Fiddler Centor Models
Fast, Free, and Secure Models for Evals and Guardrails
Fiddler Centor Models (formerly known as Fiddler Trust Models) are cost-effective and secure models integral to the Fiddler AI Control Plane. They power the industry's fastest guardrails and evaluations across the full lifecycle. They run securely without data leaving the environment. Whether your evaluations need low-latency or complex reasoning with accuracy, Centor Models keep your evaluation TCO low as traffic scales. As the models are built into the Fiddler solution, there are no API call costs that an enterprise would incur as in the case of calling external LLMs.
Teams can also bring their own judges (BYOJ) into Fiddler and use their preferred LLMs as evaluators alongside Centor Models. This enables full flexibility to fit the evaluator to your use case.
At a Glance

Powering Continuous Evaluation and Policy Enforcement
Flexible Evals for Every Use Case
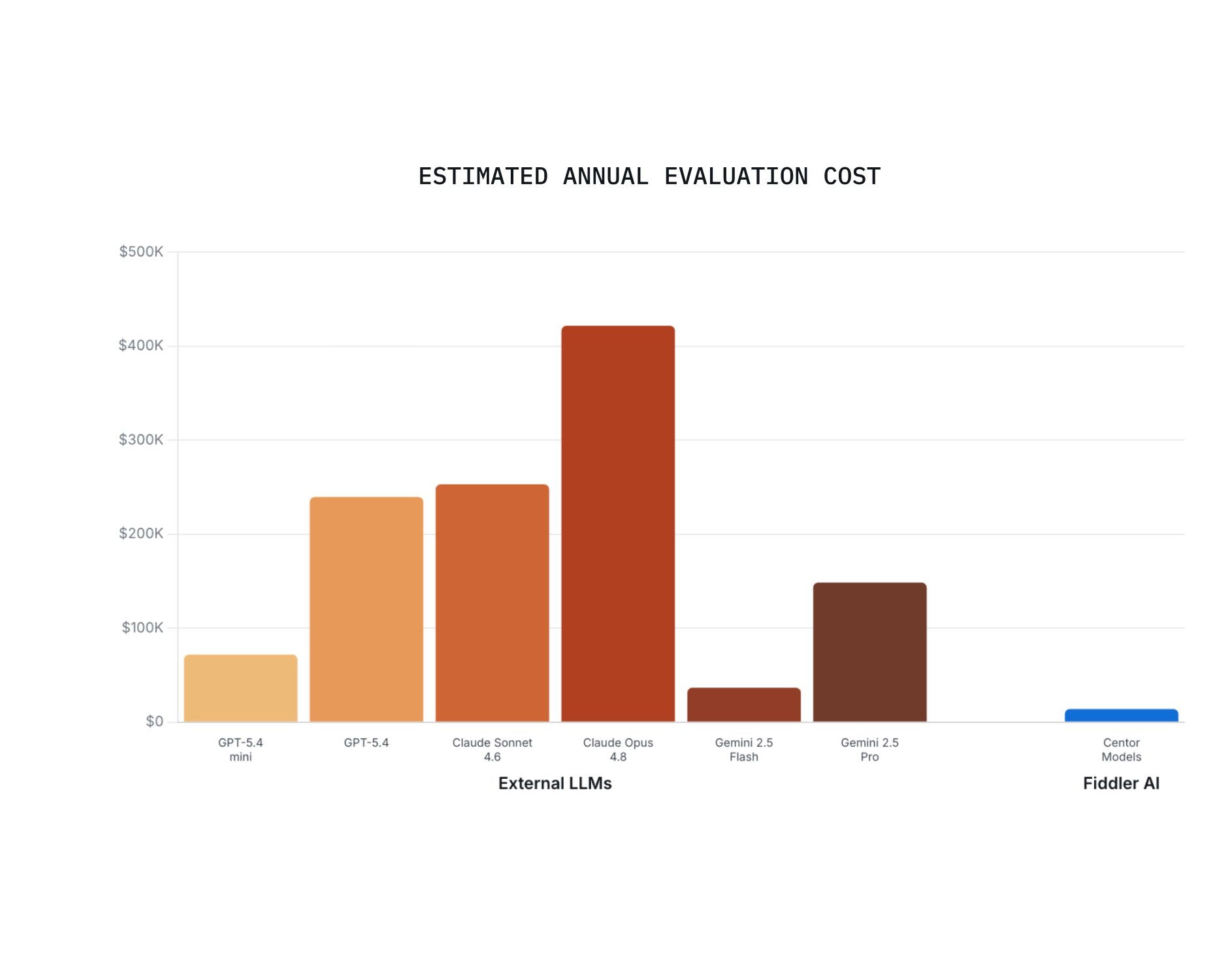
Most observability platforms evaluate agent traces by sending each one to an external LLM (OpenAI, Anthropic, etc.) to act as a judge. That’s a hidden cost that shows up on your foundation model provider’s bill, and it’s called the Evaluation Trust Tax.
