
Whenever models underperform, MLOps teams often start troubleshooting by checking on the usual suspects like performance metrics and data drift. What they often miss though is that models can decay in silence because data integrity isn't well maintained or routinely checked to ensure there aren’t any data issues. Model underperformance may have nothing to do with the quality of the model or changes in production data; instead broken data pipelines, missing data, or other data issues may be impacting the model.
ML models rely on using complex feature pipelines and automated workflows to transform data and shape it into the right form for consumption. These transformations need to be consistently applied to all data of the same kind along the ML pipeline.
Some models ingest data from multiple pipelines at different speeds and volumes (batch vs. streaming), and the format of the data may differ from system to system. As a result, models will often ingest data with inconsistencies and errors. Unless data is routinely checked for these inconsistencies and errors, models will provide subpar predictions without realizing that there are issues with the data. Without a standard way of monitoring for data integrity, these errors tend to go undetected and cause models to silently decay over time.
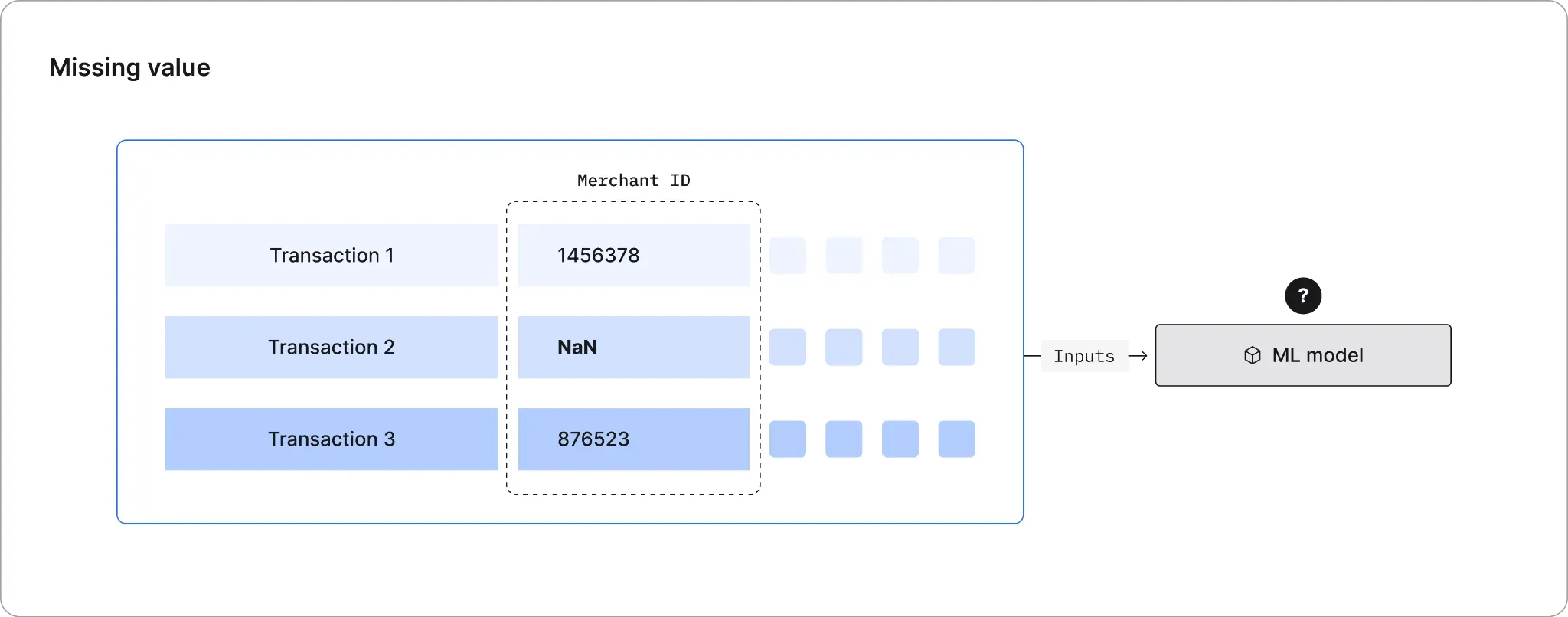
Monitoring Types of Data Integrity
Bad data can have a significant impact on the performance of ML models whether in training or in production. Data engineers spend a lot of time in feature engineering to ensure that a training set has good data quality to train the best representative model possible. During feature engineering, data engineers replace bad data with good data using a consistent set of rules: dropping rows with missing values, allowing missing values, setting missing categorical values as a unique values, imputing missing values, replacing missing values with a statistical representation (e.g. mean) or defaulting to some value.
