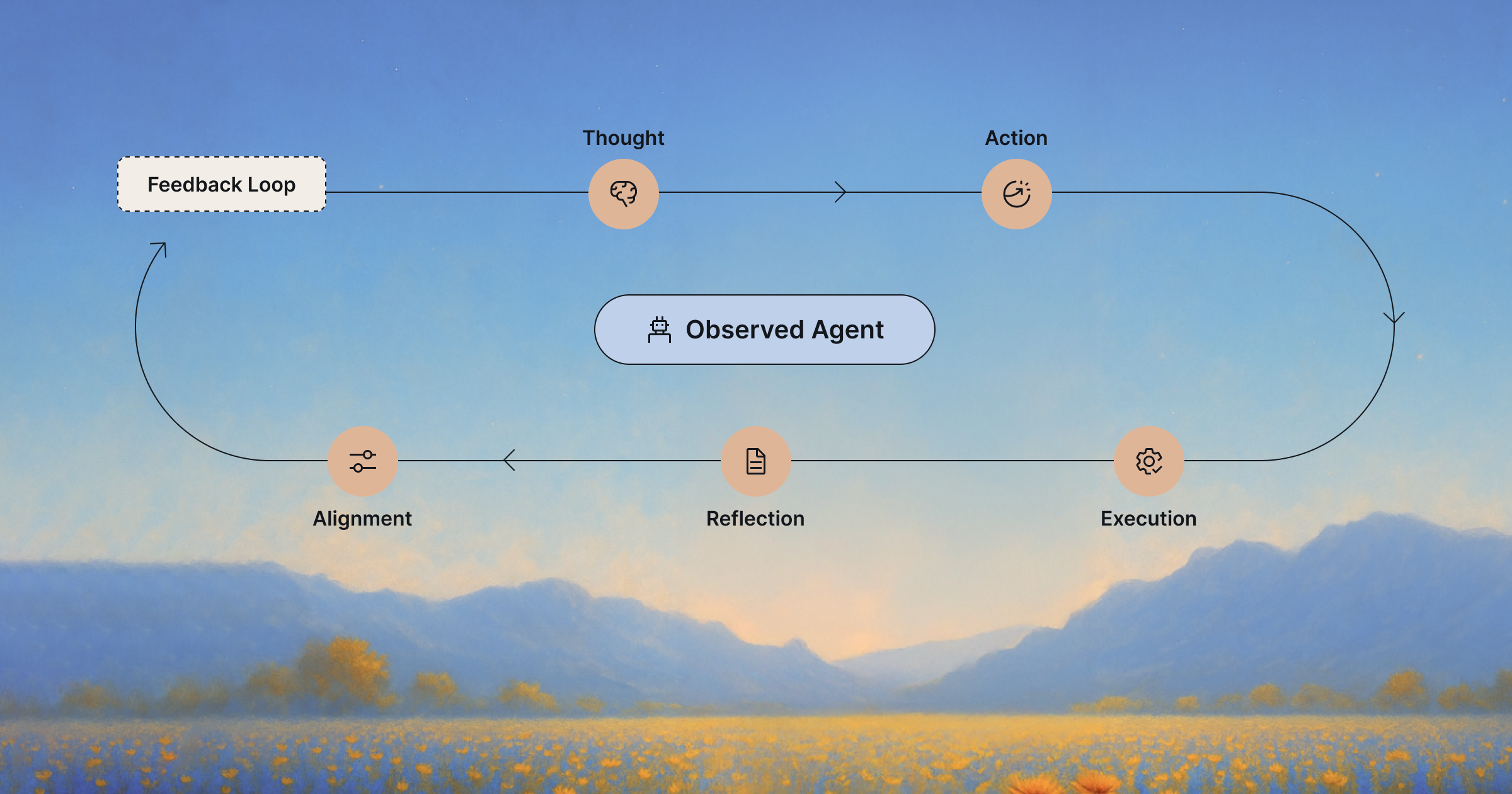
Anatomy of an Agent: Observing the Full Lifecycle of AI Agents
Learn more
Browse by categories
Bias and Fairness in AI
Community
Company
Culture
Data Science
Engineering
Explainable AI
Generative AI and LLMOps
MLOps
Model Monitoring
Product
Responsible AI
Use Case
Search
Krishna Gade, Kirti Dewan, Karen He
Anatomy of an Agent: Observing the Full Lifecycle of AI Agents
Generative AI and LLMOps
Fiddler Team
A Complete Guide to Machine Learning Model Lifecycle Management
MLOps
Fiddler Team
Navigating AI Compliance and Risk Management
Responsible AI
Krishna Gade, Kirti Dewan, Karen He
Agentic Observability Starts in Development: Build Reliable Agentic Systems
Generative AI and LLMOps
Segio Ferragut, Karen He, Danny Brock
Proactive Drift and Data Quality Monitoring for Tecton Feature Views with Fiddler
MLOps
Model Monitoring
Fiddler Team
Maximizing AI Guardrails Velocity: Fast, Secure Innovation at Scale
Generative AI and LLMOps
Cole Martin
Fiddler Enhances Agentic AI Security with NVIDIA Enterprise AI Factory Integration
Product
Segio Ferragut, Karen He, Danny Brock
Preventing Model Decay: Tecton + Fiddler for ML Drift Detection
MLOps
Model Monitoring
Explainable AI
Cole Martin
Fiddler is Selected for DoD’s APFIT Award to Accelerate Mission-Critical AI
MLOps
Model Monitoring
Explainable AI
Fiddler Team
Why AI Security is Critical for Enterprise Organizations
Generative AI and LLMOps
Fiddler Team
Evaluating the ROI of AI Explainability Tools
Explainable AI
Fiddler Team
How to Avoid LLM Security Risks
Generative AI and LLMOps
Cole Martin
Developing Agentic AI Workflows with Safety and Accuracy
Generative AI and LLMOps
Karen He
Fiddler Guardrails Now Native to NVIDIA NeMo Guardrails
Product
Cole Martin
Harnessing Generative AI for Healthcare Innovation
Generative AI and LLMOps
Use Case
Krishna Gade
Maria Martinez Joins Fiddler AI Board: Bringing Operational Excellence and Customer-Driven Innovation
Company
Karen He and William Han
Introducing Fiddler Guardrails: Safeguarding LLM Applications from Safety and Security Risks
Product
Generative AI and LLMOps
Gabriel Atkin and Karen He
Deploying Safe and Trustworthy LLM Applications at Scale with Fiddler and NVIDIA NeMo Guardrails
Product
Generative AI and LLMOps
Cole Martin
AI Governance in the Age of Generative AI
Generative AI and LLMOps
Responsible AI
Krishna Gade and Amit Paka
Fiddler AI Raises Series B Prime with New Partners to Expand Enterprise AI Observability and AI Safety
Company
Karen He, Sabina Cartacio, and Chris Lambert
Fiddler Delivers Native Enterprise-Grade AI Observability to Amazon SageMaker AI Customers
Product
Yuriy Pavlish and Karen He
Deploying Enterprise LLM Applications with Inference, Guardrails, and Observability
Responsible AI
Generative AI and LLMOps
Rajesh Hegde
Advanced Pytest Patterns: Harnessing the Power of Parametrization and Factory Methods
Engineering
Karen He
Fiddler AI Observability Now on Google Cloud Marketplace
Product
Next
Subscribe to our newsletter
Monthly curated AI content, Fiddler updates, and more.