- Run 80+ secure, out-of-the-box evaluators for fast and task-specific use cases.
- Customize evaluators in your environment for domain-specific or unique projects.
- Bring your own judge (BYOJ) into Fiddler to evaluate with your preferred model.
- Centor Models cost up to 98% less than external LLM judges that sample just 10% of traces, and the gap widens as your deployment grows.
Enforce Policies in Real-Time
- Block risky prompts and responses in real time with configurable policy enforcement.
- Customize policy thresholds to match your organization's risk standards.
- Catch hallucinations, toxicity, safety violations, and prompt injection attacks before they reach your users.
With Centor Models, You Eliminate:
Featured Resources
Frequently Asked Questions
What are Fiddler Centor Models?
Centor Models are secure, cost-effective AI evaluation models that are integral to the Fiddler AI Control Plane. They enable agents and LLM applications that require low-latency evaluations for agent and LLM outputs for safety, accuracy, and compliance or complex reasoning with accuracy evaluations directly in your environment, with no external API calls. Think of them as batteries-included evaluation: they work out of the box, return results in under 80ms, and don't add a line item to your LLM provider's invoice.
What do Centor Models evaluate?
Centor Models provide 80+ out of the box and customizable metrics. They support low latency and task specific use cases and complex reasoning with accuracy projects. Out of the box metrics include: hallucination and faithfulness, jailbreak detection, toxicity, safety (harassing, harmful, hateful, illegal, racist, sexist, sexual, unethical, violent), and sensitive information detection including 35+ PII entity types and healthcare-specific entities for HIPAA compliance. You get full coverage without building or maintaining your own evaluation prompts.
How do Centor Models compare to external LLM evaluation calls?
LLM-as-a-Judge is a common evaluation technique that uses general-purpose models like GPT-4 to score AI outputs. The costs of evaluating traces using external LLMs can add up quickly as they are charged per call by the LLM provider. Unlike external LLMs, Centor Models run inside your environment and do not have per-evaluation costs. Centor Models cover 100% of traces and do not sample by default. Centor Models are up to 98% cheaper to run compared to external LLMs and the cost difference increases as agent traffic grows.
Can I use Centor Models alongside my own custom evaluations?
Yes. Centor Models deliver out of the box and customizable evaluation metrics, and you can bring your own judges (BYOJ) alongside them. The platform supports both, so you're not locked into a single approach.
Why does the AI Trust Tax exist?
Most AI observability and evaluation platforms weren't built to run inside your environment. They route evaluation calls through external LLM APIs, which means every metric evaluated generates a new API call. The costs of those calls show up in a separate bill from your foundation model provider, not from your AI observability vendor.
How do you eliminate the Evals Trust Tax?
The Evals Trust Tax disappears when evaluation runs inside your environment with no external API calls. That requires purpose-built, task-specific models deployed alongside your AI applications, not hosted by a third party and billed per call.
Fiddler Centor Models are batteries-included. They run in your environment, cover hallucination, safety, PII/PHI detection, toxicity, and jailbreak detection out of the box, and return results in under 80ms.