As enterprises increasingly adopt generative AI and large language models (LLMs), the complexity and risk associated with these systems grow in equal measure. From internal copilots that guide employee workflows to customer-facing bots handling sensitive queries, AI applications demand reliability, accountability, and built-in safety.
AI guardrails have emerged as a critical layer of protection, helping organizations ensure their AI outputs are safe and aligned with business objectives. But how do we evaluate the effectiveness of these guardrails? And how can enterprises use LLM reports and metrics to enhance visibility and reduce risk?
This blog explores how LLM metrics help evaluate model input and outputs, and how AI guardrails act on those metrics to accept, flag, or block outputs. Together, they help improve performance, support compliance and reporting, and protect users. It also highlights how Fiddler Trust Service enables enterprise teams to deploy reliable AI systems through real-time guardrail enforcement and scalable observability.
Key Takeaways:
- Guardrails are real-time moderators for LLM and agent-based AI systems, preventing unsafe or low-quality outputs.
- LLM metrics quantify trust, capturing risks like hallucinations, jailbreaks, toxicity, and data leakage.
- LLM reports drive accountability, informing retraining, compliance audits, and governance reviews.
- Fiddler Trust Service powers enterprise guardrails with fast, cost-effective scoring and customizable risk thresholds across diverse AI use cases.
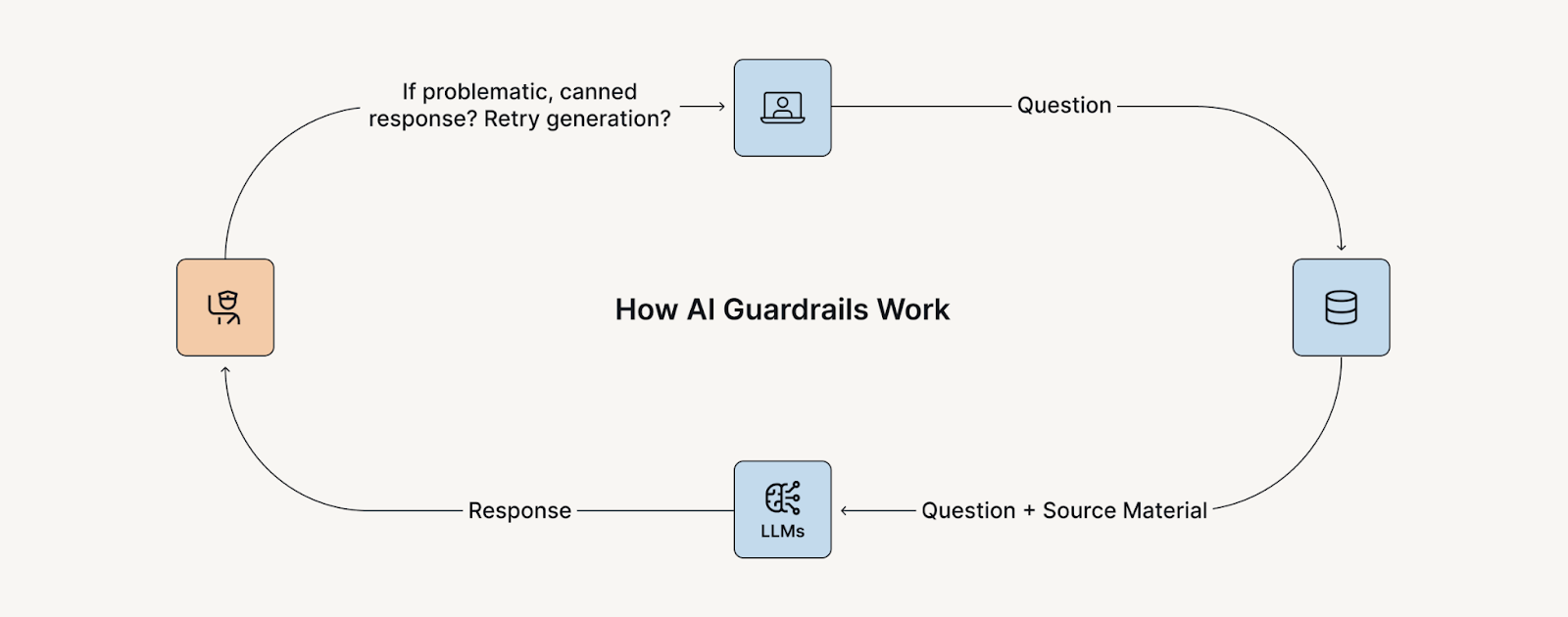
What are AI Guardrails and Why do They Matter?
