The success of AI initiatives depends on more than just building high-performing machine learning (ML) models; it requires rigorous end-to-end lifecycle management. Machine learning model lifecycle management spans every phase of a model's journey, from initial development through deployment and ongoing optimization.
As organizations scale their AI operations, effectively managing this lifecycle becomes essential. Without the right frameworks, even the most sophisticated models can quickly become obsolete, underperform, or fail to meet compliance standards.
In this guide, we'll break down each stage of the ML lifecycle, share proven best practices, and explore how Fiddler's enterprise-grade monitoring capabilities enable teams to confidently take control of the entire model lifecycle management process.
Understanding the Machine Learning Lifecycle
The machine learning lifecycle encompasses the entire journey of an ML model — from initial development to deployment and ongoing monitoring. While many teams focus primarily on model development, the subsequent stages (monitoring, governance, and model retraining) often determine a model's long-term effectiveness.
For data scientists and machine learning operations (MLOps) teams, effectively managing the ML lifecycle is critical to building models that deliver sustained business value. One of the most pressing challenges is model degradation, a decline in performance caused by shifting data patterns, changing user behavior, or evolving external conditions.
Organizations must take a proactive approach to machine learning model lifecycle management to maintain model performance and ensure reliable outcomes. This broader discipline of machine learning model management, often overseen by MLOps teams, includes:
- Rigorous testing and validation
- Infrastructure alignment
- Continuous monitoring and maintenance
- Strong governance and compliance oversight
When implemented successfully, lifecycle management ensures models remain accurate, relevant, and aligned with operational demands and strategic business objectives.
The 7 Stages of the Machine Learning Model Lifecycle
Effectively managing the ML model lifecycle requires clearly understanding its seven key stages. These stages form an iterative process, supporting continuous learning and optimization across multiple development cycles. Let's explore each step in detail:
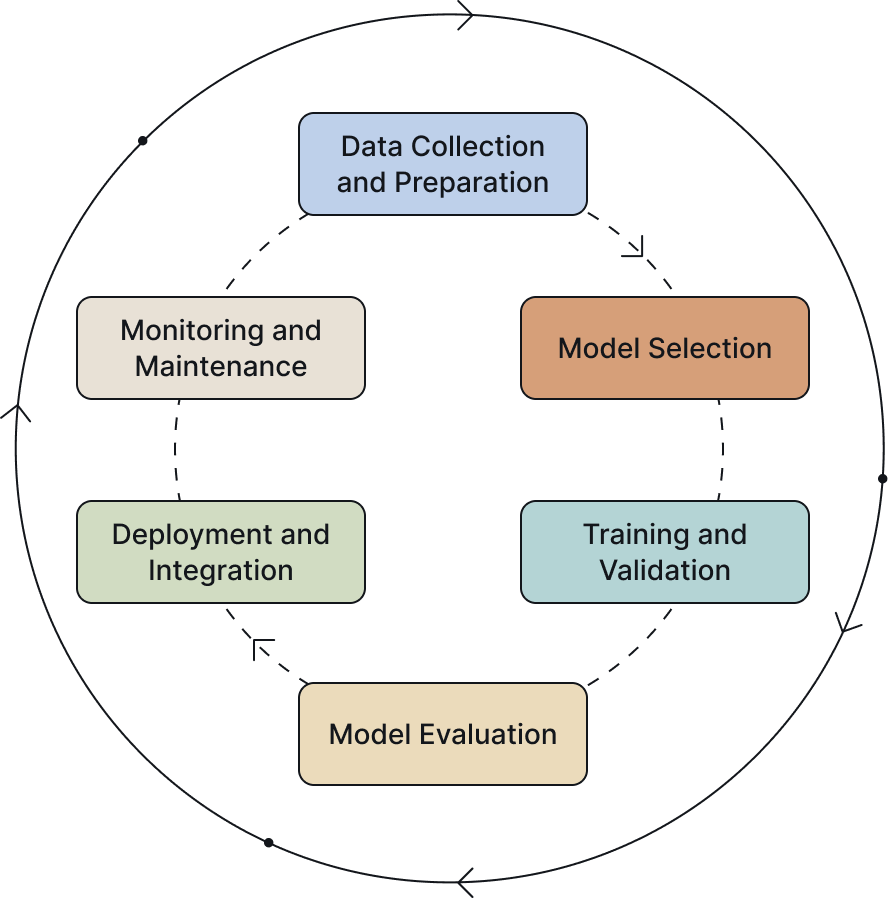
1. Data Collection and Preparation
High-quality data is the foundation of successful machine-learning applications.
