
In the past three years, Zillow invested hundreds of millions of dollars into Zillow Offers, its AI-enabled home-flipping program. The company intended to use ML models to buy up thousands of houses per month, whereupon the homes would be renovated and sold for a profit. Unfortunately, things didn’t go to plan. Recently, news came out that the company is shutting down its iBuying program that overpaid thousands of houses this summer, along with laying off 25 percent of its staff. Zillow CEO Rich Barton said the company failed to predict house price appreciation accurately: “We’ve determined the unpredictability in forecasting home prices far exceeds what we anticipated.”
With news like Zillow’s becoming more and more frequent, it’s clear that the economic opportunities AI presents don’t come without risks. Companies employing AI face business, operational, ethical, and compliance risks associated with implementing AI. When not addressed, these issues can lead to real business impact, lack of user trust, negative publicity, and regulatory action. Companies differ widely in the scope and approach taken to address these risks, in large part due to the varying regulations governing different industries.
This is where we can all learn from the financial services industry. Over the years, banks have implemented policies and systems designed to safeguard against the potential adverse effects of models. After the 2008 financial debacle, banks had to comply with the SR 11-7 regulation, the intent of which was to ensure banking organizations were aware of the adverse consequences (including financial loss) of decisions based on AI. As a result, all financial services businesses have implemented some form of model risk management (MRM).
In this article, we attempt to describe what MRM means and how it could have helped in Zillow’s case. Model risk management is a process to assess all the possible risks that organizations can incur due to decisions being made by incorrect or misused models. MRM requires understanding how a model works, not only on existing data but on data not yet seen. As organizations adopt ML models that are increasingly becoming a black box, models are becoming harder to understand and diagnose. Let us examine carefully what we need to understand and why. From regulation SR 11-7: Guidance on Model Risk Management:
Model risk occurs primarily for two reasons: (1) a model may have fundamental errors and produce inaccurate outputs when viewed against its design objective and intended business uses; (2) a model may be used incorrectly or inappropriately or there may be a misunderstanding about its limitations and assumptions. Model risk increases with greater model complexity, higher uncertainty about inputs and assumptions, broader extent of use, and larger potential impact.
Therefore, it is paramount to understand the model to mitigate the risk of errors, specifically when used in an unintended way, incorrectly, or inappropriately. Before we dive into the Zillow scenario, it’s best to clarify that this is not an easy thing to solve in an organization — implementing model risk management isn’t just a matter of installing a Python or R package.
Model Risk in Zillow’s case
As user @galenward tweeted a few weeks ago, it would be interesting to find out where in the ML stack Zillow's failure lives:
- Was it an incorrect or inappropriate use of ML?
- Too much trust in ML?
- Aggressive management that wouldn't take "we aren't ready" for an answer?
- Wrong KPIs?
We can only hypothesize what could have happened in Zillow’s case. But since predicting house prices is a complex modeling problem, there are four areas where we’d like to focus in this article:
- Data Collection and Quality
- Data Drift
- Model Performance Monitoring
- Model Explainability
Data Collection and Quality
One of the problems, when we model things that are asset-valued, is that they depreciate based on human usage, and it becomes fundamentally hard to model them. For example, how can we get data into how well a house is being maintained? Let’s say there are two identical houses in the same zip code, where each is 2,100 square feet and has the same number of bedrooms and bathrooms — how do we know one was better maintained than the other?
Most of the data in real estate seem to come from a variety of MLS data sources which are maintained at a regional level and are prone to variability. These data sources collect home condition assessments, including pictures of the house and additional metadata. Theoretically, a company like Zillow could apply sophisticated AI/ML techniques to assess the house quality. However, there are so many hundreds of MLS boards and the feeds from different geographies can have data quality issues.
Additionally, there are global market conditions such as interest rates, GDP, unemployment, and supply and demand in the market that could affect home prices. Let's say the unemployment rate is really high, so people aren't making money and can't afford to pay their mortgages. We would have a lot of houses on the market because of an excess of supply and a lack of demand. On the flip side, if unemployment goes down and the economy is doing well, we might see a housing market boom.
There are always going to be things that impact a home price that can't be easily measured and included in a model. The question here is really twofold: First, how should a company like Zillow collect data on factors that would affect prices, from a specific home’s condition to the general condition of the economy? And second, how should the business understand and account for data quality issues?
