
We’ve seen a tremendous uptick in enterprises adopting Large Language Models (LLMs) to power various knowledge reasoning applications like workplace assistants and chatbots over the past year. These applications range from product documentation to customer service to help end-users increase productivity, streamline automation, and make better decisions. Enterprises can launch their LLMs using 4 different LLM deployment methods depending on the nature of their business use case and are increasingly choosing retrieval-augmented generation (RAG)-based LLM applications, as it’s an efficient and cost-effective deployment method.
RAG enables AI teams to build applications on top of existing open-source LLMs or LLMs provided by the likes of OpenAI, Cohere, or Anthropic. Additionally, with RAG, enterprises can process time-sensitive and private information not possible with foundation models alone.
We’re excited to announce a partnership that enables enterprises and startups to put accurate, RAG applications in production more quickly with DataStax Astra DB and the Fiddler AI Observability platform.
Why DataStax and Fiddler AI together?
Enterprises and smaller organizations need LLM observability to meet accuracy and control requirements for putting RAG applications into production. Here are some reasons:
- Enterprise-level requirements: Cost, data privacy, and lack of control will still push enterprises to host their own data in a vector database.
- Evolving complexities in LLMs: Building with LLMs is no longer just a simple LLM call and getting back a text completion. These LLM APIs will now involve complex components like retrievers, threads, prompt chains, and access to tools — all of which need to be logged and monitored.
- LLM deployment method selection: Prompt engineering, RAG, and fine-tuning can all be leveraged, but which one to use and when to use it depends on the task at hand. Enterprises might take different approaches based on whether the LLM application they are building is internal or external. What is the risk vs reward tradeoff?
- Continuous LLM monitoring: Lastly, evaluation is still pretty hard! Regardless of how you use and apply LLMs, it won’t matter much if you are not consistently evaluating performance. With many changes on the horizon, customers should always continue with LLM monitoring after they launch their AI application.
In short, getting started with RAG applications can be done in minutes. However, as the enterprise consumers of these applications demand more accuracy, safety, and transparency from these business-critical applications, enterprises will naturally gravitate toward the stack that provides the most control and deep feature set required.
A Simple Recipe for Deploying RAG-based LLM Applications
What’s been so surprising about the proliferation of LLM-based applications over the past year is how powerful they are proving to be for a variety of knowledge reasoning tasks, while, at the same time, proving extremely simple architecturally. The benefits of RAG-based LLM applications have been well-understood for some time now.
To build these “reasoning applications” only requires a few key ingredients:
- A LLM foundation model
