- SHAP and Integrated Gradients (IG) are both popular methods for explaining AI model predictions, but they differ in how they compute feature importance.
- Use IG for differentiable models like neural networks and logistic regression, as it is computationally efficient and faster than Shapley-based methods.
- For non-differentiable models like decision trees, use Shapley-based methods like Tree SHAP, as they provide accurate attributions without requiring model gradients.
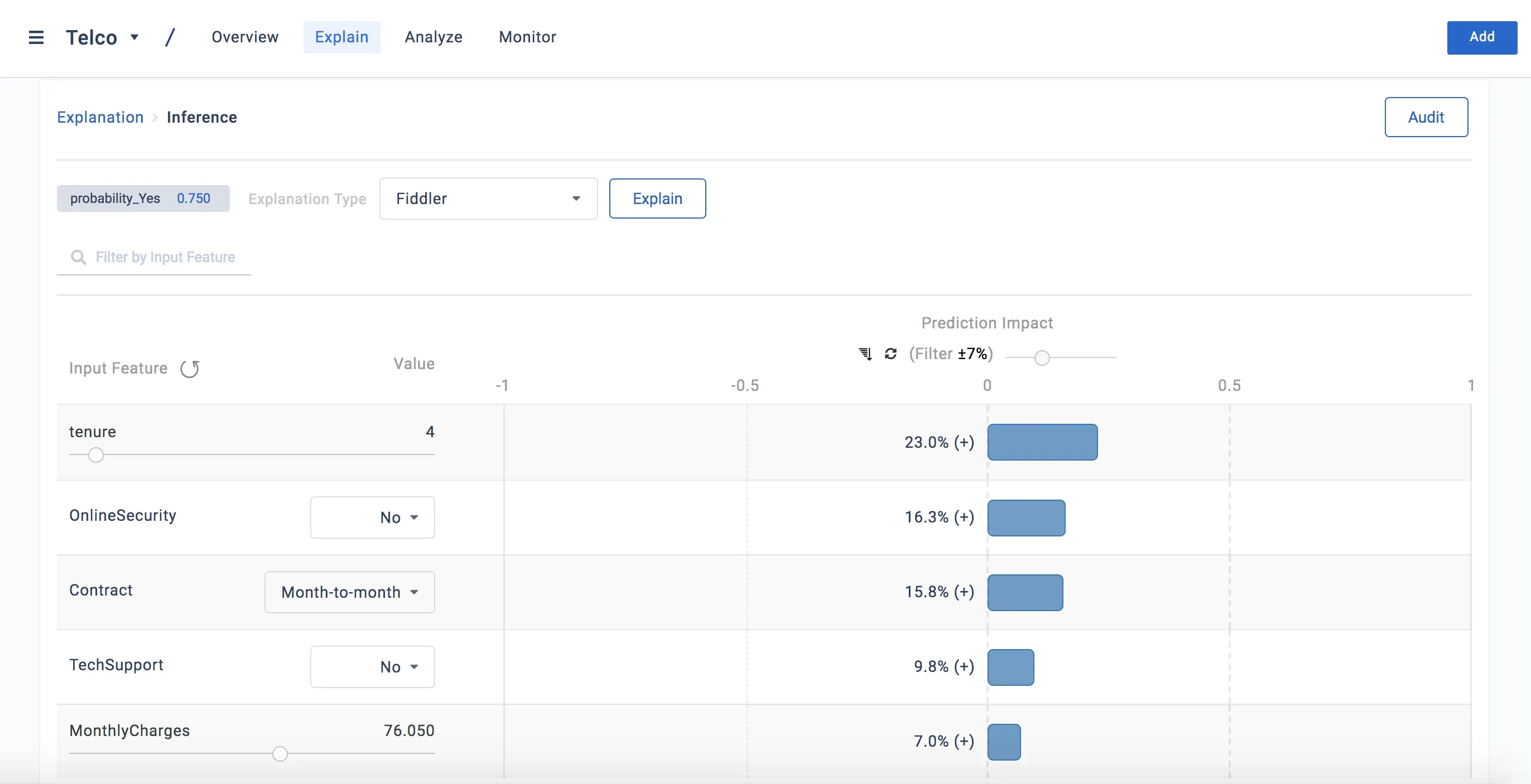
- Fiddler supports SHAP and IG, offering flexibility in choosing the best explanation method based on your model type.