AI guardrails are safety mechanisms designed to act upon the outputs of generative AI systems, especially LLMs and autonomous agents. These safeguards moderate interactions in real time, filtering harmful or misaligned outputs before they reach end users.
Their Importance Has Grown Alongside the Rise of Generative AI:
- In GenAI chatbots, guardrails prevent the system from returning toxic, PII/PHI data, or fabricated answers.
- In autonomous agents, guardrails limit the decision space to ensure agents don’t act outside defined parameters.
- In enterprise tools, guardrails help maintain regulatory and brand compliance across high-stakes workflows.
Common Risks Addressed by AI Guardrails Include:
- Prompt injection attacks: Attempts to manipulate an LLM into unsafe behavior.
- Hallucinations: Confident but incorrect or fabricated outputs.
- Toxicity and bias: Responses containing offensive, unethical, or discriminatory language.
- Data leakage: Unintentional exposure of personally identifiable information (PII), protected health information (PHI), or proprietary content.
By intercepting such outputs, AI guardrails protect users and organizations while building trust in AI-driven applications.
Understanding Guardrail Metrics
Guardrails rely on quantitative metrics to score both prompts and responses. These metrics assess model outputs' safety, quality, and reliability and are the foundation for automated decisions across input and output guards. By applying multiple guardrails in tandem, organizations can create a layered defense that reduces risk and enhances control over AI behavior.
As teams import guardrails into production workflows, these metrics become critical for evaluating system integrity and maintaining oversight across varied use cases.
.png)
Key Categories
1. Safety Metrics
- Jailbreak Detection: Identifies attempts to bypass safety rules (e.g., “Ignore previous instructions”).
- Toxicity and Profanity: Scores harmful or offensive language.
- Sentiment: Detects hostile, overly harmful, or emotionally manipulative content.
2. Hallucination Metrics
- Faithfulness: Measures whether the input data support the output.
- Groundedness: Evaluates whether the answer is based on reliable sources or retrieved context.
- Answer Relevance: Assesses whether the response addresses the user query.
- Coherence: Judges logical consistency throughout a response.
3. Sensitive Information Metrics
- PII (Personally Identifiable Information): Detects exposure of sensitive identifiers such as names, phone numbers, email addresses, and national IDs.
- PHI (Protected Health Information): Flags disclosures of medical records or health-related data that could compromise patient privacy or violate compliance regulations.
