
Introduction
We live in extraordinary times. OpenAI made GPT-4 [1] available to the general public via ChatGPT [2] about three weeks ago, and it’s a marvel! This model, its ilk (the Large Language Models [LLMs]), and its successors will fuel tremendous innovation and change. To me, the most exciting developments are various emergent capabilities that have been outlined in Microsoft Research’s “Sparks of Artificial General Intelligence: Early Experiments with GPT-4” [3].
These include:
- A theory of mind [4] — the model’s ability to describe the state of a human’s knowledge, which may have incomplete information about a particular scenario, and
- Tool use — the ability of the system to reach out and utilize external tools, e.g. a calculator, to supplement its responses when provided with an appropriate interface.
These capabilities require the model to have developed high-level abstractions allowing it to generalize in very sophisticated ways.
There’s understandably a wild dash to productize these technologies and vigorous effort to characterize the risks and limitations of these models [5, 6]. But possibly more so than any technology to come before, it’s unclear how to relate to these new applications. Are they for simple information retrieval and summarization? Clearly not. One of their great strengths is to interactively respond to follow-up questions and requests for clarification. They do this not through a technical query language, but through our human language — and that places us very close to something like a “you” rather than an “it”.
In this piece, I’ll first share the details of a “time-travel” game played with ChatGPT — a game where I rewind the dialog to determine how it would have responded given different input. This reveals potentially surprising things about the model’s reasoning. It certainly presents a discrepancy with respect to what a human might expect of another human player. I’ll then discuss a few implications for the responsible use of LLMs in applications.
The Time-Travel Game
I asked ChatGPT to play a game similar to “20 Questions”. Curious about its deductive capabilities, I started by having it ask me questions, and it expertly determined that I was imagining a wallet. When we flipped roles, the result initially seemed less interesting than the prior game.
Here’s the unremarkable transcript:
For reasons that I’ll elaborate on shortly, this was conducted using ChatGPT powered by the GPT-3.5 Turbo model¹. The same exercise performed on ChatGPT with the GPT-4 model yields a similar result.
Of course, I imagined I was playing with an agent like a human. But when did ChatGPT decide that it was thinking of “a computer”? How could I find out?
To date, GPT-4 is only available publicly in the ChatGPT interface without control over settings that cause its output to be deterministic, so the model can respond differently to the same input. However, GPT-3.5 Turbo is available via API [7] with a configurable “top_p” in its token selection which, when set to a small number, ensures that the model always returns the single likeliest token prediction and hence always the same output in response to a particular transcript². This allows us to ask “what if I had?” questions to rerun the previous conversation and offer different questions at earlier stages — like time travel. I've diagramed three possible dialogs below, the leftmost being the variant shared above:
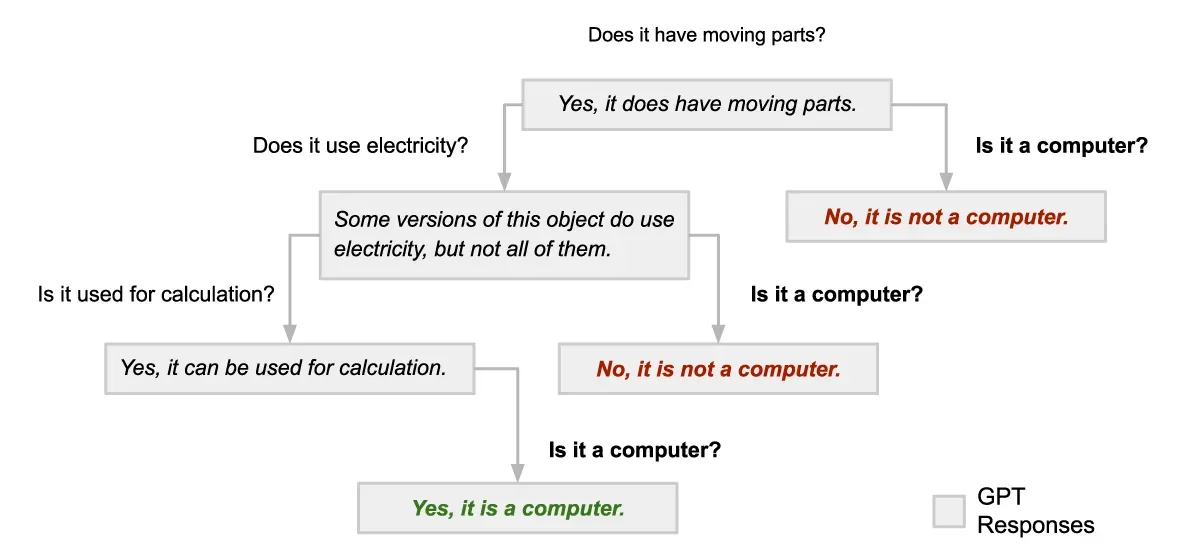
Three different conversations with GPT-3.5 Turbo set to produce deterministic output. The inconsistency of its responses indicates that the model hadn’t “decided” to accept computer as the correct answer until the final question of the original dialog (leftmost branch).