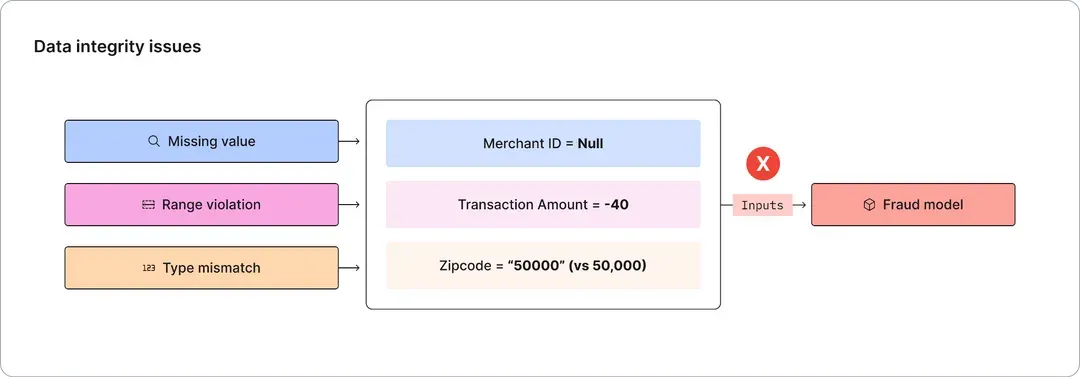
Models in production face three types of data integrity problems:
- Missing value: A feature input is null or unavailable at inference time. An example of a missing value error is an ML model making an inference based on a form input where a previously optional field is now always sending a null value input due to a code error.
- Range violation: A feature input is either out of expected bounds or is a known error. Range violation happens when the model input exceeds the expected range of its values. It's quite common for categorical inputs to have typos and cardinality mismatches to cause this problem, such as free form typing for categories and numerical fields like age, etc.
- Type mismatch: Inputs of a different data type are passed in. Type mismatch happens when the model input type is different from the one provided at inference time. One way types get mismatched is when column order gets misaligned during some data wrangling operations.
Handling Data Issues
There are several ways to handle bad production data but many can create their own problems:
- Discard inference requests: Models can make inaccurate predictions or skip making a prediction altogether to avoid making an erroneous prediction if they ingest bad data. For low-stakes use cases, avoiding a prediction is a quick and simple solution. But for important decisions, avoiding a prediction isn't an option.
A product recommendation service, for example, can skip making a recommendation or provide a less-desired recommendation to a customer, and neither the business nor the customer will be greatly impacted. In healthcare, on the other hand, making an erroneous prediction can be life-threatening, and can impact whether or not a patient receives timely medical treatment. - Impute or predict missing values: When a value is missing, it can be replaced with an estimated value with either the ‘mean’ of the feature or a more complex predicted value based on other model inputs. This approach accelerates data drift when bad data is consistently replaced, and it could be very difficult to catch.
- Set default values: When the value is out of range, it can be replaced by a known high or low or unique value, such as replacing a very high or low age with the closest minimum or maximum value. This approach can also cause gradual drift that negatively impacts performance.
- Acquire missing data: ML teams may resort to acquiring missing data but it’s a highly uncommon practice. In some business critical ML projects, like lending, ML teams may fill the gap by acquiring missing data.
- Do nothing: This is the simplest and likely the best approach to take depending on the criticality of your ML use case. The bad data can be resolved since it will surface upstream or downstream, and most inference engines will return an error depending on the algorithm used to train the model. A prediction made on bad data can show up as an outlier of either the output or the impacted input, helping surface the issue.
