What is model performance evaluation?
4
Min Read
In machine learning, model performance evaluation uses model monitoring to assess how well a model is performing at the specific task it was designed for. There are a variety of ways to carry out model evaluation in model monitoring, using metrics like classification and regression.
Evaluating model performance is essential during model development and testing, but is also important once a model has been deployed. Continued evaluation can identify things like data drift and model bias, allowing models to be retrained for improved performance.
What is performance in machine learning?
Model performance in general refers to how well a model accomplishes its intended task, but it is important to define exactly what element of a model is being considered, and what “doing well” means for that element.
For instance, in a model designed to look for credit card fraud, identifying as many fraudulent transactions as possible will likely be the goal. The number of false positives (where non-fraudulent activity was misidentified as fraud) will be less important than the number of false negatives (where fraudulent activity is not identified). In this case, the recall of the model is likely to be the most important performance indicator. The MLOps team would then define the recall results they consider acceptable in order to determine if this model is performing well or not.
A commonly asked question is about model accuracy vs model performance, but this is a false dichotomy. Model accuracy is one way to measure model performance. Accuracy relates to the percentage of model predictions that are accurate, which is one way to define performance in machine learning. But it will not always be the most important metric of performance, depending on what the model is designed to do.
What is performance evaluation in machine learning?
Performance evaluation is the quantitative measure of how well a trained model performs on specific model evaluation metrics in machine learning. This information can then be used to determine if a model is ready to move onto the next stage of testing, be deployed more broadly, or is in need of more training or retraining.
What are the model evaluation methods?
Two of the most important categories of evaluation methods are classification and regression model performance metrics. Understanding how these metrics are calculated will enable you to choose what is most important within a given model, and provide quantitative measures of performance within that metric.
Classification metrics
Classification metrics are generally used for discrete values a model might produce when it has finished classifying all the given data. In order to clearly display the raw data needed to calculate desired classification metrics, a confusion matrix for a model can be created.
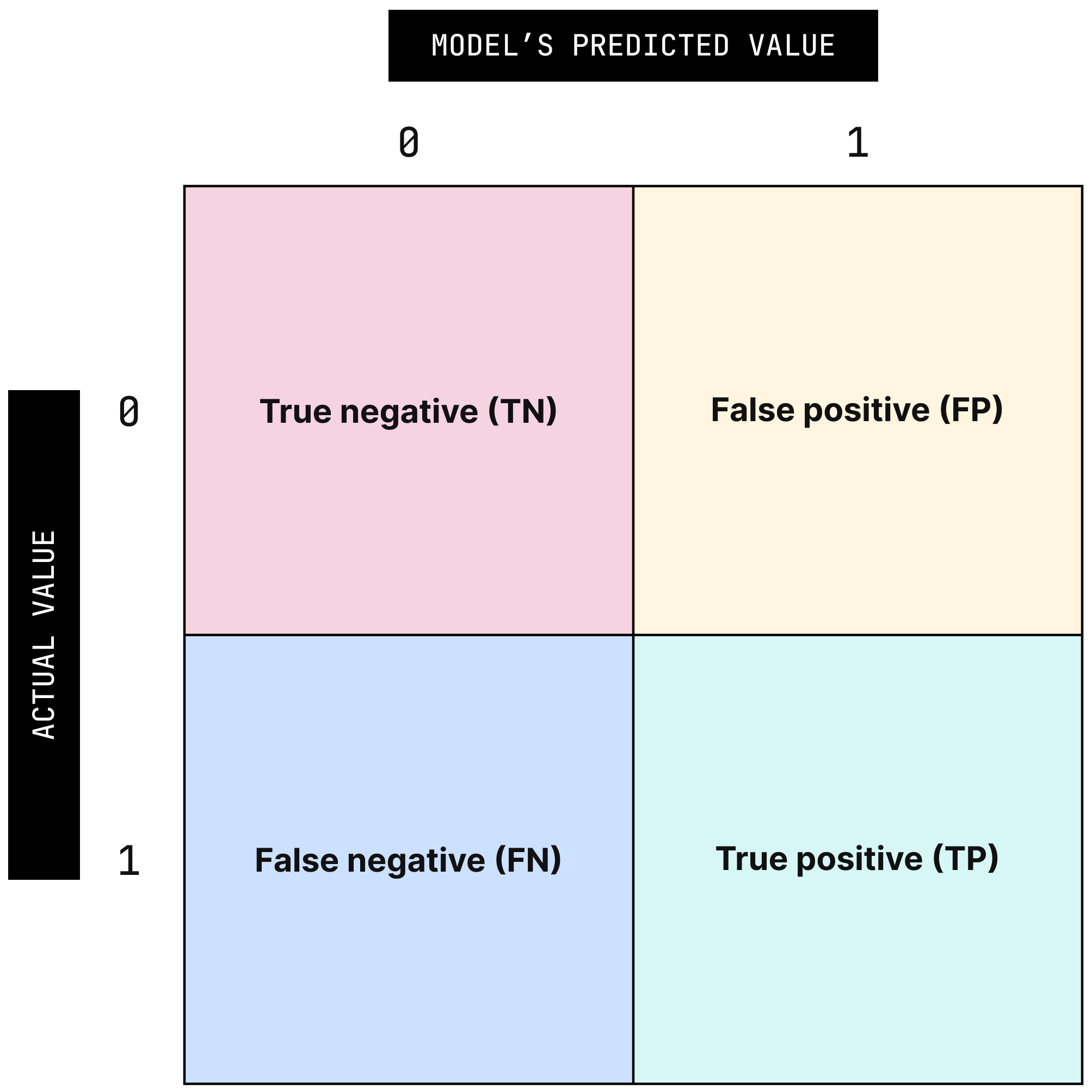
This matrix makes clear not only how often the model predictions were correct, but also in which ways it was correct or incorrect. These variables are listed in formulas as TN (true negative), FP (false positive), etc.
These are some of the most commonly useful classification metrics that can be calculated from the data contained in a confusion matrix.
- Accuracy - percentage of the total variables that were correctly classified. Use the formula Accuracy = (TP+TN) / (TP+TN+FP+FN)
- False positive rate - how often the model predicts a positive for a value that is actually negative. Use the formula False Positive Rate = FP / (FP+TN)
- Precision - percentage of positive cases that were true positives as opposed to false positives. Use the formula Precision = TP / (TP+FP)
- Recall - percentage of actual positive cases that were predicted as positives, as opposed to those classified as false negatives. Use the formula Recall = TP/(TP+FN)
- Logarithmic loss - measure of how many total errors a model has. The closer to zero, the more correct predictions a model makes in classifications.
- Area under curve - method of visualizing true and false positive rates against each other.
Regression Metrics
Regression metrics are techniques generally better suited to be applied to continuous output of a machine learning model, as opposed to classification metrics which tend to work better to analyze discrete final results.
Some of the most useful regression metrics include:
- Coefficient of determination (or R-squared) - measures variance of a model compared to the actual data.
- Mean squared error - measures the amount of average divergence of the model from the observed data.
- Mean absolute error - measures the vertical and horizontal distance between data points and a linear regression line to illustrate how much a model deviates from observed data.
- Mean absolute percentage error - shows mean absolute error as a percentage.
- Weighted mean absolute percentage error - uses actual values (rather than absolute values) to measure percentage errors.
Making model performance evaluation work for you
Machine learning models are incredibly useful and powerful tools, but they need to be trained, monitored, and evaluated regularly to produce the benefits your business wants. Choosing the most applicable predictive performance measures and tracking them appropriately takes time and expertise, but is a critical step in machine learning success.