- Documents stored in a vector database for retrieval
- A LLM observability layer to tune the system, detect issues, and ensure proper performance
- LangChain or a LlamaIndex toolkit to orchestrate the workflow and data movement
Yet, as with any recipe, the final product is only as good as the quality of the ingredients we choose.
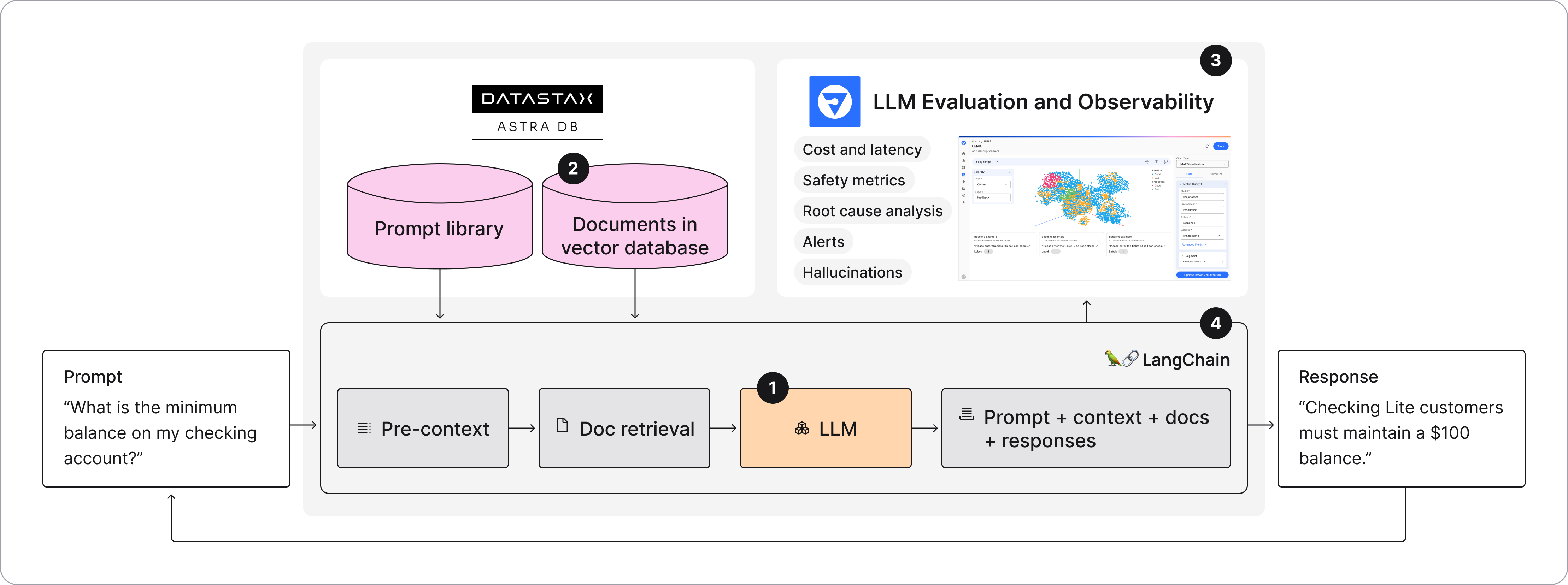
The Best-of-Breed RAG Ingredients
DataStax Astra DB
Astra DB is a Database-as-a-Service (DBaaS) that enables vector search and gives you the real-time vector and non-vector data to quickly build accurate generative AI applications and deploy them in production. Built on Apache Cassandra®, Astra DB adds real-time vector capabilities that can scale to billions of vectors and embeddings; as such, it’s a critical component in a GenAI application architecture. Real-time data reads, writes, and availability are critical to prevent AI hallucinations. As a serverless, distributed database, Astra DB supports replication over a wide geographic area, supporting extremely high availability. When ease-of-use and relevance at scale matter, Astra DB is the vector database of choice.
The Fiddler AI Observability Platform
The Fiddler AI Observability platform helps customers address the concerns surrounding generative AI. Whether AI teams are launching AI applications using open source, in-house-built LLMs, or closed LLMs provided by OpenAI, Anthropic, or Cohere, Fiddler equips users across the organization with an end-to-end LLMOps experience, from pre-production to production. With Fiddler, users can validate, monitor, analyze, and improve RAG applications. The platform offers many out-of-the-box enrichments that produce metrics to identify safety and privacy issues like toxicity and PII-leakage as well as correctness metrics like faithfulness and hallucinations.

Use Case: The Fiddler AI Documentation Chatbot
Fiddler built an AI chatbot for our documentation site to help improve the customer experience of the Fiddler AI Observability platform. The chatbot answers queries for using Fiddler for ML and LLM monitoring.
Fiddler chose Astra DB as the chatbot’s vector database and was able to quickly set up an environment that had immediate access to multiple API endpoints. Using Astra’s Python libraries, Fiddler stored prompt history along with the embeddings for the documents in their data set. Key benefits were realized right away and we continue to monitor and improve our chatbot.
- After publishing the chatbot conversations to the Fiddler platform, chatbot performance is analyzed along with multiple key metrics; including cost, hallucinations, correctness, toxicity, data drift, and more.
- The Fiddler platform offers out-of-the-box dashboards that use multiple visualizations to track the chatbot performance over time under different load scenarios and compares responses with different cohorts of users.
- Fiddler LLM Observability also allows the chatbot operators to conduct root cause analysis when issues are detected.
You can learn more about Fiddler’s experience of developing this chatbot at the recent AI Forward 2023 Summit session Chat on Chatbots: Tips and Tricks. You can also request a demo of the Fiddler AI Observability platform for for ML and LLMOps.