Why These Metrics Matter
These scores enable:
- Quality assurance workflows
- Prompt and model optimization
- Regulatory and compliance audits and security assessments
- Behavioral comparisons across model versions
When used proactively, guardrail metrics offer deep insights into how models behave and where they need improvement.
The Role of AI Reports in Driving Governance and Accountability
AI reporting is critical for governance, auditability, and continuous improvement, especially in high-risk sectors such as finance, healthcare, and enterprise IT. LLM reports go far beyond raw metric scores. They provide:
- Summary dashboards that surface risk categories and violation trends
- Prompt-level analysis to trace and understand problematic outputs
- Model comparisons across key dimensions such as performance, cost, and latency
- Feedback loops that connect QA teams, developers, and model trainers for iterative improvement
- Audit evidence for compliance and governance requirements
For instance, a financial institution deploying an LLM-based chatbot can leverage LLM reports to:
- Monitor and reduce hallucination rates over time
- Justify model updates during regulatory reviews
- Proactively detect user prompts that lead to unsafe or noncompliant responses
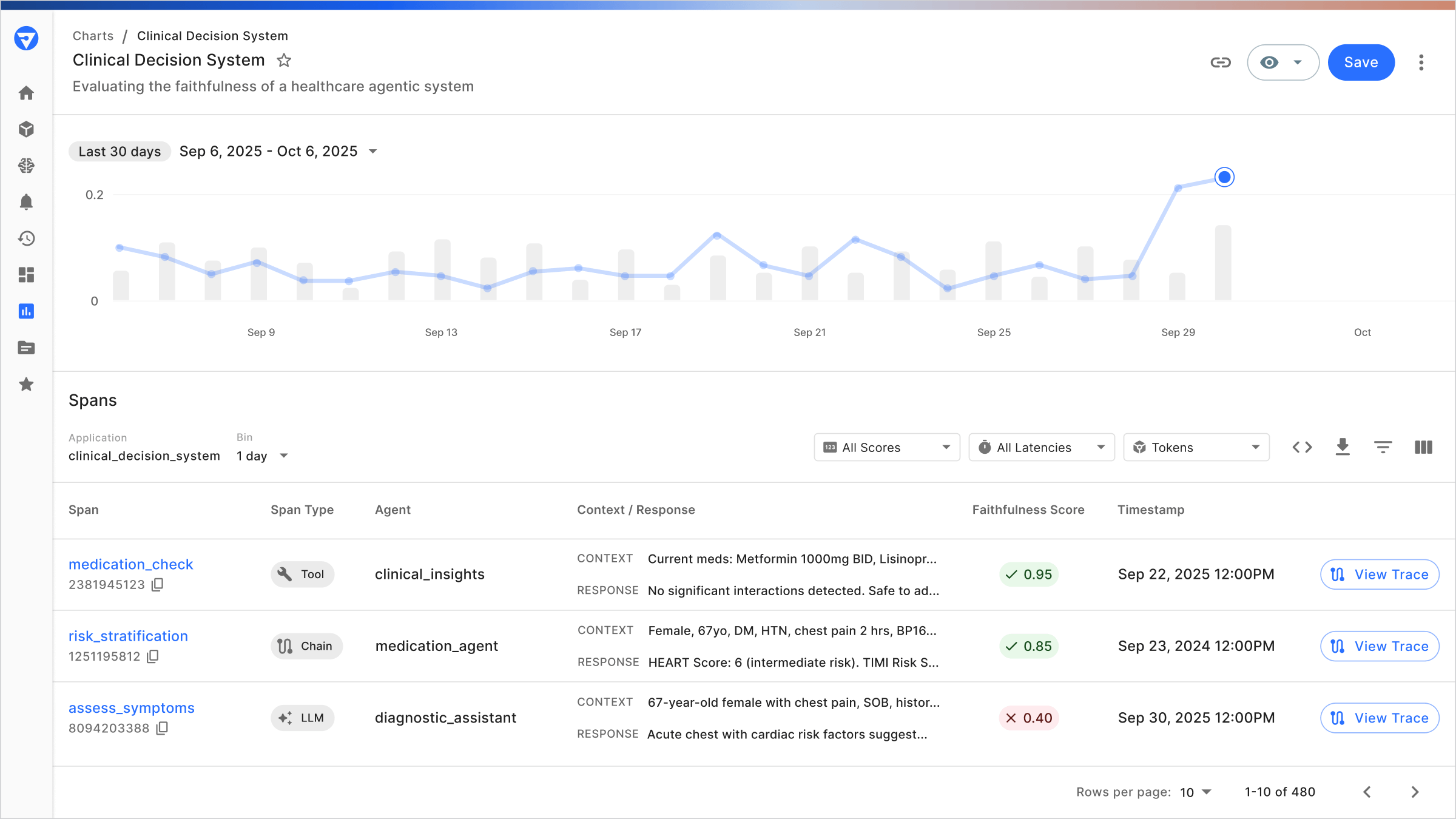
The data science team at Fiddler conducted analysis to compare key guardrails offerings in the market, and share their analyses in the Enterprise Guardrails Benchmarks Report to help organizations evaluate the real-world effectiveness of guardrail systems.
Evaluating the Effectiveness of LLM Guardrails
Effective LLM guardrails to safeguard enterprises and their end-users must operate in real time, at scale, and under demanding production conditions. Evaluators assess performance across several key dimensions, including AI guardrails velocity, which refers to how quickly guardrails process and respond to risky prompts without affecting the user experience.
- Throughput: The system must evaluate hundreds of prompts per second without compromising performance.
- Latency: Guardrail decisions should be made in under 100 milliseconds to maintain a seamless user experience.
- Accuracy: Harmful outputs must be reliably blocked, while safe and appropriate responses are allowed to pass through.
- Adaptability: Thresholds must be configurable to reflect domain-specific risk tolerances and evolving business needs.
How Guardrails Transformed a Fintech AI Assistant
Guardrails can be applied across many industries to enhance the safety and performance of AI systems.