- Data sourcing may involve internal systems, open datasets, third-party vendors, or synthetic data generation.
- Labeling typically requires collaboration with subject matter experts and may be subject to legal or regulatory constraints.
- Common challenges include data cleanliness, sampling bias, and high resource demands regarding time, cost, and expertise.
- Exploratory Data Analysis (EDA) is essential for understanding the dataset's structure, identifying anomalies, and guiding preprocessing strategies.
- Data preparation includes cleaning, managing missing values, feature engineering, and transforming datasets into formats suitable for training.
The quality and integrity of this stage directly influence model performance in later phases.
2. Model Engineering
Once the data is ready, scientists begin the model engineering phase and develop the model.
- Select algorithms appropriate for the problem (e.g., classification, regression).
- Train models using curated datasets while tuning model parameters for optimal performance.
- Evaluate the model's scalability, computational efficiency, and responsiveness in preparation for production.
This stage should follow defined quality assurance standards to ensure robustness, repeatability, and alignment with organizational goals.
3. Model Selection
Not all models offer equal value for every use case. During model selection, data science teams:
- Compare various algorithmic approaches and model architectures.
- Assess factors like training time, interpretability, and resource consumption.
- Align the chosen model with business objectives and model deployment constraints such as latency, cost, or infrastructure compatibility.
A thoughtful selection process helps minimize future bottlenecks and avoids costly revisions during later development cycles.
4. Training and Validation
This phase is central to the training process, where the model learns from historical data, while validation ensures it performs well on unseen data.
- Model training involves optimizing the model on labeled datasets to reduce error.
- Validation uses a separate dataset to detect overfitting and test generalization capabilities.
- Techniques such as cross-validation and stratified sampling improve the reliability of model evaluation.
This iterative process continues until the model meets predefined performance goals and is ready for the evaluation and deployment process.
5. Model Evaluation
A comprehensive model evaluation is essential before deploying a model into production. This step ensures the model meets performance standards and behaves reliably in real-world scenarios.
- Measure performance using a variety of model metrics tailored to the specific model type and use case, including:
- Binary Classification: Accuracy, Precision, Recall (True Positive Rate), F1-score, False Positive Rate, F-beta score, Area Under the Curve (AUC), Area Under the Receiver Operating Characteristic Curve (AUROC), Binary Cross Entropy, Geometric Mean, Calibrated Threshold, and Expected Calibration Error.
- Multi-class Classification: Accuracy and Log Loss.
- Regression: Coefficient of Determination (R-squared), Mean Squared Error (MSE), Root Mean Squared Error (RMSE), Mean Absolute Error (MAE), Mean Absolute Percentage Error (MAPE), and Weighted Mean Absolute Percentage Error (WMAPE).
- Ranking Models: Mean Average Precision (MAP) and Normalized Discounted Cumulative Gain (NDCG).
- Fairness and Bias Metrics: Disparate Impact, Demographic Parity, Equal Opportunity, and Group Benefit to support ethical and inclusive AI practices.
- Assess the model’s robustness under different conditions, such as varying data distributions, edge cases, and adversarial scenarios, to ensure consistent and reliable outputs.
A strong evaluation framework enables teams to make informed decisions about model readiness, identify potential risks, and guide future retraining efforts to maintain and improve performance over time.
6. Deployment and Integration
Deployment moves the model from a research setting to a live production environment. To successfully deploy machine learning models, teams must address performance, scalability, and compatibility challenges.
- Integrate models with APIs, cloud infrastructure, or edge devices.
- Based on workload requirements, choose suitable inference platforms (CPU, GPU, or TPU).
- Set up version control, configuration management, and CI/CD pipelines for reliable deployment.
- Ensure the deployed model is compatible with operational systems and aligns with security, performance, and compliance standards.
Successful deployment demands coordination across data science, engineering, DevOps, and IT teams to ensure smooth handoffs and production-grade stability.
7. Monitoring and Maintenance
Lifecycle management continues well beyond deployment, where ongoing performance assurance and continuous improvement come into play. This stage helps close the loop by providing valuable feedback on how users interact with the model using live data inputs. These insights enable teams to refine and enhance the model effectively.
