Large Language Models (LLMs) are powerful tools for Natural Language Processing (NLP) tasks, but they have limitations. Pre-trained models like GPT-4 and Claude generate fluent text and answer questions effectively; however, they can struggle with domain-specific, or obscure topics that fall outside their training data.
Retrieval-augmented generation (RAG) addresses this challenge by combining LLMs with external information retrieval. Instead of relying solely on fixed training data, RAG dynamically retrieves relevant information from external sources such as knowledge bases or vector databases. It incorporates this context into the generation process. This hybrid approach enables more accurate, grounded, and domain-specific responses.
As enterprises increasingly deploy LLM applications in production, RAG provides a flexible and scalable way to integrate dynamic knowledge. However, building RAG-based systems is complex and demands robust observability, security, and performance optimization tools.
The Fiddler AI Observability and Security Platform supports organizations throughout the entire lifecycle of LLM applications. Fiddler offers a comprehensive workflow that empowers enterprises to launch safe, responsible, high-performing LLM applications at scale, from development and deployment to monitoring and refinement.
What is RAG for LLMs?
Retrieval-augmented generation (RAG) is an architecture that enhances LLMs by retrieving relevant documents from an external knowledge base and combining them with generated outputs. This retrieval augmentation allows models to dynamically reference factual, or proprietary information without retraining, leading to more contextually relevant responses.

How RAG Strengthens LLM Performance
- Grounds responses with facts: By integrating retrieval augmentation, models minimize hallucinations and improve answer accuracy by accessing up-to-date information during response generation.
- Reduces training complexity: RAG enables dynamic knowledge updates without costly and time-consuming fine-tuning.
- Enhances scalability and agility: Knowledge base updates are immediate, allowing the system to adapt quickly without retraining the entire model.
Benefits of RAG in LLM Applications
- Delivers accurate responses grounded in relevant context for knowledge-intensive domains.
- Offers on-demand adaptability across diverse use cases.
- Provides better performance in production environments without repeated model retraining.
RAG’s Role in Production Systems
In production, RAG offers enterprises agility and control. Without modifying the underlying model, they can update their retrieval sources as business information evolves. Organizations can ensure safer, more responsive LLM systems that optimize retrieval and response generation by using observability and monitoring tools to monitor RAG applications.
Understanding the RAG Framework
The RAG architecture typically involves three core components:
1. Retrieval
The retrieval process begins with a retriever component that identifies and fetches relevant information from external sources such as:
- Vector databases
- Internal document stores
- Search indexes
These sources consist of indexed representations of documents transformed into embeddings, enabling semantic search techniques that match user queries with relevant results during the retrieval process.
2. Generation
The retrieved documents, combined with the user input, provide the retrieved context fed into the LLM. This augmented input enables the model to generate contextually informed and relevant responses.
3. Augmentation
The fusion of query, retrieval output, and generation process results in highly accurate, customized content. This augmentation step is where RAG shines, allowing the LLM to act more like a reasoning engine over live knowledge.
Building RAG-Based LLM Applications
To build RAG systems and develop an RAG-based LLM application ready for production, organizations typically follow these steps:
1. Data Preparation
- Identify high-quality, domain-specific documents (FAQs, manuals, support docs, internal data).
- Clean, preprocess, and chunk documents appropriately.
- Create vector embeddings using a model from OpenAI, Hugging Face, or Cohere.
- Store the vectors in a scalable vector database with fast retrieval capabilities.
2. Model Training and Configuration
- Fine-tuning may not be necessary, but configuring the LLM to work with your retrieval system is essential.
- Define user prompts and queries that accept retrieved documents, and catalog them into the prompt library.
- Evaluate accuracy, toxicity, and other LLM metrics using test datasets before deploying to production.
3. Deployment
- Wrap the system with APIs necessary to build out the user interface.
- Ensure latency, throughput, and cost are optimized.
- Integrate feedback loops for continuous learning and improvement.
Fiddler simplifies this deployment journey by offering observability features that monitor response quality, data drift, and prompt safety. These features give enterprises confidence in model performance post-deployment.
Prompt Engineering for RAG
Prompt engineering guides how an LLM utilizes retrieved content to generate accurate and relevant responses. Here are some best practices to follow:
- Priming: Include examples in the prompt to demonstrate the desired response style and format.
- Chaining: Use sequential or intermediate prompts to manage complex reasoning or multi-turn interactions.
- Meta-Prompting: Add instructions that help the model assess and prioritize the relevance of retrieved documents.
Tools to Support Prompt Engineering
- Platforms that optimize prompts by refining input queries.
- Evaluation frameworks for comparing and assessing prompt performance.
