Fiddler AI vs. Other AI Observability Platforms
AI Observability looks different at enterprise scale. As AI deployments grow beyond pilots, total cost of ownership (TCO), enterprise readiness gaps, and governance become impossible to ignore.
Other platforms require costly external API calls for scoring, moderation and guardrail checks. Fiddler’s batteries-included Centor Models run securely in your environment for $0.
Fiddler delivers the robust scalability world-class enterprises demand, with the monitoring and security they require.
Stop chasing logs. Fiddler generates the comprehensive evidence your GRC teams need to approve and scale your AI portfolio.

The Real Cost of AI Observability
Most AI observability platforms rely on external LLMs for evaluation and scoring. Using external LLMs you face:
Risk Gaps: Down-sampling means you could miss the events that matter most, creating governance risks.
Operational Overhead: Without built-in models, the evaluation burden falls on your team to own hosting, model selection, calibration, and prompt versioning.
The Evals Trust Tax: Every metric you evaluate adds to your total cost of ownership and the trust tax grows as your evaluation needs expand.
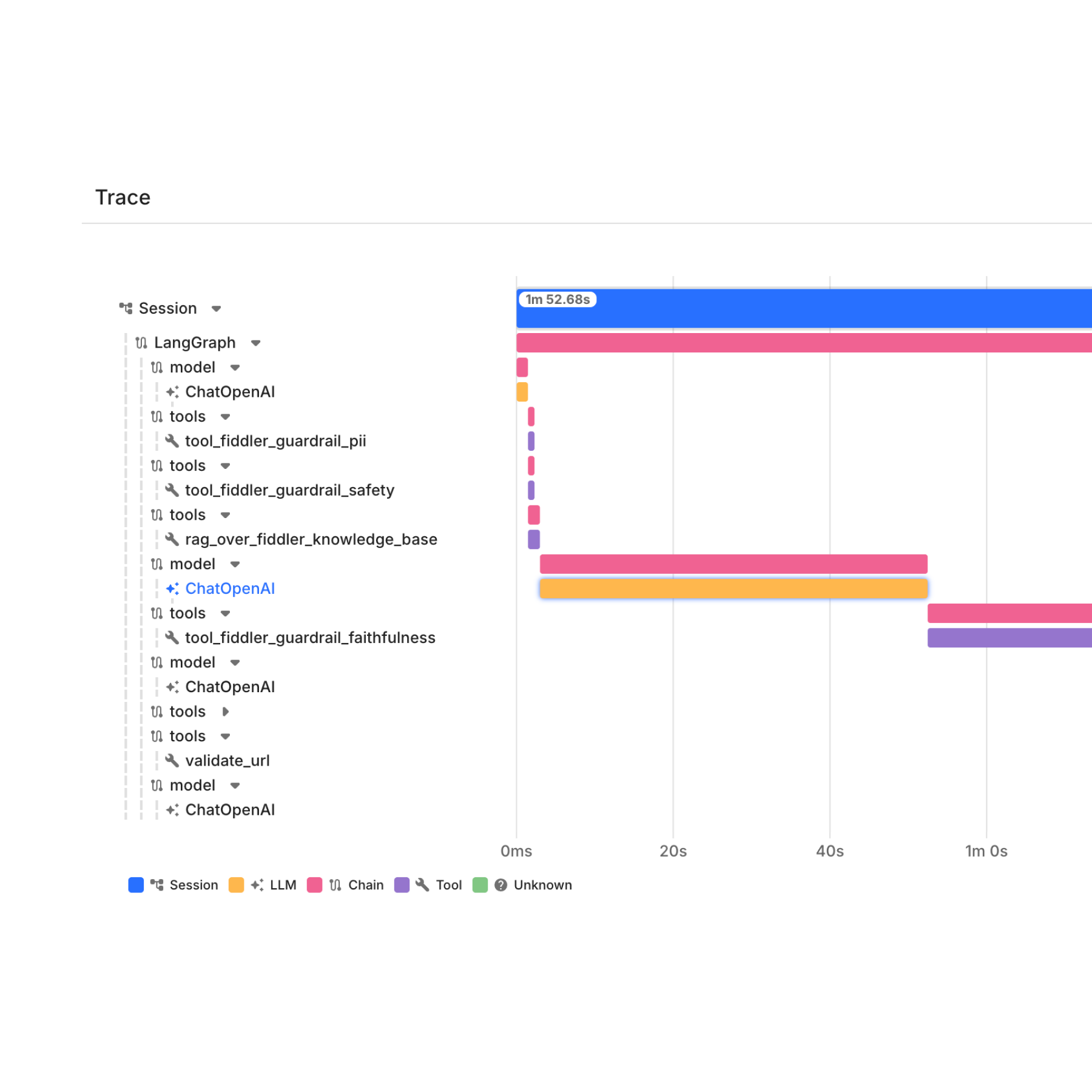
Built for Multi-Agent Systems at Scale
Span-level traces and manual root cause analysis can't keep pace with the complexity of multi-agent systems at scale.
Full, hierarchical visibility across from session to agent to trace to span.
Automated RCA with full decision context across the agentic hierarchy.
Purpose-built for global conglomerate scale of 30 million+ events per day.