Some of the most accurate predictive models today are opaque models, meaning it is hard to really understand how they arrive at decisions. To enhance transparency, explainable AI techniques have emerged to analyze feature importance—determining how much for a given prediction, each input feature contributes to a given prediction. Two well-known techniques are SHapley Additive exPlanations (SHAP) and Integrated Gradients (IG). In fact, they each represent a different type of explanation algorithm: a Shapley-value-based algorithm (SHAP) and a gradient-based algorithm (IG).
When comparing integrated gradients vs SHAP, a key distinction arises in how they compute features attributions. This post describes that difference. First, we need some background. Below, we review Shapley values, Shapley-value-based methods (including SHAP explainability), and gradient-based methods (including IG). Finally, we get back to our central question: When should you use a Shapley-value-based algorithm (like SHAP) versus a gradient-based explanation explanation algorithm (like IG)?
What are Shapley Values?
The Shapley value (proposed by Lloyd Shapley in 1953) is a classic method to distribute the total gains of a collaborative game to a coalition of cooperating players. It is probably the only distribution with certain desirable properties.
In the context of machine learning, SHAP values measure the contribution of each feature to a model’s prediction. We can formulate this as a game for each prediction instance, where the “total gains” represent the prediction value, and the “players” are the model's features. The collaborative game is all of the model features cooperating to form a prediction value. The Shapley value efficiency property says the feature attributions should sum to the prediction value. The attributions can be negative or positive, since a feature can lower or raise a predicted value.
There is a variant called the Aumann-Shapley value, extending the definition of the Shapley value to a game with many (or infinitely many) players, where each player plays only a minor role, if the worth function (the gains from including a coalition of players) is differentiable.
What is a Shapley Value-Based Explanation Method?
A Shapley value-based explanation method tries to approximate Shapley values of a given prediction by examining the effect of removing a feature under all possible combinations of presence or absence of the other features. In other words, this method looks at function values over subsets of features like F(x1, <absent>, x3, x4, …, <absent>, …, xn). How to evaluate a function F with one or more absent features is subtle.
For example, SHAP (SHapely Additive exPlanations) estimates the model's behavior on an input with certain features absent by averaging over samples from those features drawn from the training set. In other words, F(x1, <absent>, x3, …, xn) is estimated by the expected prediction when the missing feature x2 is sampled from the dataset.
Exactly how that sample is chosen is important (for example marginal versus conditional distribution versus cluster centers of background data), but I will skip the fine details here.
Once we define the model function (F) for all subsets of the features, we can apply the Shapley values algorithm to compute feature attributions. Each feature’s Shapley value is the contribution of the feature for all possible subsets of the other features.
The “kernel SHAP” method from the SHAP paper computes the Shapley values of all features simultaneously by defining a weighted least squares regression whose solution is the Shapley values for all the features.
The high-level point is that all these methods rely on taking subsets of features. This makes the theoretical version exponential in runtime: for N features, there are 2N combinations of presence and absence. That is too expensive for most N, so these methods approximate. Even with approximations, kernel SHAP can be slow. Also, we don’t know of any systematic study of how good the approximation is.
There are versions of SHAP specialized to different model architectures for speed. For example, Tree SHAP computes all the subsets by cleverly keeping track of what proportion of all possible subsets flow down into each of the leaves of the tree. However, if your model architecture does not have a specialized algorithm like this, you have to fall back on kernel SHAP, or another naive (unoptimized) Shapley-value-based method.
A Shapley-value-based method is attractive as it only requires black box access to the model (i.e. computing outputs from inputs), and there is a version agnostic to the model architecture. For instance, it does not matter whether the model function is discrete or continuous. The downside is that exactly computing the subsets is exponential in the number of features.
What is a Gradient-Based Explanation Method?
A gradient-based explanation method tries to explain a given prediction by using the gradient of (i.e. change in) the output with respect to the input features. Some methods like Integrated Gradients (IG), gradient SHAP, GradCAM, and SmoothGrad literally apply the gradient operator. Other methods like DeepLift and LRP apply “discrete gradients.”
