How do you implement MLOps?
4
Min Read
Machine learning (ML) has many applications, from forecasting market trends to diagnosing diseases to translating languages. The impact of machine learning has been immense, but this new technology continues to have hiccups.
Some mistakes are lighthearted, like the artificial intelligence (AI) camera designed to track a soccer ball for televised games. The algorithm got confused by a bald linesman (an assistant to the referee) and kept moving the camera to follow the bald head, making viewers at home miss the action.
Other mistakes are much more serious, like the facial recognition algorithm used by a police department in New Jersey. The algorithm had improperly matched Nijeer Parks to a fake ID left at a crime scene. This resulted in an innocent person spending 11 days in jail. This false match is not an isolated event, unfortunately. Facial recognition algorithms are a good example of a terrible problem: racial bias that has been baked into machine learning.
To prevent machine learning algorithms from having negative impacts and behaving in biased or improper ways, it’s vital to install a MLOps framework that focuses on model monitoring. In this short guide, we will explore MLOps and how to get started with this practice.
What is MLOps and why do we need it?
MLOps, the acronym for “machine learning operations,” is a framework for how teams should create, implement, monitor, and retrain machine learning models in a structured and segmented manner. There are nine stages in the MLOps lifecycle:
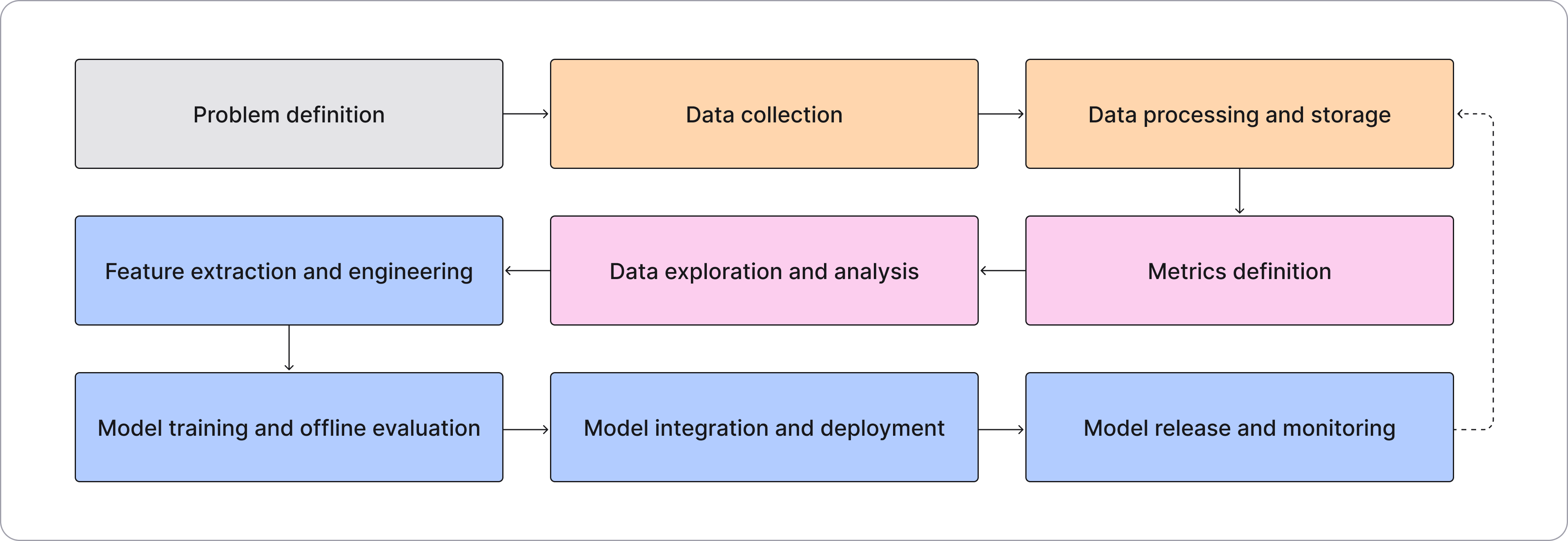
Similar to other “operations” practices, an MLOps framework is essentially a system for collaboration, bringing together data scientists, ML/AI engineers, and operations professionals to work together efficiently and effectively. MLOps also emphasizes regulatory compliance through model governance.
What problems does MLOps solve?
In general, MLOps solves two high level problems by providing a framework that deploys high-quality models that do exactly what they are supposed to do and gives teams the ability to observe changes that happen, so that negative impacts can be caught and adjusted before the model goes into production.
Additionally, MLOps can address:
- Inefficient workflows - MLOps brings together business expertise with technical prowess to create a more structured, iterative workflow.
- Failure to comply with regulations - With artificial intelligence (AI) being a relatively new field, regulations are constantly shifting as lawmakers update and adapt requirements and guidelines. MLOps takes ownership of compliance, making sure that your algorithms stay up-to-date with changing regulations, such as those found in banking.
- Bottlenecks - MLOps facilitates collaboration between operations and data teams, helping to reduce the frequency and severity of bottlenecks. This teamwork approach leverages the expertise of previously siloed teams, facilitating the efficient building, testing, monitoring, and deploying of machine learning models.
- Lack of feedback - Without MLOps, it’s easy to neglect feedback loops. This framework helps you build feedback into your process so that inaccuracies are caught before they lead to major issues like data drift or model bias.
What is included in MLOps?
MLOps covers all the stages of developing a machine learning model as well as the post-deployment process of model monitoring and retraining. While some may think that the difficult part of machine learning is developing and deploying models, the truth is that what happens after is the trickiest. Remember those examples we gave earlier? Those algorithms performed in unexpected ways after being deployed. MLOps can help turn that black box into a glass box, giving visibility to why algorithms perform in certain ways and how you can adjust them to eliminate negative outcomes.
How do I start MLOps?
At the moment, MLOps is not standardized — the companies who are using this practice have developed their own version, often based on the typical Application Performance Monitoring or DevOps frameworks. However, machine learning models are quite different, and these methods do not encompass the ML lifecycle fully.
The best place to start with MLOps is with a dedicated AI Observability platform — a centralized control system at the heart of the ML workflow that closely tracks model performance, helping close the ML feedback loop. AI observability is an excellent introduction to MLOps, as it gets to the heart of the framework — model monitoring and feedback. With the lessons learned from AI observability, zooming out to a wider MLOps framework is a simple process and is easily standardized.
Request a demo to see how MLOps tools like Fiddler can help you get started.