Given all the data challenges that may occur, having model monitoring alerts in place helps catch and address these issues immediately.
How to Catch Data Integrity Issues
Performing data checks is cumbersome, especially when more data and features are added over time. Thorough and routine data checks are needed to identify any missing values, type mismatches, or range violations.
A quick way to perform these checks is to use a representative data sample from the training set and set up a job that regularly assesses data against these rules in the background. This helps detect any data violations for issue resolution to minimize the impact it causes on model predictions.
How to Assess and Minimize Data Integrity Issues
When data failures are caught (many go undetected for a few weeks or sometimes longer), it’s important for teams to prioritize fixes by understanding which data violations have the most impact on model performance. Choosing to not resolve issues can lead to major unintended consequences, especially given the brittle nature of ML models.
Start assessing data:
- Analyze data at the local-level: Diagnose the root cause at the local-level and get context on how the data violations are affecting model predictions using explainable AI. However, it can be time consuming to recreate all of the factors that led to an issue, especially if the data or model have since changed. The data in question may not have been stored with the input query and may need to be recreated. It's hard to get the same results if the model version hasn't been properly updated.
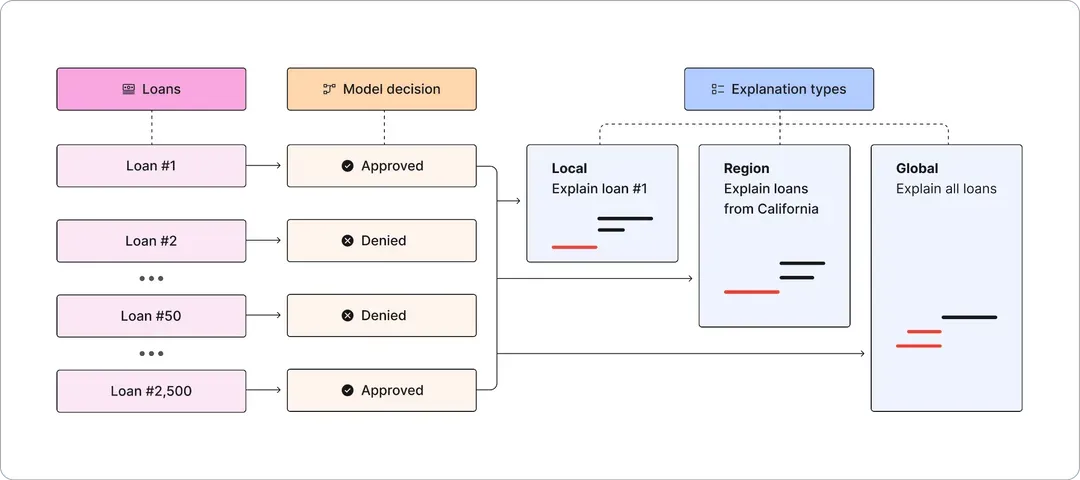
- Analyze data globally: For global issues, the troubleshooting scope includes understanding the data issue's severity. This involves analyzing the data over a longer time period to see when the issue might have started. For example, data changes usually happen with major changes or updates, like product launches, new marketing campaigns, etc. So querying for data change timelines can help tie the issue to a specific code and data release. This helps revert or address it quickly.
Data issues show up as a data drift in the model input and, depending on its impact, a corresponding drift in the output. Analyzing data drift is a useful approach to identify the cause of the data integrity issue. This is particularly relevant when data is imputed because of an integrity issue - in this case, the composition of the input data will shift even though it might not trigger integrity violations
These steps typically help to pinpoint and assess data issues in the pipeline. Given how involved this troubleshooting process can be, ML teams struggle to quickly address data integrity problems without a robust model monitoring solution.
Data integrity is an essential component for the success of ML models and applications, and continuous monitoring for data integrity, as well as data drift and performance, can quickly detect anomalies in the data that can negatively impact model predictions.
Monitor ML models and detect any data anomalies using Fiddler. Request a demo