With the rapid pace of LLM innovations, enterprises are actively exploring use cases and deploying their first generative AI applications into production. As the deployment of LLMs or LLMOps began in earnest this year, enterprises have incorporated four types of LLM deployment methods, contingent on a mix of their own talent, tools and capital investment. Bear in mind these deployment approaches will keep evolving as new LLM optimizations and tooling are launched regularly.
The goal of this post is to walk through these approaches and talk about the decisions behind these design choices.
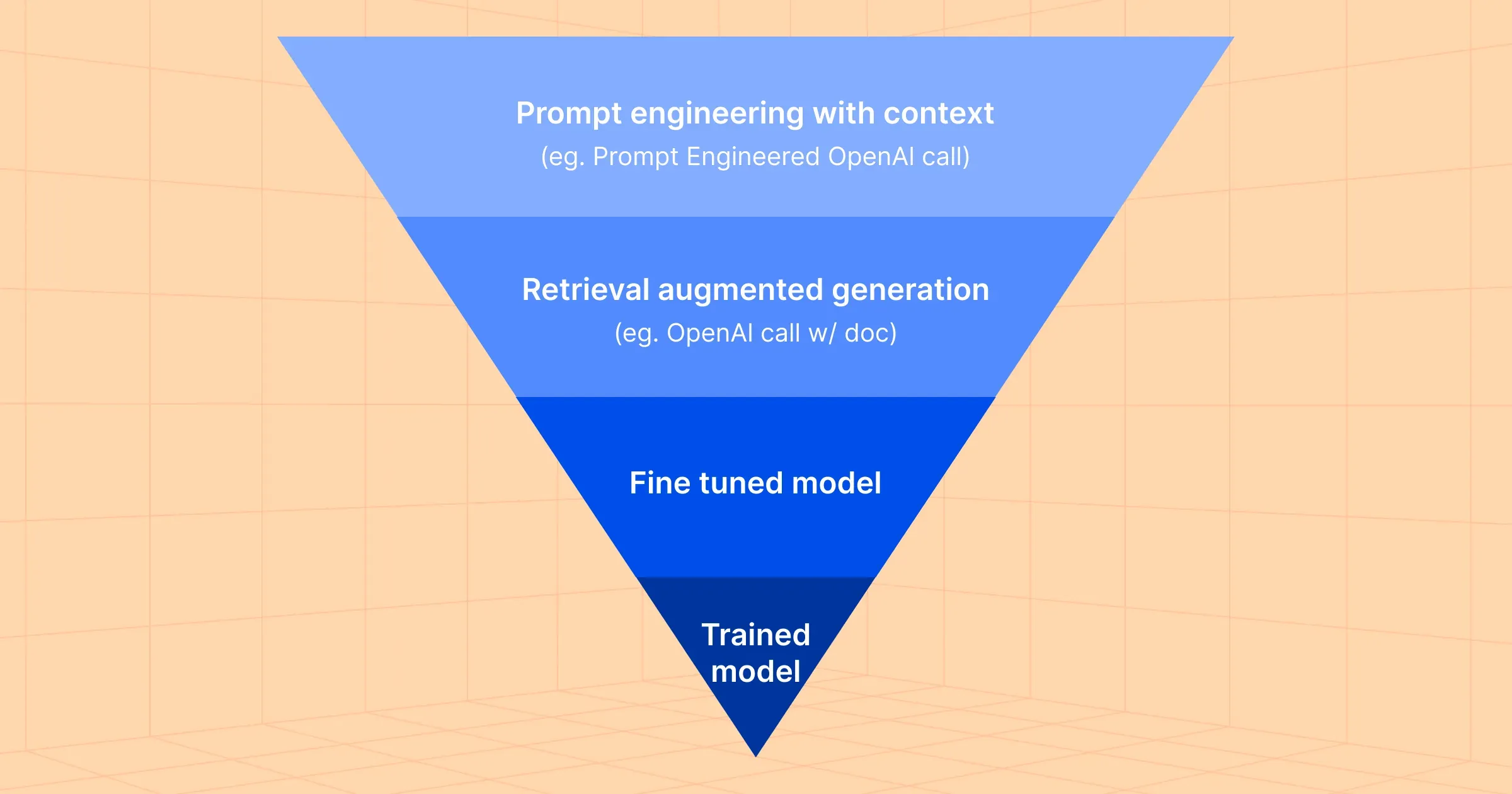
Four approaches to LLMs in Production