- Implement model monitoring to track key model metrics in real time and detect issues like data drift, concept drift, and anomalies.
- Establish a schedule for model retraining to keep the model aligned with new data trends and evolving business needs.
- Set up automated alerts and diagnostic tools to address degradation proactively and avoid negative impacts on decision-making.
- Use feedback from live data and user interactions to identify opportunities for improvement and ensure the model remains relevant and accurate over time.
This stage reflects the iterative improvement process, where feedback loops drive continuous adaptation and long-term success in machine learning applications.
Lifecycle Management Best Practices
Organizations should adopt the following best practices to maximize ML models' reliability, scalability, and compliance. These approaches help standardize machine learning pipelines, reduce operational risk, and support strong model governance across the entire lifecycle.
Model Registry
- Maintain a central repository to register and manage all models across projects.
- Log metadata, training parameters, ownership, and current status.
- Supports traceability, auditing, and model reuse across teams and use cases.
Version Control
- Track changes to model code, data transformations, and machine learning pipelines.
- It helps teams roll back to previous versions, resolve issues, and understand performance regressions over time.
- Enhances accountability and aligns with best practices in model governance.
Experiment Tracking
- Log details of each experiment, including hyperparameters, datasets, and results.
- Compare outcomes across different runs to identify optimal configurations and training setups.
- Essential for refining the model selection process and improving transparency in development cycles.
CI/CD for ML
- Automate model testing, validation, and deployment using CI/CD pipelines tailored to machine learning workflows.
- Reduces manual errors, accelerates iteration, and ensures reliable updates in production environments.
- Facilitates consistent integration with operational systems while adhering to compliance requirements.
Quality Assurance
Quality assurance is critical throughout the model lifecycle and can occur in pre-production and production environments to ensure reliability and compliance.
- Implement end-to-end testing across data processing, models, infrastructure, and machine learning pipelines.
- Include adversarial testing, edge case scenarios, and fairness checks to validate robustness and minimize bias.
- Establish safeguards when handling sensitive data to meet privacy, security, and ethical standards.
Together, these practices establish a strong foundation for machine learning model lifecycle management, ensuring models are effective and scalable but also reproducible, explainable, and secure.
Take Control of Your ML Model Lifecycle with Fiddler
As enterprise organizations scale AI operations, the need for a unified platform to manage the full ML lifecycle becomes evident. That's where Fiddler comes in.
