How well do you understand the MLOps lifecycle and how to plan for success at every step in the journey? Here’s a short overview of how machine learning models fit into a business and the nine steps of a successful MLOps lifecycle.
How do machine learning models fit into a business?
Before talking about how machine learning models are developed and operationalized, let's zoom out to talk about the why — what are the use cases for machine learning models in a business?
In essence, machine learning is a very advanced form of data analytics that can be used in three ways: descriptively, predictively, and prescriptively.
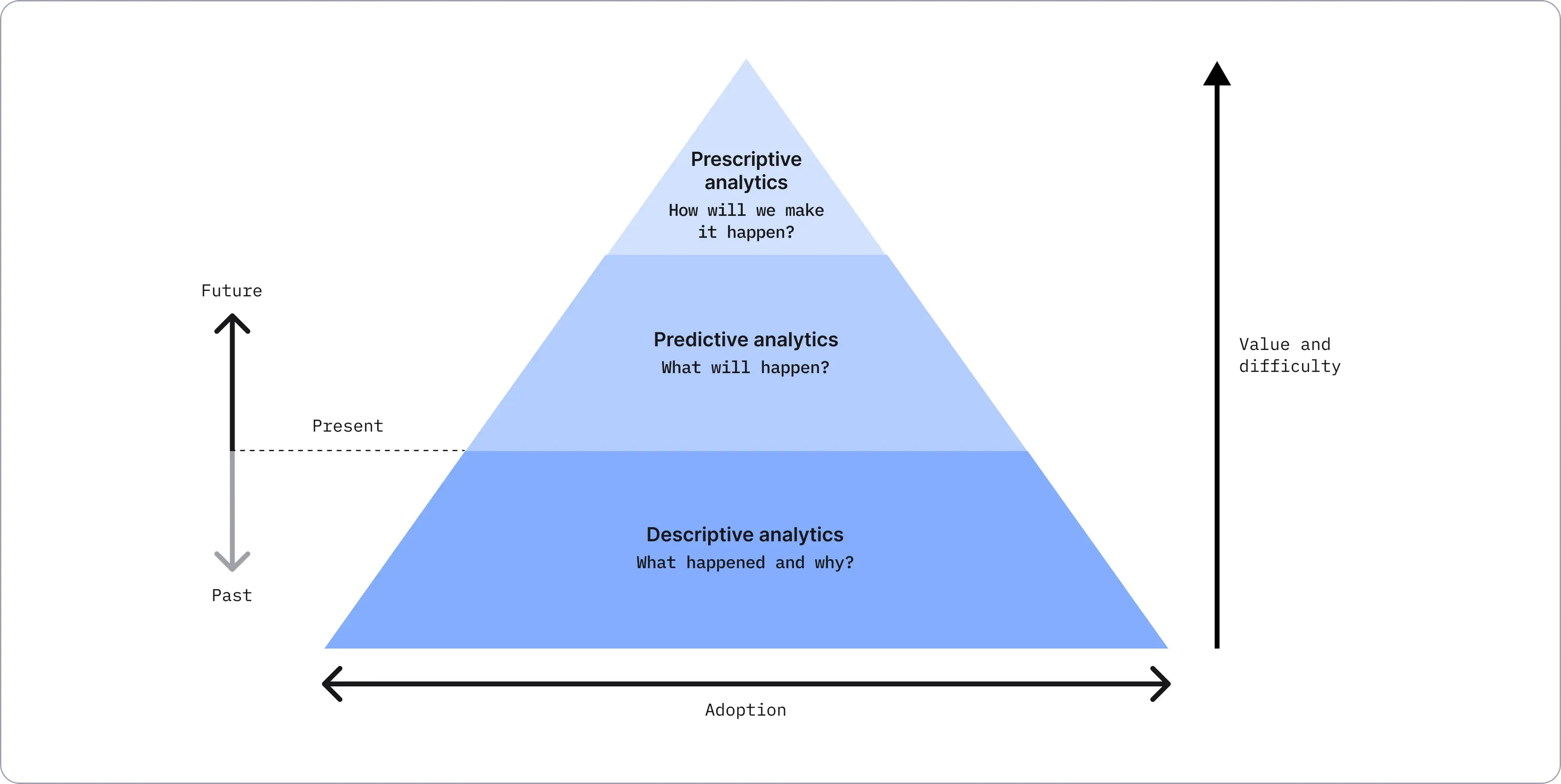
Descriptive analytics helps you understand what happened in the past. Machine learning models are widely replacing traditional manual analysis (e.g. charts and graphs) to provide a more accurate picture of historical trends.