Data Drift
The world is changing constantly with time. Although the price of a house may not vary much day-to-day, we do see price changes over periods of time happen due to house depreciation as well as market conditions. This is a challenge to model. While it’s clear that the prices over time follow a non-stationary pattern, it’s also hard to gather a lot of time series data on price fluctuations around a single home.
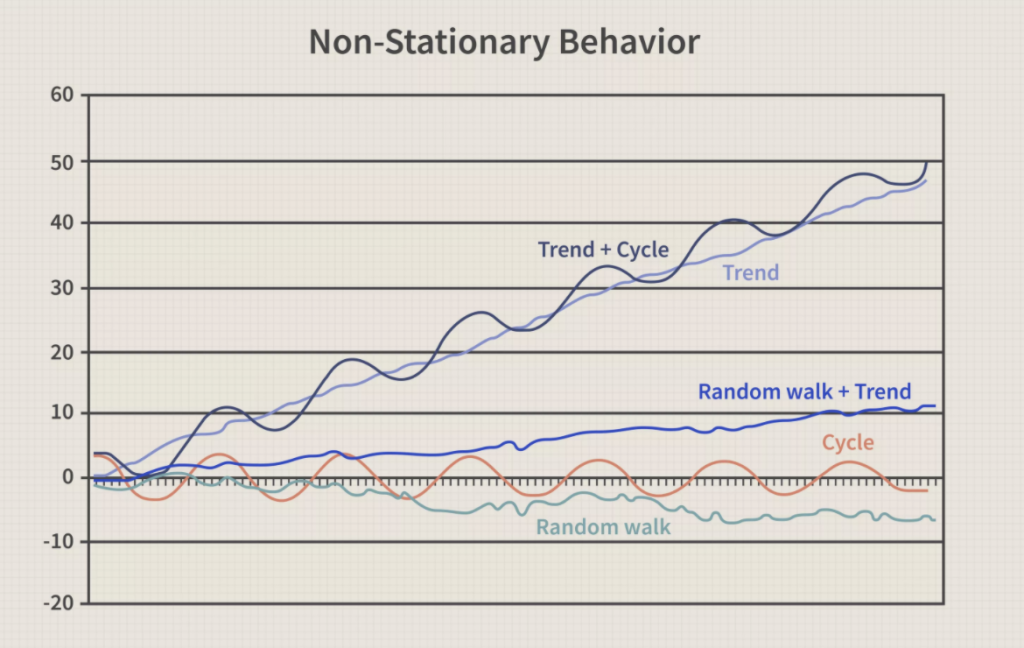
So, teams generally resort to looking at cross-sectional data on house-specific variables such as square footage, year built, or location. Cross-sectional data refer to observations of many different data points at a given time, each observation belonging to a different data point. In the case of Zillow, cross-sectional data would be the price for each of 1,000 randomly chosen houses in San Francisco for the year 2020.
Cross-sectional data is, of course, generalized historical data. This is where risk comes in, because implicit in the machine learning process of dataset construction, model training, and model evaluation is the assumption that the future will be the same as the past. This assumption is known as the stationarity assumption: the idea that processes or behaviors that are being modeled are stationary through time (i.e., they don't change). This assumption lets us easily use a variety of ML algorithms from boosted trees, random forests, or neural networks to model scenarios—but it exposes us to potential problems down the line.
If (as is usually the case in the real world) the data is not stationary, the relationships the model learns will shift with time and become unreliable. Data scientists use a term called data drift to describe how a process or behavior can change, or drift, as time passes. In effect, ML algorithms search through the past for patterns that might generalize to the future. But the future is subject to constant change, and production models can deteriorate in accuracy over time due to data drift. There are three kinds of data drift that we need to be aware of: concept drift, label drift, and feature drift. One or more of these types of data drift could have caused Zillow’s models to deteriorate in production.