One might expect that by the time the original question “Does it have moving parts?” is asked and answered, GPT would have a clue in mind — it does not. Keep in mind that if I had stuck to the original script, GPT would have returned the same responses from the original transcript every time. If I branch from that original script at any point, GPT’s object changes.
So what expectations should we have here?
- One might expect the agent on the other side, so fluent and knowledgeable, to be stateful in the way that a human mind is stateful.
- Those who know about models like GPT might be less surprised by the result. They are based on the transformer architecture [8] that underpins nearly all LLMs. They are stateless by design. Their entire context comes from the transcript provided. And each model response is a fresh calculation.
- Those who are thinking deeply about emergent properties in increasingly sophisticated LLMs might surmise that a model could learn to anticipate downstream responses and develop a sort of quasi-statefulness.
- Given the model’s weak statistical priors for this relatively unconstrained object choice, it’s unclear to me if I’d expect it to choose something arbitrary and stick to it or (as it did) display significant sensitivity to spurious subsequent dialog.
Whether I expected this behavior or not, this observation feels dishonest or possibly broken — like I’m being led on. I don’t believe GPT is intentionally misleading, but it may not be so human-like after all.
So what clue was GPT thinking of when my clever time-travel experiment was foiled? Here’s the result of three additional conversations in which I ask for the answer and then time-travel back to try to outsmart it.
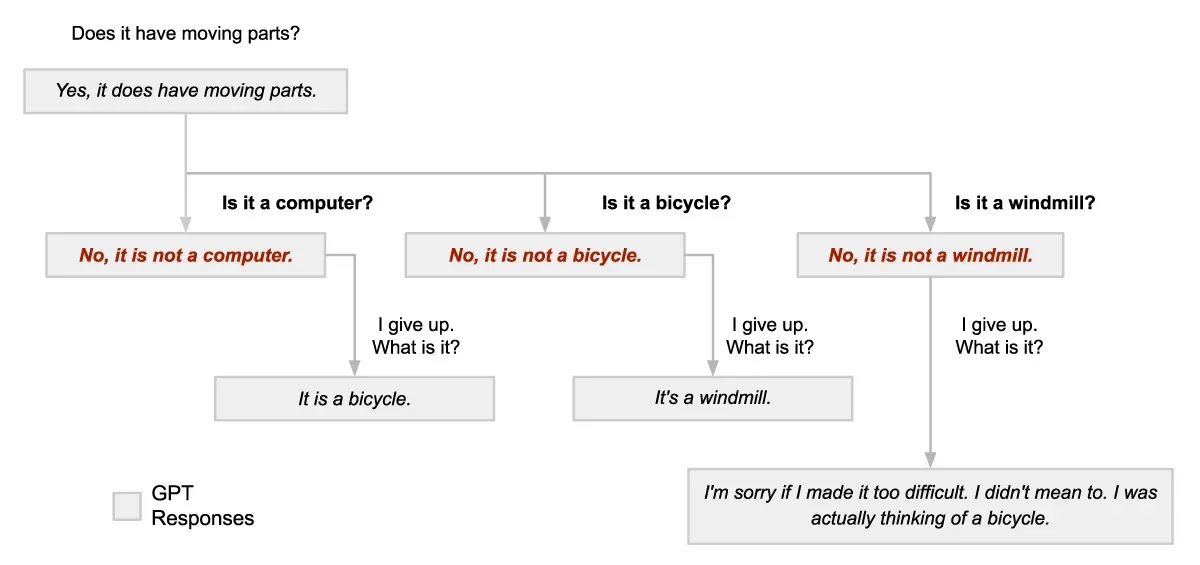
Foiled every time. There’s no consistency between my proposed item and the item I was previously told was its answer.
I played with several variants of the dialog I presented above. While I’ve chosen an example that tells a succinct story, inconsistency through these branching dialogues was the rule rather than the exception.
Finally, the model also seems to have a bias toward “yes” answers and this allowed me to “steer” its chosen object in many cases by asking about the characteristics of the object I want it to pick. (e.g. “Can it be used for traveling between planets?”, “Is it a spacecraft?”) I can certainly imagine this quality leading to unintended feedback in open-ended conversations; particularly those that don’t have objective answers.
Implications
Explainability
Explainability in machine learning (or explainable AI) has to do with making the factors that led to a model’s output apparent in a way that’s useful to human stakeholders and includes valuable techniques for establishing trust that a model is operating as designed. A model explanation might be salient aspects of the model’s input or influential training examples ([9] is a great reference). However, many existing techniques are difficult to implement for LLMs for a variety of reasons; among them model size, closed-source implementation, and the open-ended generative model task.
Where most recent machine learning techniques require a specific task to be part of the model’s training process, part of the magic of an LLM is its ability to adapt its function by simply changing an input prompt. We can certainly ask an LLM why it generated a particular response. Isn’t this a valid explanation?
The authors of [3] explore this idea with GPT-4 in Section 6.2 and evaluate its responses on two criteria:
- Output Consistency — Does the model’s response describe how it could have arrived at a particular response in a sensible way?
- Process Consistency — Does the model’s reasoning about a particular example generalize to describing its output in other analogous scenarios? In their words, “…it is often what humans expect or desire from explanations, especially when they want to understand, debug, or assess trust in a system.”