The comprehensive AI Observability and Security platform allows organizations to streamline model development, deployment, and monitoring. With Fiddler, teams can:
- Monitor live model performance with real-time dashboards and alerts.
- Detect and resolve data drift, concept drift, and other post-deployment issues.
- Gain explainability and transparency into model predictions and behaviors.
- Ensure compliance, fairness, and bias detection across the entire lifecycle.
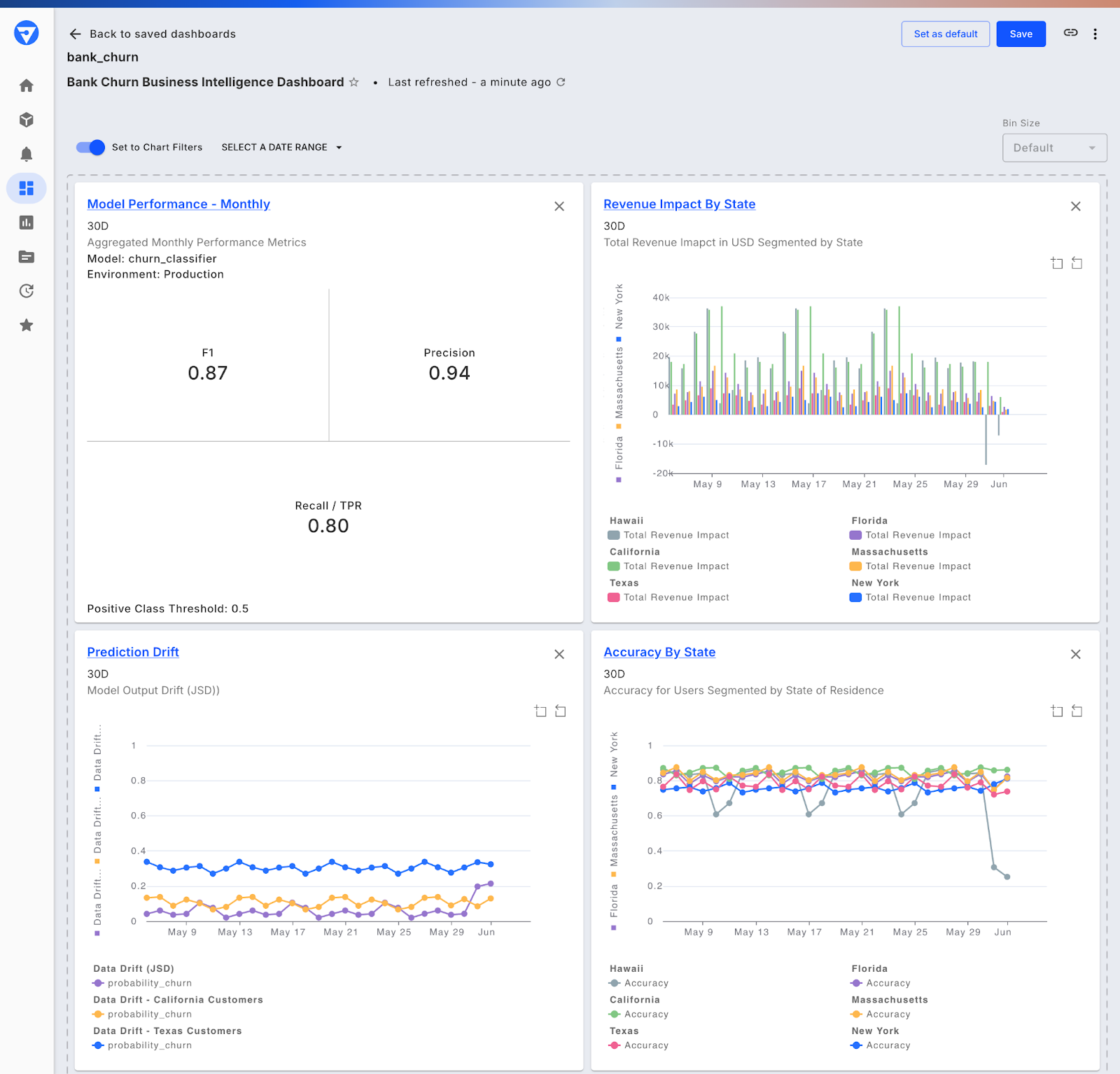
By integrating seamlessly with your existing ML stack, Fiddler simplifies the most complex aspects of ML lifecycle management, enabling your teams to build trustworthy, transparent, high-performing AI systems.
Ready to take control of your model lifecycle management? Discover how Fiddler's model monitoring empowers enterprise organizations to streamline processes, drive continuous improvement, and ensure long-term success in machine learning initiatives.
Frequently Asked Questions about ML Lifecycle Management
1. What is the ML lifecycle management?
ML lifecycle management oversees every stage of a machine learning model's existence within a machine learning project, from data collection and model building to deploying models, monitoring performance, and retraining as needed. It ensures that models remain compliant and aligned with evolving business objectives throughout their lifecycle.
2. What are the four types of machine learning models?
The four main types of machine learning models, each suited to different kinds of problems and data structures, are:
- Supervised Learning
This approach uses labeled datasets to train models, making it ideal for classification (e.g., spam detection) and regression (e.g., predicting housing prices). The model learns by mapping input data to known outputs. - Unsupervised Learning
In this method, models analyze unlabeled data to identify hidden patterns or groupings. Standard techniques include clustering (e.g., customer segmentation) and dimensionality reduction (e.g., PCA). - Semi-Supervised Learning
This hybrid method combines a small amount of labeled data with a larger volume of unlabeled data. It helps improve learning accuracy when labeling is expensive or time-consuming. - Reinforcement Learning
Models learn by interacting with an environment and receiving feedback through rewards or penalties. Developers often use this type in robotics, game AI, and dynamic decision-making systems.
Each model type plays a critical role depending on the goals and context of your machine learning project.
3. Are deep learning models a type of machine learning model?
Yes, deep learning models are a specialized type of machine learning model. While machine learning encompasses a wide range of algorithms that learn from data, deep learning specifically refers to models based on multi-layered neural networks. These deep neural networks can automatically learn complex patterns and representations, making them highly effective for tasks like image recognition, natural language processing, and more.
In essence, all deep learning models fall under the broader machine learning category, but they use advanced architectures to handle more complex data and problems.