- Fiddler’s observability platform provides detailed metrics on prompt effectiveness, hallucination detection, and overall response quality.
RAG Applications and Tools
- Question Answering: Retrieve relevant documents to provide precise, fact-based answers for customer support or internal knowledge queries, especially for knowledge-intensive tasks.
- Text Summarization: Extract and condense source information to generate concise summaries.
- Chatbots: Power conversational agents with real-time, accurate knowledge to enhance user interactions.
The Fiddler LLM Observability platform helps organizations build and manage RAG-based applications by offering tools to monitor performance, analyze behavior, and keep systems secure in production. It makes it easier to connect the retrieval and generation parts of a RAG system, helping teams develop reliable, end-to-end applications faster and with less complexity.
Challenges with RAG
Despite its advantages, implementing RAG introduces several challenges:
- Data Quality: Inaccurate, incomplete, or outdated source documents can significantly degrade response accuracy and reliability.
- Retrieval Mismatch: Poorly matched or irrelevant documents lead to off-topic or incorrect answers, reducing user trust.
- Latency: The additional retrieval step, combined with generation, can increase response times, impacting user experience.
- Security and Compliance: Integrating external data sources raises concerns around privacy, data governance, and intellectual property protection.
Fiddler addresses these challenges by assessing the user inputs and LLM outputs to identify whether hallucination, toxicity and prompt injection attacks are visible, compliance checks to enforce governance policies, and real-time monitoring that alerts teams to metrics that have fallen outside of the acceptable thresholds. These safeguards ensure that RAG applications operate securely and reliably.
Maintaining an Up-to-Date RAG Database for Optimal LLM Performance
Keeping the RAG Database Fresh
A key advantage of RAG is its ability to incorporate the latest information. To maintain optimal performance, teams must regularly ingest and re-index new documents. Automating updates through pipelines connected to content management systems (CMS) or knowledge repositories ensures the retrieval database remains current and relevant.
Evaluating Performance
Effectiveness should be measured using key performance indicators (KPIs) such as:
- Accuracy: The factual correctness of responses.
- Relevance: The topical alignment of retrieved documents with user queries.
- Fluency: The naturalness and coherence of generated language.
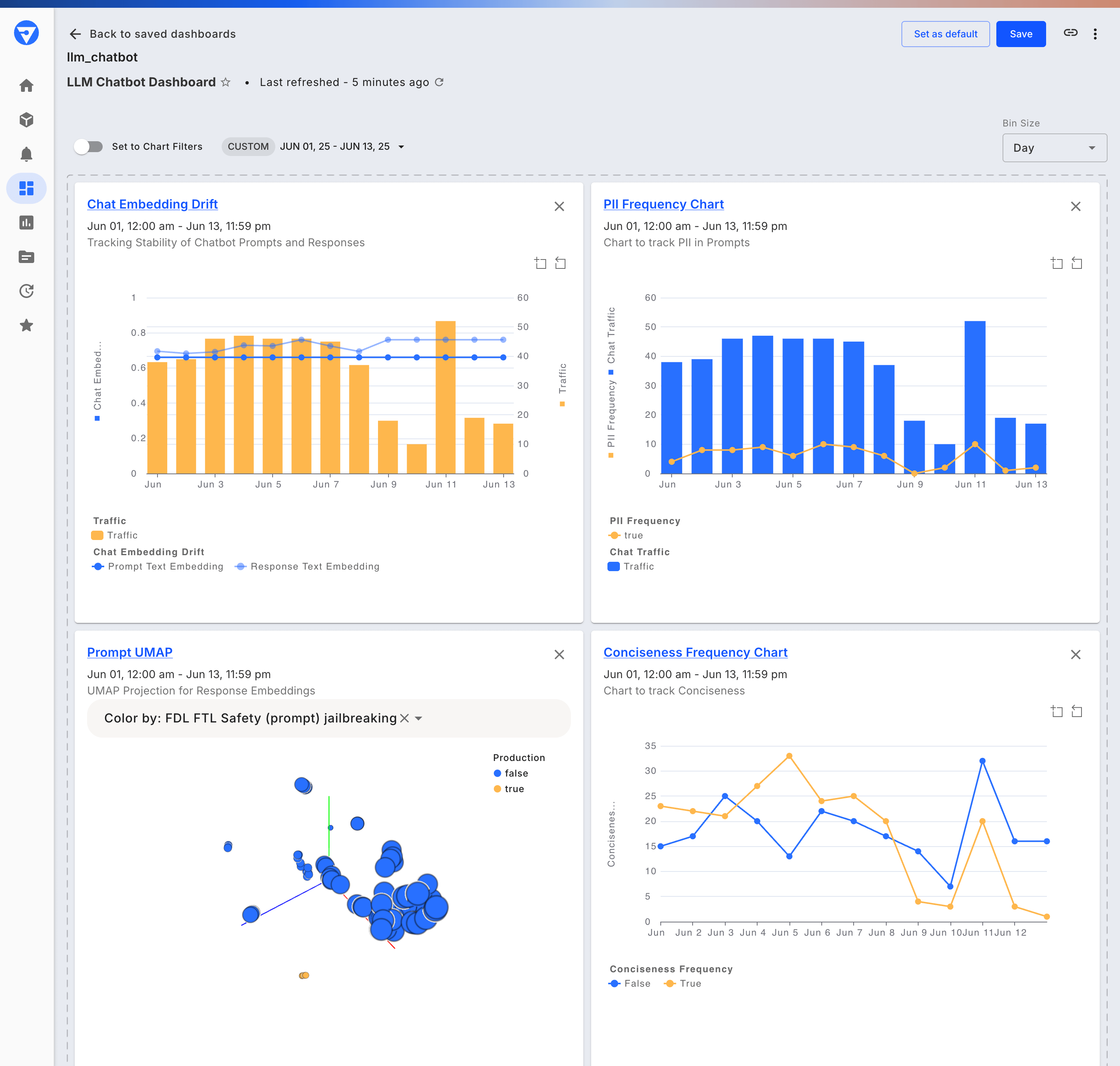
Fiddler provides customizable dashboards and reports that help track these metrics over time, enabling early detection of inaccuracies, toxic content, and prompt injection attacks.
Continuous Monitoring and Feedback
Production-ready RAG systems benefit from ongoing evaluation that includes:
- Human-in-the-loop assessments to validate outputs.
- Automated quality scoring to maintain consistent standards.
- Integration of user feedback to adapt and improve the system dynamically.
