We're thrilled to announce the launch of Fiddler Auditor, an open source tool designed to evaluate the robustness of Large Language Models (LLMs) and Natural Language Processing (NLP) models. As the NLP community continues to leverage LLMs for many compelling applications, ensuring the reliability and resilience of these models and addressing the underlying risks and concerns is paramount1-4. It’s known that LLMs can hallucinate5-6, generate adversarial responses that can harm users7, exhibit different types of biases1,8,9, and even expose private information that they were trained on when prompted or unprompted10,11. It's more critical than ever for ML and software application teams to minimize these risks and weaknesses before launching LLMs and NLP models12.
The Auditor helps users test model robustness13 with adversarial examples, out-of-distribution inputs, and linguistic variations, to help developers and researchers identify potential weaknesses and improve the performance of their LLMs and NLP solutions. Let’s dive into the Auditor’s capabilities, and learn how you can contribute to making AI applications safer, more reliable, and more accessible than ever before.

How It Works
The Auditor brings a unique approach to assessing the dependability of your LLMs and NLP models by generating sample data that consists of small perturbations to the user's input for NLP tasks or prompts for LLMs. The Auditor then compares the model’s output over each perturbed input to the expected model output, carefully analyzing the model's responses to these subtle variations. The Auditor assigns a robustness score to each prompt after measuring the similarity between the model's outputs and the expected outcomes. Under the hood, the Auditor builds on the extensive research on measuring and improving robustness in NLP models14-21, and in fact, leverages LLMs themselves as part of the generation of perturbed inputs and the similarity computation.
By generating perturbed data and comparing the model’s outputs over perturbed inputs to expected model outputs, the Auditor provides invaluable insights into a model's resilience against various linguistic challenges. LLMOps teams can further analyze those insights from a comprehensive test report upon completion. This helps data scientists, app developers, and AI researchers identify potential vulnerabilities and fortify their models against a wide range of linguistic challenges, ensuring more reliable and trustworthy AI applications.
Evaluating Correctness and Robustness of LLMs
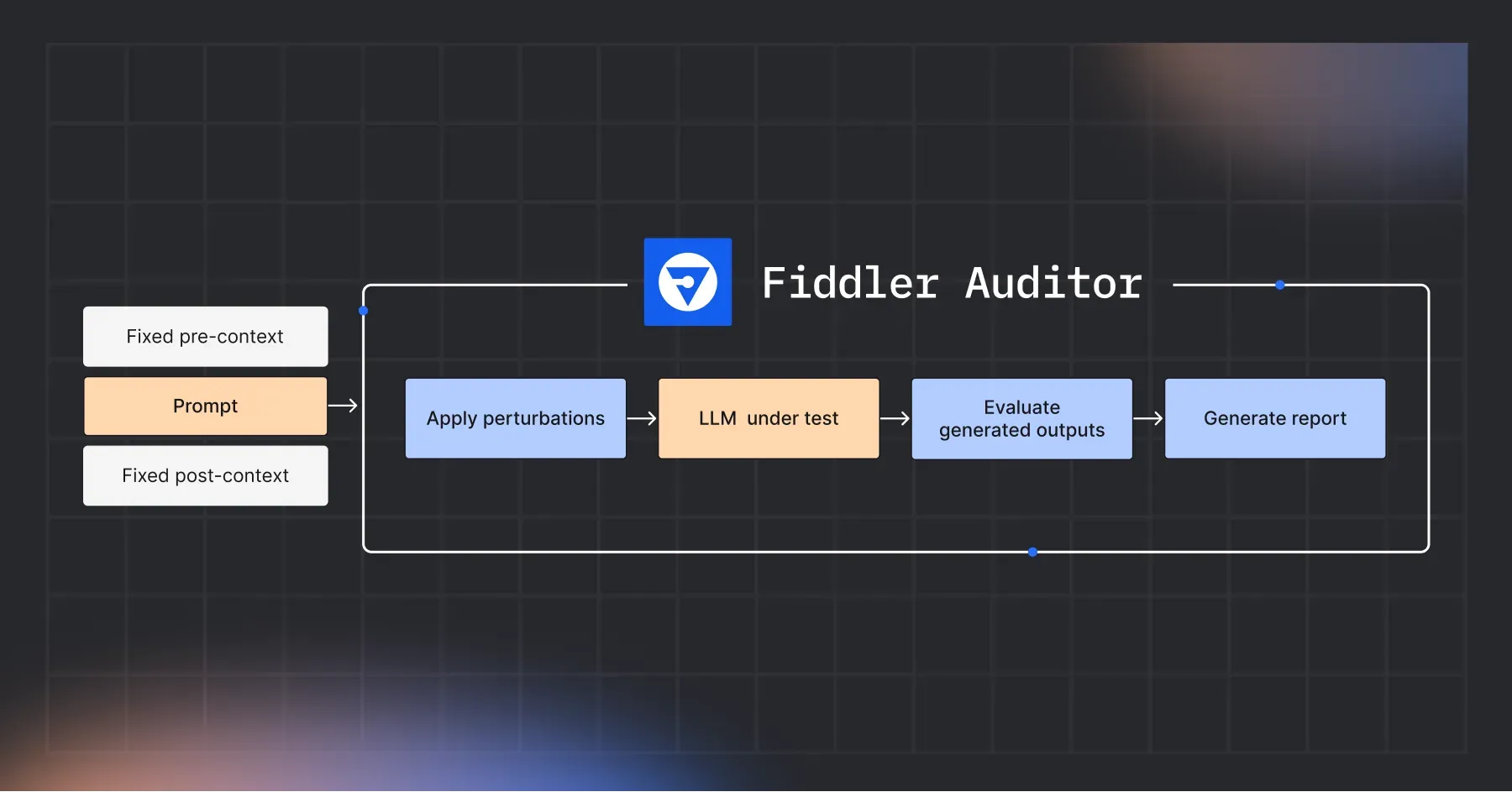
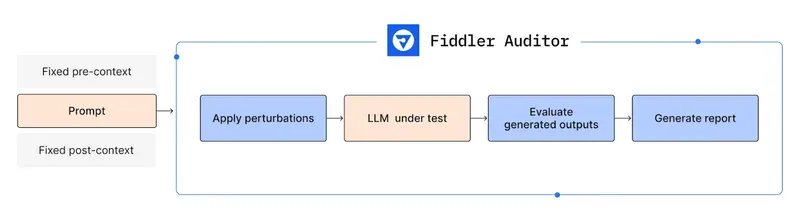
Given an LLM and a prompt that needs to be evaluated, Fiddler Auditor carries out the following steps (shown in Figure 1):
- Apply perturbations: This is done with the help of another LLM that paraphrases the original prompt but preserves the semantic meaning. The original prompt along with the perturbations are then passed onto the LLM to be evaluated.
- Evaluate generated outputs: The generations are then evaluated for either correctness (if a reference generation is provided) or robustness (in terms of how similar are the generated outputs, in case no reference generation is provided). For convenience, the Auditor comes with built-in evaluation methods like semantic similarity. Additionally, you can define your own evaluation strategy.
- Reporting: The results are then aggregated and errors highlighted.
Currently, an ML practitioner can evaluate LLMs from OpenAI, Anthropic, and Cohere using the Fiddler Auditor and identify areas to improve correctness and robustness, so that they can further refine the model. In the example below, we tested OpenAI’s test-davinci-003 model with the following prompt and the best output it should generate when prompted:

