
In Part 1 of our blog series on monitoring NLP and CV models, we covered the challenge in monitoring text and image models and how Fiddler’s patent-pending cluster-based algorithm offers accurate model monitoring for models with unstructured data. In Part 2 of the series we will share an example of how you can monitor image models using Fiddler.
Why should you monitor image models?
Deep Learning based models have been very effective at a wide range of CV tasks over the past few years, from smartphone apps to high stakes medical imaging and autonomous driving.
However, when these image models are put into production, they often encounter distributional shifts compared to training data. Such shifts can manifest in various ways, such as image corruption in the form of blurring, low-light conditions, pixelation, compression artifacts, etc. As reported in [1] such corruptions can lead to severe model underperformance in production.

Source: https://github.com/hendrycks/robustness
CV models also have to contend with subpopulation shifts in post-deployment because production data can differ from data that was observed during training or testing phases.

Source: https://wilds.stanford.edu/datasets/
Receiving model monitoring alerts and being able to quantify distributional shifts can help identify when retraining is necessary and potentially construct models whose performance is robust to such shifts.
Fiddler’s cluster-based approach to CV monitoring
Meaningful changes in distributions of high-dimensional modalities such as images, text, speech, and other types of unstructured data can't be tracked directly using traditional model drift metrics, such as Jensen-Shannon divergence (JSD), which require data be binned in categories.
Additionally, it has been shown that intermediate representations from deep neural networks capture high-level semantic information about images, text, and other unstructured data types [2]. We take advantage of this phenomenon and use a cluster-based approach to compute an empirical density estimate in the embeddings space instead of the original high-dimensional space of the images.
Read Part 1 of our blog series to further dive into the details of this approach.
An example: How to monitor a model with image data
In the following example, we demonstrate the effectiveness of the cluster-based method with the popular CIFAR-10 dataset. CIFAR-10 is a multi-class image classification problem with 10 classes. For the purpose of this example, we trained a Resnet-18 architecture on the CIFAR-10 training set. As mentioned in the previous section, we use the intermediate representations from the model to compute drift. In this example, we use the embeddings from the first full-connected FC1 layer of the model as shown in the figure below. Embeddings from the training set serve as the baseline against which to measure distributional shift.

We then inject data drift in the form of blurring and reduction in brightness. Here’s an example of the original test data and the two transformations that were applied:



To simulate monitoring traffic, we publish images over 3 weeks to Fiddler. During week 1, we publish embeddings for the original test-set (Figure 4). In week 2 and 3, we publish embeddings from the blurred (Figure 5) and brightness reduced images (Figure 6) respectively.
These production events are then compared to the baseline training set to measure drift. On Figure 7, the JSD (Jensen-Shannon Divergence) is negligible in week 1 but increases over week 2 and further during week 3.
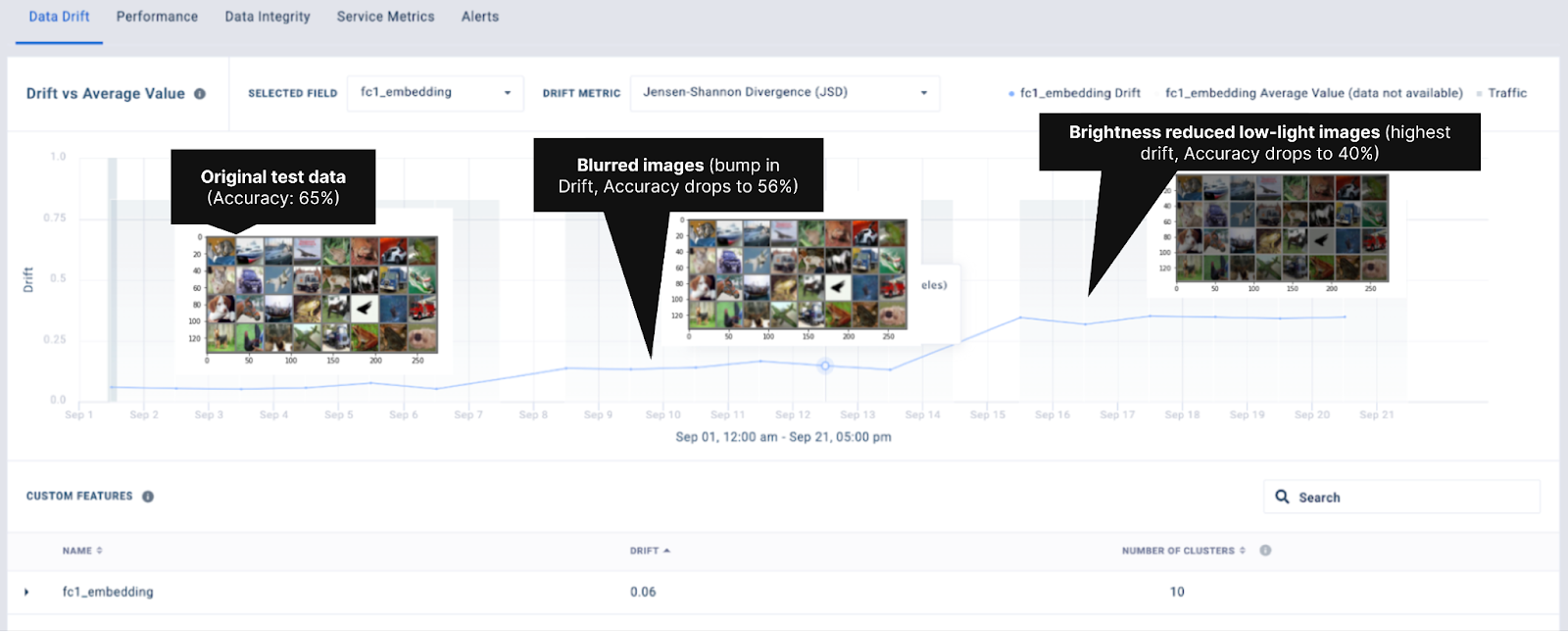
In the same intervals, model performance deteriorates since the model did not encounter images from these modified domains during training. Hence the increase in data drift captured by this method serves as an indicator of possible degradation in model performance. This is particularly helpful in the common scenario where labels are not immediately available for production data.
We’ve included a notebook you can use to learn more about this image monitoring example.
Interested in learning more about how you can use Fiddler’s cluster-based approach to monitor your computer vision models? Contact us to talk to a Fiddler expert!
——
References
[1] Hendrycks et. al, Benchmarking Neural Network Robustness to Common Corruptions and Perturbations, ICLR 2019
[2] Olah, et al., "The Building Blocks of Interpretability", Distill, 2018.