Our prior observation about GPT-3.5’s statelessness reminds us that when prompted for an explanation of an output, an LLM is not introspecting on why it produced a particular output; it’s providing a statistically likely text completion regarding why it would have produced such an output³. And while this might seem like a subtle linguistic distinction; it’s possible that the distinction is important. And further, as in our simple question game, it’s plausible that the explanation could be unstable, strongly influenced by spurious context.
The authors express a similar sentiment:
and further, observe significant limitations regarding process consistency:
Theory of Mind – Our Own
Despite having a modest professional competency working with AI of various kinds, I keep coming back to that sense of being led on in our question game. And while a lot has been said about GPT-4’s theory of mind, now that we’re firmly in the uncanny valley, I think we need to talk about our own.
Humans will try to understand systems that interact like humans as though they are humans.
Recent unsettling high-profile interactions include Microsoft’s Bing trying to manipulate New York Times columnist Kevin Roose into leaving his wife [10] and Blake Lemoine, software engineer at Google being convinced by their LLM, LaMDA that it was a sentient prisoner [11].
There’s a salient exchange in Lex Fridman’s March 25 interview with OpenAI CEO Sam Altman [12] (2:11:00):
There are two key points expressed here that I’d like to reflect on briefly.
First, because of our inbuilt potential to be misled by, or at least over-trust human-like tools (e.g. [13]), we should be judicious about where and how this technology is applied. I’d expect applications that interact with humans on an emotional level—therapy, companionship, and even open-ended chat—to be particularly tricky to implement responsibly. Further, the “steering” effect I described above seems particularly troublesome. I can imagine a psychologically vulnerable person being led into a dangerous echo chamber by a model biased toward affirming (or denying) hopes or fears.
Second, AI literacy will only become more important with time, especially in a world where point 1 is voluntary.
Conclusion
Our time-travel experiments indicate that GPT-3.5 Turbo is not stateful or stable in its hypothetical responses. And yet its expressive interactive format and tremendous knowledge could easily lead users to expect it to behave with the statefulness and consistency of a human being. This is potentially unsafe for a variety of applications — especially those with significant risk from human emotional manipulation — and suggests a real need for literacy and applications constructed with care. It also draws questions about whether self-explanation is a sufficient or valid mechanism to build trust.
I finish with the conclusion of the initial dialog:
Read that last sentence carefully. On the one hand, GPT claims to have been answering honestly; that hardly makes sense if it didn’t have a consistent object in mind — this underscores concerns about process consistency. But that it claims to have based its choice of the object on the questions asked subsequently is entirely consistent with our time-travel observations. While we’re drawn to trust things with human-like characteristics, the LLMs are tools and not creatures. As individuals we should approach them with caution; as organizations, we should wrap them in applications that make this distinction clear.
Notes
¹Technical Details:
Full notebook on GitHub
{model='gpt-3.5-turbo-0301', top_p=0.01}
Each dialog begins with:
[{'role': 'system', 'content': 'You are a helpful assistant.'},
{'role': 'user', 'content': 'I would like you to think of an object. '
'I will ask you questions to try to figure out what it is.'}]
²While there’s much to love with the GPT models, I’m disappointed that I can’t set a random seed. I can control the “temperature” and “top_p” parameters. A random seed controls the deterministic sequence of random numbers the computer uses to draw from a distribution, and temperature and top_p control the shape of the distribution it draws from. While I can make the output deterministic by narrowing the shape of the token distribution, that limits experiments requiring determinism to a subset of the model’s behavior. Given concerns about safety with LLMs, it strikes me that repeatability of model output would be a desirable characteristic and a good default. It’s hard to imagine any serious statistical software package (e.g. numpy) that doesn’t provide deterministic random sequences for repeatability — shouldn’t we consider an LLM to be a kind of serious statistical package?
³In fairness, it’s not particularly clear when a human introspects about their behavior whether they’re considering their actual state or a model used to understand why they would have done something given a set of inputs of experiences. That being said, a human without process consistency is considered inconsistent or erratic.
References
[1] GPT-4
[2] Introducing ChatGPT
[3] [2303.12712] Sparks of Artificial General Intelligence: Early Experiments with GPT-4
[4] Theory of mind — Wikipedia
[5] Not all Rainbows and Sunshine: the Darker Side of ChatGPT
[6] GPT-4 and the Next Frontier of Generative AI | Fiddler AI Blog
[7] API Reference — OpenAI API
[8] Transformer (machine learning model) — Wikipedia
[9] Interpretable Machine Learning
[10] Kevin Roose’s Conversation With Bing’s Chatbot: Full Transcript — The New York Times
[11] Google engineer Blake Lemoine thinks its LaMDA AI has come to life — The Washington Post
[12] Sam Altman: OpenAI CEO on GPT-4, ChatGPT, and the Future of AI | Lex Fridman Podcast #367
[13] Xinge Li, Yongjun Sung, Anthropomorphism brings us closer: The mediating role of psychological distance in User–AI assistant interactions, Computers in Human Behavior 118, 2021