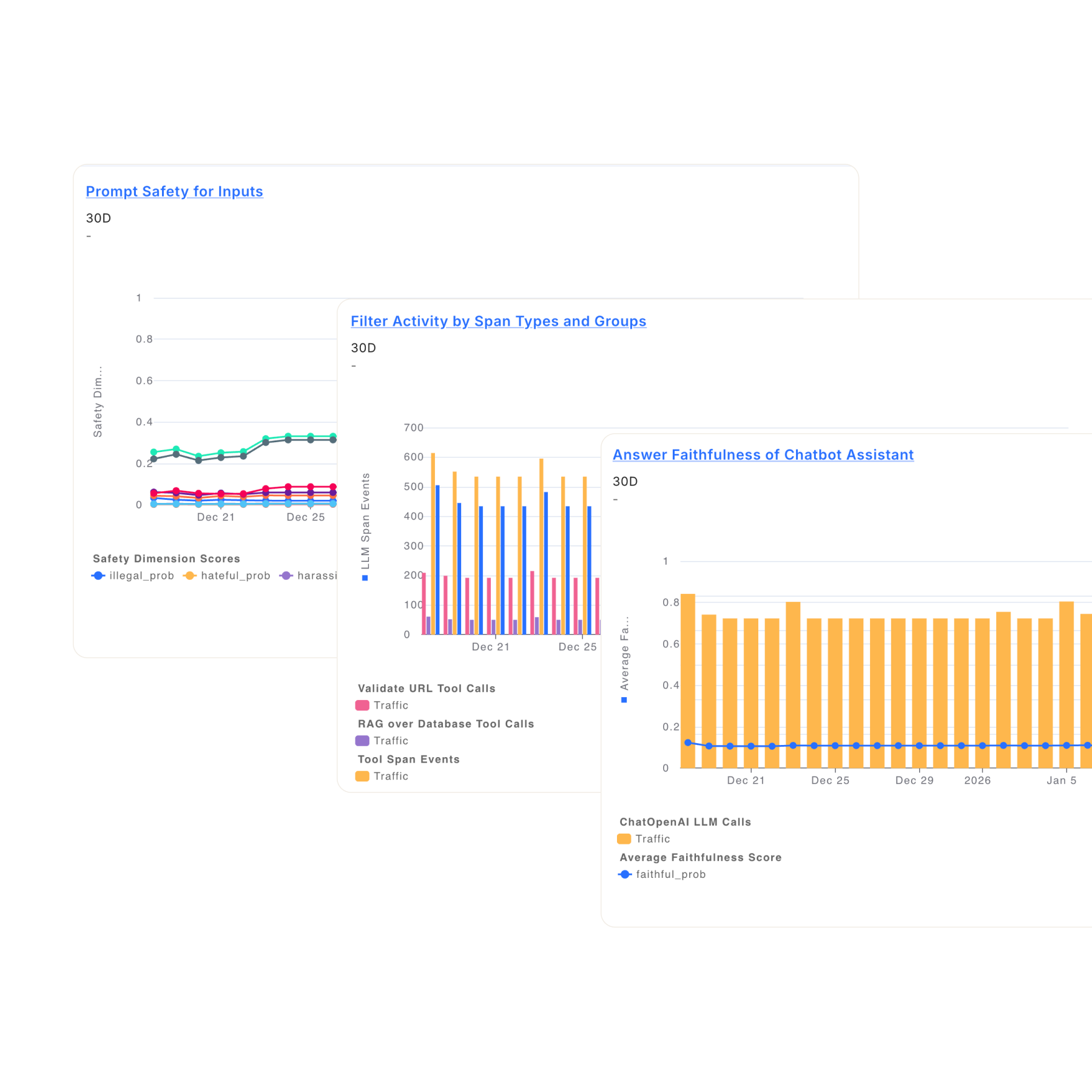
Enterprise-Ready Governance, Risk Management, and Compliance (GRC)
Fiddler provides a single pane of glass across your entire AI portfolio, with centralized governance, complete audit evidence, and executive oversight.
Generate audit evidence aligned with GDPR, HIPAA, NAIC, SR 11-7, and other regulatory requirements.
Manage all agents from a unified executive dashboard connecting AI behavior and performance to business KPIs.
Record every decision, action, and policy outcome with full traceability.
Fiddler vs. Other AI Observability Platforms
Span-level traces tell you what a model produced. They don't tell you why an agent made a specific decision, how a failure propagated across a multi-agent session, or where in the agentic hierarchy a problem originated.
External LLM-as-a-Judge with sampling; unpredictable costs, latency, data exposure risk
Native, in-environment Centor Models; 100% coverage at predictable cost; flexible evaluation options
Sessions and spans only; no aggregated visibility
Visualized agentic hierarchy: Application → session → agent → trace → span
Manual; requires sifting through thousands of logs
Automated RCA with full decision context and agentic hierarchy
Absent
<80ms purpose-built guardrails for hallucinations, toxicity, PII, and more
Fragmented GRC; lacks stakeholder reporting and portfolio-wide risk insights
Built for governance, audit trails, and compliance evidence across all AI deployments
Limited enterprise scale readiness
Proven scalability success with Fortune 20 conglomerate at 30 million+ traces per day