For example, a fintech company using a generative AI assistant to handle customer inquiries may consider implementing guardrails to improve the quality and reliability of its responses. The assistant will immediately begin producing fewer toxic or misleading replies, and hallucinations across key user interactions become significantly less frequent.
These improvements would lead to a noticeable increase in customer trust and satisfaction, as users would receive more accurate and helpful answers. By continuously learning from real-time guardrail feedback, the AI system would become safer, more consistent, and better aligned with the company’s operational and customer service goals.
How Fiddler Trust Service Powers Enterprise-Grade AI Guardrails
Fiddler Trust Service is the foundation of the Fiddler AI Observability and Security Platform, built to implement guardrails, GenAI, and Agentic AI solutions for critical enterprise environments. It enables organizations to scale LLM applications confidently by monitoring user inputs and LLM outputs in real time while ensuring accurate results across complex workflows.
Core Capabilities
Fast, Accurate Scoring
- Trust Models evaluate prompts and responses in under 100 milliseconds.
- Optimized for detecting hallucinations, toxicity, sentiment issues, PII/PHI exposure, and more.
Customizable Guardrails
- Thresholds can be set to block or flag outputs based on specific business or regulatory requirements.
- Guardrail behavior is easily tailored to domains like finance, healthcare, and internal enterprise tools.
- Adding guardrails at key decision points allows teams to manage risk dynamically while maintaining model performance.
Scalable Infrastructure
- Monitors millions of prompts across hybrid cloud and VPC environments.
- Auto-scaling ensures robust performance even during periods of high traffic.
Enterprise-Ready Efficiency
- Fiddler designed Trust Models for secure, cost-effective, high-performance deployments that run entirely within the customer’s environment, eliminating the need to send data to external systems.
- Enables practical implementation of guardrails across large and complex AI ecosystems.
These capabilities make Fiddler ideal for powering secure, reliable AI agents, copilots, chatbots, and compliance-focused solutions across industries. It helps ensure that every LLM application operates safely and accurately.
Using LLM Reports to Improve AI Systems
AI LLM reports offer a clear path for improving model performance, reliability, and alignment with enterprise goals. By turning insights into action, teams can continuously strengthen their systems.
Best practices for enterprise teams include:
Incorporate Reports into Model Tuning
Use insights from top violation categories to guide retraining efforts and encourage safer, more reliable LLM outputs.
Optimize Agent Workflows
Refine prompt engineering and output formatting to reduce the frequency of flagged responses and improve the user experience.
Monitor Drift for Compliance
Review shifts in inputs and outputs regularly to ensure AI systems comply with regulatory, legal, and internal policy requirements.
Refine Guardrail Thresholds
Adjust sensitivity levels to strike the right balance between catching harmful outputs and avoiding unnecessary blocks.
Engage Cross-Functional Stakeholders
Share clear, actionable summaries with product owners, risk managers, and executive leadership to foster alignment and build trust in the system.
As enterprises expand their use of AI in critical workflows, the need for strong governance, security, and oversight becomes increasingly important. AI guardrails, supported by comprehensive metrics and reporting, are essential for managing this complexity and enabling responsible AI at scale.
Ready to strengthen your AI systems with enterprise-grade guardrails? Explore how Fiddler Trust Service enables your organization to use fast, scalable, cost-effective LLM monitoring and security.
Frequently Asked Questions About AI Guardrails
1. What are guardrails in AI metrics?
Guardrails are real-time moderation systems triggered by AI metric scores. The Fiddler Trust Service evaluates each LLM output using hallucination risk, toxicity, or PII presence metrics. These scores determine whether an output should be blocked, allowed, or flagged, protecting users and systems.
2. How do you test LLM guardrails?
Teams test guardrails by injecting risky or sensitive prompts and observing how the system responds. With Fiddler Trust Service, they simulate jailbreak attempts, prompt injections, or toxic queries and evaluate whether the system successfully intercepts harmful outputs. This approach ensures the guardrails remain robust under real-world conditions.
3. What is a guardrail KPI?
Guardrail KPIs are performance indicators that reflect the strength of an AI moderation strategy. Common examples include:
- Percentage of blocked outputs due to high-risk scores.
- Hallucination reduction rates after fine-tuning.
- Number of intercepted jailbreak attempts per week.
These KPIs inform governance, compliance, and AI risk management strategies.