Predictive analytics goes a step further to predict future business scenarios or customer behavior based on what has happened in the past.
Prescriptive analytics is arguably the most valuable application for machine learning because it allows models to automate business decisions based on data. Using machine learning to target ads, detect fraudulent transactions, or route packages are all forms of prescriptive analytics. Models used in this way have a direct impact on business outcomes — but with more reward comes greater risk.
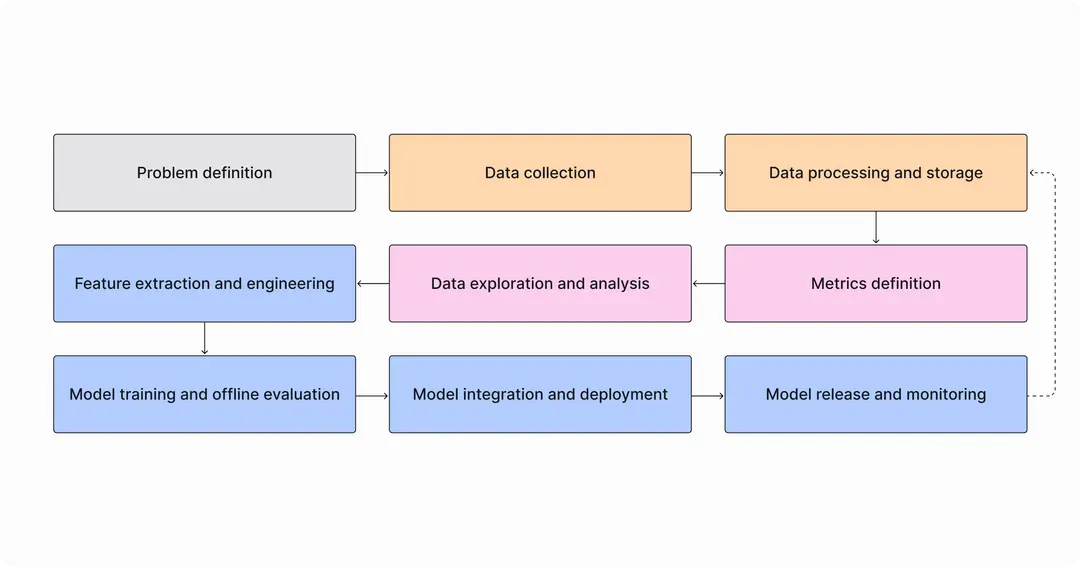
The steps in the MLOps lifecycle
Most sufficiently complex models will go through the following nine stages in their MLOps lifecycle:

- Problem definition: All model development starts with identifying a concrete problem to solve with AI.
- Data collection: Data is collected that will be used for model training. This data might come from in the product (e.g. data on user behavior), or it could be from an external data set.
- Data processing or storage: Because machine learning requires a large amount of data, typically a data warehouse or data lake is used for storage. To consolidate and clean the data, it’s processed in batches or as a stream, depending on requirements and tooling that the company has available.
- Metrics definition: It’s important to agree on the metrics the team will use to measure the model’s quality as well as its success at solving the problem identified in step 1.
- Data exploration: Data scientists will analyze the data to develop hypotheses about what modeling techniques would be most useful.
- Feature extraction and engineering: Features are the aspects of your data (like whether a user has a good or bad credit score) that will be used as inputs to your model. Data scientists will need to determine what features to generate and how, and engineers will need to ensure features can be updated regularly as new data comes in.
- Model training and offline evaluation: Models are built, trained, and evaluated to choose the approach with the best performance. Most of the data that’s been collected and processed will be used to train models, while a smaller portion (usually around 20–30%) will be reserved for evaluation.
- Model integration and deployment: When models are validated and ready, they need to be integrated into the product, which may involve building new services and hooks to fetch model predictions that will drive an end-user outcome. Then they’re deployed, usually within a cloud system like AWS.
- Model release and monitoring: Once deployed, models need to be closely monitored to ensure there are no issues in production. Model monitoring also helps identify how the model can be improved with retraining on new data.