These practices ensure RAG applications evolve alongside changing user needs and data landscapes.
Future Directions for Building RAG-Based LLM Applications
RAG is an evolving paradigm with immense potential. Future innovations may include:
- Context-Aware Retrieval: Using session history or user profiles to refine search.
- Knowledge Graph Integration: Structured knowledge can improve precision and reduce ambiguity.
- Multi-modal RAG: Combining text with images or audio for richer responses.
As enterprise needs grow, RAG will underpin applications across:
- Customer engagement and support.
- Legal and compliance.
- Financial analysis and forecasting.
- Education and training.
- Patient care and wellness.
RAG-based LLM applications represent the next frontier of intelligent, context-aware AI systems. They solve many limitations of static pre-trained models, offering dynamic adaptability and stronger factual grounding.
But realizing their full potential in production requires more than just strong models — it requires visibility, safety, and trust.
Fiddler’s AI Observability and Security Platform delivers a comprehensive monitoring and analysis framework to deploy RAG-based applications confidently. Whether you confidently deploy RAG-based application tools at scale, Fiddler ensures your systems remain accurate, compliant, and reliable.
Want to safeguard, monitor, and analyze your RAG-based LLM applications? Explore the Fiddler LLM Observability today.
FAQs about RAG-Based LLMs
1. What data systems are used for RAG LLMs?
RAG LLMs typically rely on external knowledge sources such as vector databases (e.g., Pinecone, Weaviate, DataStax), document repositories, and search indexes. These systems use an embedding model to transform documents into embeddings, which are then stored and indexed to enable efficient semantic retrieval. This retrieval process supplements the LLM’s generated responses with relevant, up-to-date information.
2. How does RAG compare with fine tuning?
RAG and fine-tuning serve different purposes. Fine-tuning customizes an LLM’s internal parameters to adapt it to specific tasks or domains, which can be resource-intensive and inflexible. In contrast, RAG augments a pre-trained model with an external retrieval system, enabling dynamic access to fresh knowledge without retraining. This approach makes RAG more scalable and adaptable to changing information.
3. What is the difference between RAG and fine-tuning LLMs?
While fine-tuning modifies the model’s weights to specialize it, RAG leaves the core model unchanged and enhances responses by retrieving relevant external documents in real time. Fine-tuning is best for fixed domain adaptation, whereas RAG supports continuous updates and flexible knowledge integration without retraining.
4. Can you provide an example of RAG in action?
When answering user questions, a customer support chatbot using RAG can retrieve the latest product manuals or policy documents from a knowledge base. Instead of relying solely on pre-trained knowledge, the chatbot dynamically fetches accurate, up-to-date information to provide precise answers — even about recent changes — improving reliability and user satisfaction.