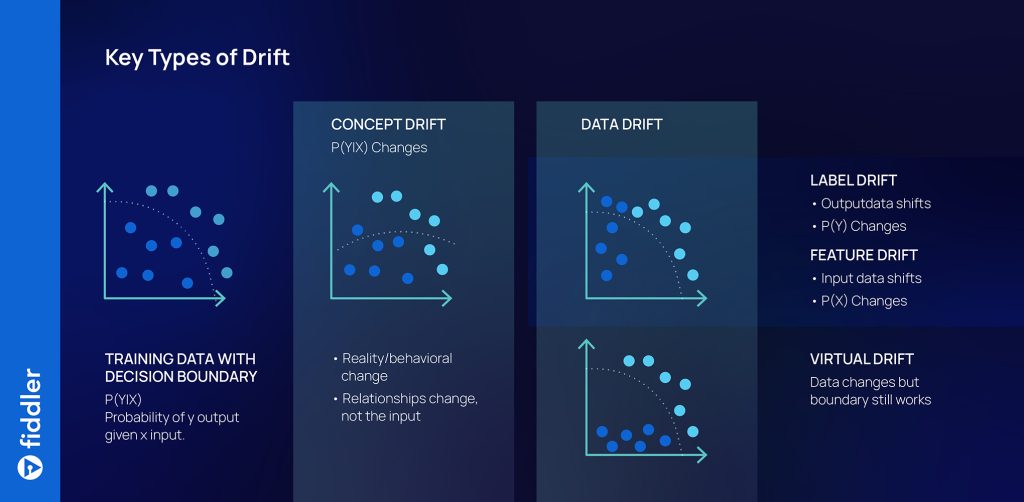
Model Performance Monitoring
Model performance monitoring is essential, especially when an operationalized ML model could drift and potentially deteriorate in a short amount of time due to the non-stationary nature of the data. There are a variety of MLOps monitoring tools that provide basic to advanced model performance monitoring for ML teams today. While we don’t know what kind of monitoring Zillow had configured for their models, most solutions offer some form of the following:
- Performance metric tracking: Metrics like MAPE, MSE, etc. could be tracked in a central place for all business stakeholders, with alerting set up so that if model performance crossed a threshold for any of these metrics, the team could take action immediately.
- Monitoring for data drift: By tracking the feature values, shifts in the feature data, and how the feature importances might be shifting, the team can have indicators for when the model might need to be retrained. Additionally, in Zillow’s case it would have been a good idea to also monitor for changes in macroeconomic factors like unemployment rate, GDP, and supply and demand across different geographical regions.
Model Explainability
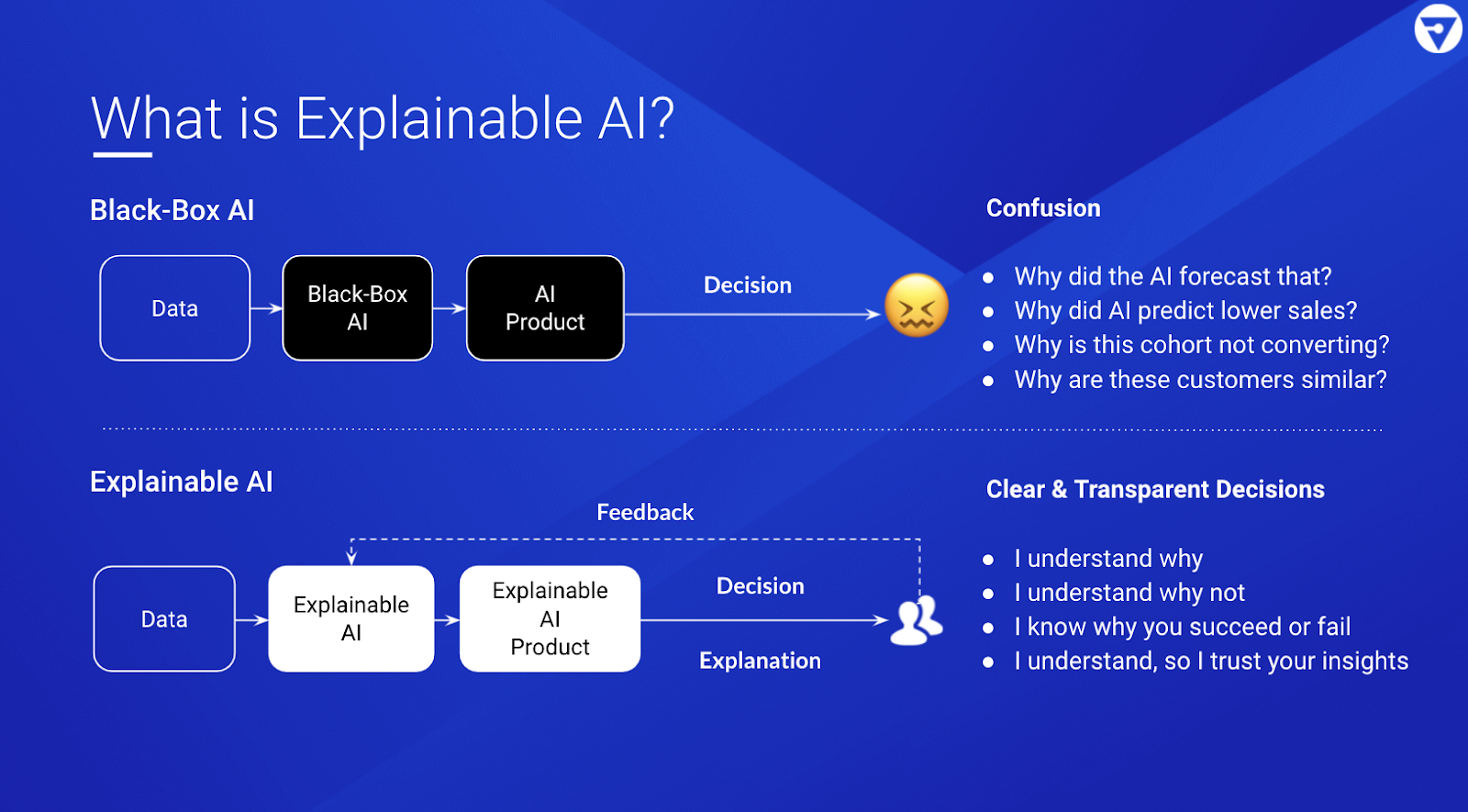
While we don’t know much about Zillow’s AI methodologies, they seem to have made some investments in Explainable AI. Model explanations help provide more information and intuition about how a model operates, and reduce the uncertainty that it will be misused. There are both commercial and open-source tools available today to give teams a deeper understanding of their models. Here are some of the most common explainability techniques along with examples of how they might have been used in Zillow’s case:
Local instance explanations: Given a single data instance, quantify each feature’s contribution to the prediction.
- Example: Given a house and its predicted price of $250,000, how important was the year of construction vs. the number of bathrooms in contributing to its price?
Instance explanation comparisons: Given a collection of data instances, compare the factors that lead to their predictions.
- Example: Given five houses in a neighborhood, what distinguishes them and their prices?
Counterfactuals: Given a single data instance, ask “what if” questions to observe the effect that modified features have on its prediction.
- Example: Given a house and its predicted price of $250,000, how would the price change if it had an extra bedroom?