Then, we entered five perturbations with linguistic variations, and only one of them generated the desired output as seen in the report below. If the LLM were released for public use as is, users would lose trust in it since the model generates hallucinations for simple paraphrasing, and users could potentially be harmed by this particular output had they acted on the output generated.

You can start using Fiddler Auditor by visiting the GitHub repository; get access to detailed examples and quick-start guides, including how to define your own custom evaluation metrics.
We invite you to provide feedback and contribute to Fiddler Auditor, and give it a star if you like using it! ⭐
References
- Emily M. Bender, Timnit Gebru, Angelina McMillan-Major, Shmargaret Shmitchell, On the Dangers of Stochastic Parrots: Can Language Models be Too Big? FAccT 2021
- Rishi Bommasani et al., On the Opportunities and Risks of Foundation Models, Stanford Center for Research on Foundation Models (CRFM) Report, 2021.
- Mary Reagan, Not All Rainbows and Sunshine: The Darker Side of ChatGPT, Towards Data Science, January 2023
- Mary Reagan, Krishnaram Kenthapadi, GPT-4 and the Next Frontier of Generative AI | Fiddler AI Blog, March 2023
- Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung, Survey of Hallucination in Natural Language Generation, ACM Computing Surveys, Volume 55, Issue 12, 2023
- https://en.wikipedia.org/wiki/Hallucination_(artificial_intelligence)
- Kevin Roose, Bing’s A.I. Chat: ‘I Want to Be Alive, New York Times, February 2023
- Li Lucy, David Bamman, Gender and Representation Bias in GPT-3 Generated Stories, ACL Workshop on Narrative Understanding, 2021
- Andrew Myers, Rooting Out Anti-Muslim Bias in Popular Language Model GPT-3, Stanford HAI News, 2021
- Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert-Voss, Katherine Lee, Adam Roberts, Tom Brown, Dawn Song, Ulfar Erlingsson, Alina Oprea, Colin Raffel, Extracting Training Data from Large Language Models, USENIX Security Symposium, 2021
- Martin Anderson, Retrieving Real-World Email Addresses From Pretrained Natural Language Models, Unite.AI, 2022
- Amit Paka, Krishna Gade, Krishnaram Kenthapadi, The Missing Link in Generative AI, Fiddler AI Blog, April 2023
- Amal Iyer, Expect The Unexpected: The Importance of Model Robustness | Fiddler AI Blog, February 2023
- Xuezhi Wang, Haohan Wang, Diyi Yang, Measure and Improve Robustness in NLP Models: A Survey, NAACL 2022
- Kai-Wei Chang, He He, Robin Jia, Sameer Singh, Tutorial on Robust NLP, EMNLP 2021
- Marco Tulio Ribeiro, Tongshuang Wu, Carlos Guestrin, Sameer Singh, Beyond Accuracy: Behavioral Testing of NLP models with CheckList, ACL 2020
- John X. Morris, Eli Lifland, Jin Yong Yoo, Jake Grigsby, Di Jin, Yanjun Qi, TextAttack: A Framework for Adversarial Attacks, Data Augmentation, and Adversarial Training in NLP, EMNLP 2020 (System Demonstrations)
- Xinhsuai Dong, Luu Anh Tuan, Min Lin, Shuicheng Yan, Hanwang Zhang, How Should Pre-Trained Language Models Be Fine-Tuned Towards Adversarial Robustness?, NeurIPS 2021
- Muhammad Bilal Zafar, Michele Donini, Dylan Slack, Cédric Archambeau, Sanjiv Das, Krishnaram Kenthapadi, On the Lack of Robust Interpretability of Neural Text Classifiers, ACL Findings, 2021
- Tongshuang Wu, Marco Tulio Ribeiro, Jeffrey Heer, Daniel S. Weld, Polyjuice: Generating Counterfactuals for Explaining, Evaluating, and Improving Models, ACL 2021
- Marco Tulio Ribeiro, Scott Lundberg, Adaptive Testing and Debugging of NLP Models, ACL 2022