There are four different approaches that enterprises are taking to jumpstart their LLM journey. These four approaches range from easy and cheap to difficult and expensive to deploy, and enterprises should assess their AI maturity, model selection (open vs. closed), data available, use cases, and investment resources when choosing the approach that works for their company’s AI strategy. Let’s dive in.
1. Prompt Engineering with Context
Many enterprises will begin their LLM journey with this approach since it’s the most cost effective and time efficient. This involves directly calling third party AI providers like OpenAI, Cohere or Anthropic with a prompt. However, given that these are generalized LLMs, they might not respond to a question unless it’s framed in a specific way or elicit the right response unless it’s guided with some more direction. Building these prompts, also called “Prompt Engineering”, involves creative writing skills and multiple iterations to get the best response.
The prompt can also include examples to help guide the LLM. These examples are included before the prompt itself and called “Context”. “One shot” and “Few shot” prompting is when the users introduce examples in the context.
Here’s an example:

Since it is as easy as calling an API, this is the most common approach for enterprises to jumpstart their LLM journey, and might well be sufficient for many lacking in AI expertise and resources. This approach works well for generalized natural language use cases but could get expensive if there is heavy traffic into a third party proprietary AI provider.
2. Retrieval Augmented Generation (RAG)
Foundation models are trained with general domain corpora, making them less effective in generating domain-specific responses. As a result, enterprises will want to deploy LLMs on their own data to unlock use cases in their domain (e.g. customer chatbots on documentation and support, internal chatbots on IT instructions, etc), or generate responses that are up-to-date or using non-public information. However, many times there might be insufficient instructions (hundreds or a few thousands) to justify fine tuning a model, let alone training a new one.
In this case, enterprises can use RAG to augment prompts by using external data in the form of one or more documents or chunks of them, and is then passed as context in the prompt so the LLM can correctly respond with that information. Before the data gets passed as context, it needs to be retrieved from an internal store. In order to determine what data to retrieve for the prompt, both the prompt and document, which is typically chunked to meet token requirements and to make it easier to search, are converted into embeddings and a similarity score is determined. Finally, the prompt query is assembled and sent to the LLM. Vector databases like Pinecone and LLM metadata tooling like LlamaIndex are emerging tools that support the RAG approach.
In addition to saving time on finetuning, this knowledge retrieval technique reduces the chance of hallucinations since the data is passed in the prompt itself rather than relying on the LLM’s internal knowledge. Enterprises, however, need to be mindful that knowledge retrieval is not bulletproof to hallucinations because the correctness of an LLM generation will heavily rely on the quality of information passed through and the retrieval techniques used. Another consideration to be aware of is that sending the data (especially proprietary data) in the call increases data privacy risks since it’s been reported that foundation models can memorize data that’s passed through, and increases the token window which increases cost and latency of each call.
3. Fine Tuned Model
While prompt engineering and RAG can be a good option for some enterprise use cases, we also reviewed their shortcomings. As the amount of enterprise data and the criticality of the use case increases, fine tuning an LLM offers a better ROI.
When you fine tune, the LLM absorbs your fine tuning dataset knowledge into the model itself, updating its weights. So, once the LLM is finetuned, you no longer have to send examples or other information in the context of a prompt. This approach lowers costs, reduces privacy risks, avoids token size constraints, and provides better latency. Because the model has absorbed the entire context of your fine tune data, the quality of the responses is also higher with a higher degree of generalization.
Though fine tuning provides good value if you have a larger number of instructions (typically in tens of thousands), it can be resource intensive and time consuming. Aside from fine tuning, you’ll also need to spend time compiling a fine tuned data set in the right format for tuning. Services like AWS Bedrock and others are making it easy to fine tune an LLM.
4. Trained Model
If you have a domain specific use case and a large amount of domain centric data, then training an LLM from scratch can provide the highest quality LLM. This approach is by far the most difficult and expensive to adopt. The diagram below from Andrej Karpathy at Microsoft Build offers a good explanation of the complexity in building an LLM from scratch. BloombergGPT, for example, was the first financial model LLM. It was trained on forty years of financial language data for a total dataset of 700 billion tokens.

Enterprises need to be aware of costs related to training LLMs from scratch since they require large amounts of compute that can add up costs very quickly. Depending on the amount of training required, compute costs can range from a few hundreds of thousands to a few million dollars. For example, Meta’s first 65B LLaMa model training took 1,022,362 hours on 2048 NVidia A100-80GB’s (about $4/hr on cloud platforms) costing approximately $4M. However, the training cost is coming down rapidly with examples like Replit’s code LLM and MosaicML’s foundation models costing only a few hundreds of thousands.
As the LLMOps infrastructure evolves with more advanced tools, like Fiddler’s AI Observability platform, and methods, we will see more enterprises adopting LLM deployment options that yield higher quality LLMs at a more economical cost and with a faster time to market.
Fiddler helps enterprises standardize LLMOps with LLM and prompt robustness testing in pre-production using Fiddler Auditor, the open-source robustness library for red-teaming of LLMs, and embeddings monitoring in production. Contact our AI experts to learn how enterprises are accelerating LLMOps with Fiddler AI Observability.