- Example: Given a house and its predicted price of $250,000, what would I have to change to increase its predicted price to 300,000 dollars?
Nearest neighbors: Given a single data instance, find data instances with similar features, predictions, or both.
- Example: Given a house and its predicted price of $250,000, what other houses have similar features, price, or both?
- Example: Given a house and a binary model prediction that says to “buy,” what is the most similar real home that the model predicts “not to buy”?
Regions of error: Given a model, locate regions of the model where prediction uncertainty is high.
- Example: Given a house price prediction model trained mostly on older homes ranging from $100,000 – 300,000, can I trust a model’s prediction that a newly built house costs 400,000 dollars?
Feature importance: Given a model, rank the features of the data that are most influential to the overall predictions.
- Example: Given a house price prediction model, does it make sense that the top three most influential features should be the square footage, year built, and location?
For a high-stakes use-case like Zillow’s, where a model’s decisions could have a huge impact on the business, it's important to have a human-in-the-loop ML workflow with investigations and corrections enabled by explainability.
Conclusion
AI can help grow and scale businesses and generate fantastic results. But if we don’t manage risks properly, or markets turn against the assumptions we have made, then outcomes can go from bad to catastrophic.
We really don't know Zillow's methodology and how they managed their model risk. It’s possible that the team’s best intentions were overridden by aggressive management. And it’s certainly possible that there were broader operational issues—such as the processes and labor needed to flip homes quickly and efficiently. But one thing is clear: It’s imperative that organizations operating in capital-intensive spaces establish a strong risk culture around how their models are developed, deployed, and operated.
In this area, other industries have much to learn from banking, where regulation SR 11-7 provides guidance on model risk management. We’ve covered four key areas that factor into model risk management: data collection and quality, data drift, model performance monitoring, and explainability.
Robust model risk management is important for every company operationalizing AI for their critical business workflows. ML models are extremely hard to build and operate, and much depends on our assumptions and how we define the problem. MRM as a process can help reduce the risks and uncertainties along the way.