What is the difference between model performance and model accuracy?
7
Min Read
When discussing model accuracy vs model performance, it’s important to note that model accuracy is just one core classification metric used to assess model performance. To truly understand how well a model is performing, multiple metrics must be evaluated and comprehensive insight is needed at every step of the machine learning (ML) lifecycle.
Unfortunately, most models are opaque and slowly degrade over time (often referred to as model drift), making it extremely difficult to detect flaws in the model during training or deployment. So, what’s to be done?
In order to maximize the effectiveness and reliability of an ML model, organizations must:
- Understand what model performance is, and know how accuracy comes into play.
- Develop a comprehensive ML model monitoring framework to identify and rectify various inaccuracies.
What is model accuracy?
At its core, model accuracy determines if predictions made by an ML model are correct. Like most model performance metrics, the accuracy metrics used by ML teams depend on the model’s purpose. However, all accuracy metrics function to offer high-level insights so ML teams can better understand the precision of their models.
At its core, the accuracy formula is designed to reflect the fraction of predictions your model got right:
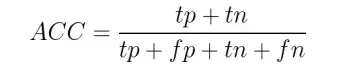
However, accuracy is just one piece of the ML model metric puzzle. On its own, accuracy can be misleading if your model has class imbalance, which is why accuracy works in conjunction with other metrics for a more holistic view.
Is model accuracy sufficient to use in all cases?
As a crucial component of ML performance, model accuracy is a metric that warrants careful observation. However, successful performance extends beyond good accuracy. Several model performance metrics must be collected and reviewed in order to garner a true picture of a model’s health. Additionally, the combination of metrics and variables used to determine if an ML model is performing optimally varies in every scenario.
Although there is no standard set of metrics to monitor all ML model types, understanding which metrics generally apply to the model monitoring process is critical when evaluating ML model performance. Accuracy is just one metric used when monitoring classification models, specifically.
There are at least six classification metrics that must be used in addition to accuracy:
- True Positive Rate (Recall or Sensitivity) – Reviews all positives in a model’s predictions and calculates the fraction of positives your model classified correctly.
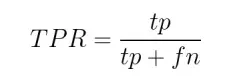
- False Positive Rate – Identifies when your model incorrectly catalogs predictions as negative.
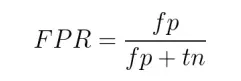
- Precision (Positive Predictive Value) – Identifies the number of predictions your model incorrectly identifies as positive. This metric closely relates to true positive rates or recall. When recall is increased, precision inevitably decreases.
- F1 Score – Combines precision and recall into one metric, where they are both equally represented. This formula is fairly comprehensive, and is regarded as an overarching metric for determining model quality.

- Log Loss – Determines how many errors are made by your classification model. Log loss specifically deals with uncertainty when predicting true positives. Unlike the other metrics we’ve listed, log loss does not come with a set formula.
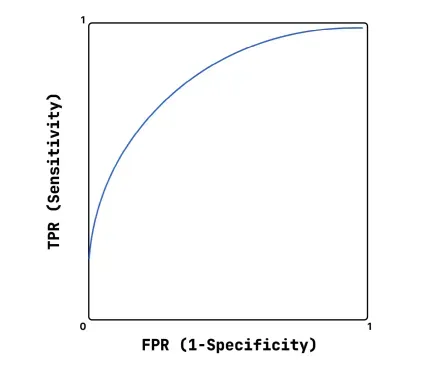
- Area Under Curve (AUC) | Critical for visualizing the performance of your model. The area under the curve compares a model’s true positive rate against its false positive rate. If everything is going well, the AUC graph will represent a high area curve, which indicates that your model has high recall and a low false positive rate. Similar to log loss, AUC does not have a specific formula attached to it.
We should note that these metrics only apply to general classification models. There are four other model types which all have different sets of metrics for measuring performance:
- Binary classification models
- Multi-class classification models
- Regression models
- Ranking models
What is model performance and how can it be improved?
Put simply, model performance measures the model’s ability to perform as intended. Of course, like all things in machine learning, this process is much more complex than it may seem at first glance. Here’s why:
Because software relies on inflexible logic, poor performance always coincides with faults in the software’s logic, but this isn’t the case with model performance. ML models deal with historical and new data and rely on statistical analysis, making them much more fluid. Therefore, if a ML model’s performance starts to degrade, the source of the problem is difficult to identify.
Truly understanding how to increase accuracy of a model and improve overall performance requires consistent evaluation and comprehensive insight into all steps of the MLOps life cycle, including model monitoring best practices. If ML performance issues fly under the radar, your bottom line and end users will begin to suffer. Additionally, it puts your business at risk of violating model compliance and AI regulations. In the end, explaining and evaluating model accuracy and performance is impossible without a comprehensive AI observability platform like Fiddler.