Figure 1 from the IG paper, showing three paths between a baseline (r1 , r2) and an input (s1, s2). Path P2, used by Integrated Gradients, simultaneously moves all features from off to on. Path P1 moves along the edges, turning features on in sequence. Other paths like P1 along different edges correspond to different sequences. SHAP computes the expected attribution over all such edge paths like P1.
Let me describe IG, which has the advantage that it tries to approximate Aumann-Shapley values, which are axiomatically justified. IG operates by considering a straight line path, in feature space, from the input at hand (e.g., an image from a training set) to a certain baseline input (e.g., a black image), and integrating the gradient of the prediction with respect to input features (e.g., image pixels) along this path.
This paper explains the intuition of the IG algorithm as follows. As the input varies along the straight line path between the baseline and the input at hand, the prediction moves along a trajectory from uncertainty to certainty (the final prediction probability). At each point on this trajectory, one can use the gradient with respect to the input features to attribute the change in the prediction probability back to the input features. IG aggregates these gradients along the trajectory using a path integral.
IG (roughly) requires the prediction to be a continuous and piecewise differentiable function of the input features. (More precisely, it requires the function is continuous everywhere and the partial derivative along each input dimension satisfies Lebesgue’s integrability condition, i.e., the set of discontinuous points has measure zero.)

Figure 2 from the IG paper, showing which pixels were most important to each image label.
Note it is important to choose a good baseline for IG to make sensible feature attributions. For example, if a black image is chosen as baseline, IG won’t attribute importance to a completely black pixel in an actual image. The baseline value should both have a near-zero prediction, and also faithfully represent a complete absence of signal.
IG is attractive as it is broadly applicable to all differentiable models, easy to implement in most machine learning frameworks (e.g., TensorFlow, PyTorch, Caffe), and computationally scalable to massive deep networks like Inception and ResNet with millions of neurons.
When should you use a Shapley-value-based versus a gradient-based explanation method?
Finally, the payoff! Our advice: If the model function is piecewise differentiable and you have access to the model gradient, use IG. Otherwise, use a Shapley-value-based method.
Any model trained using gradient descent is differentiable. For example: neural networks, logistic regression, support vector machines. You can use IG with these. The major class of non-differentiable models is trees: boosted trees, random forests. They encode discrete values at the leaves. These require a Shapley-value-based method, like Tree SHAP.
The IG algorithm is faster than a naive Shapley-value-based method like kernel SHAP, as it only requires computing the gradients of the model output on a few different inputs (typically 50). In contrast, a Shapley-value-based method requires computing the model output on a large number of inputs sampled from the exponentially huge subspace of all possible combinations of feature values. Computing gradients of differentiable models is efficient and well supported in most machine learning frameworks. However, a differentiable model is a prerequisite for IG. By contrast, a Shapley-value-based method makes no such assumptions.
Several types of input features that look discrete (hence might require a Shapley-value-based method) actually can be mapped to differentiable model types (which let us use IG). Let us walk through one example: text sentiment. Suppose we wish to attribute the sentiment prediction to the words in some input text. At first, it seems that such models may be non-differentiable as the input is discrete (a collection of words). However, differentiable models like deep neural networks can handle words by first mapping them to a high-dimensional continuous space using word embeddings. The model’s prediction is a differentiable function of these embeddings. This makes it amenable to IG. Specifically, we attribute the prediction score to the embedding vectors. Since attributions are additive, we sum the attributions (retaining the sign) along the fields of each embedding vector and map it to the specific input word that the embedding corresponds to.
A crucial question for IG is: what is the baseline prediction? For this text example, one option is to use the embedding vector corresponding to empty text. Some models take fixed length inputs by padding short sentences with a special “no word” token. In such cases, we can take the baseline as the embedding of a sentence with just “no word” tokens.
For more on IG, see the paper or this how-to.
SHAP vs Integrated Gradients for Model Explainability
In many cases (a differentiable model with a gradient), you can use integrated gradients (IG) to get a more certain and possibly faster explanation of feature importance for a prediction. However, a Shapley-value-based method is required for other (non-differentiable) model types.
At Fiddler, we support both SHAP and IG. (Full disclosure: Ankur Taly, a co-author of IG, worked at Fiddler, and is a co-author of this post.) Contact us to talk to a Fiddler expert!