
At Fiddler AI, our mission is to provide a unified AI Observability and Security platform for agents, GenAI, and predictive ML. This means giving our customers deep insights into how their AI systems are behaving and performing in production. To power this we analyze the model inference logs — or "events" — which requires a robust and performant data store, and for us, that's ClickHouse.
ClickHouse Database: The Analytical Powerhouse
ClickHouse is an open-source, column-oriented database optimized for real-time analytics, delivering blazing-fast queries through efficient columnar storage. This makes it an ideal choice for an AI observability and security platform like Fiddler.
The Inevitable Duplicates: Why They Appear and Their Impact in AI Performance
In the world of distributed systems and high-throughput data ingestion, duplicates are an almost unavoidable reality. While ideally, every piece of data would arrive exactly once, several factors can conspire to create duplicate entries in your database. The following are the most common causes, though others may exist
- Network Retries and Transient Failures: Retries after lost server acknowledgement
- Application-Level Retries/Idempotency Challenges: Retries occur when workers restart due to node rotation or release rollouts.
- Source System Behavior: Duplicate events can be received from external systems due to design choices or bugs.
The presence of duplicate data silently undermines the reliability and trustworthiness of an AI observability platform. The consequences are far-reaching and can lead to incorrect insights and misguided decisions:
- Inaccurate Metrics and Reporting: This is perhaps the most direct and damaging impact. Duplicates can lead to inflated metrics such as traffic, distorting histograms and data integrity checks. Consequently, any reporting derived from these metrics will be skewed over time.
- Misleading Trends: If duplicates are not consistent over time, they can create artificial spikes or dips in trends, making it difficult to discern true changes in application or model behavior.
- False Positive/Negative Alerts: Inflated error rates or artificially high drift scores due to duplicates can trigger unnecessary alerts, leading to alert fatigue. Conversely, genuine issues might be masked.
- Increased Storage and Processing Costs: Duplicates consume valuable disk space in ClickHouse. More importantly, they lead to more data being processed during read queries, impacting query performance, increasing resource consumption, and driving up infrastructure costs.
Fiddler's Multi-Layered Deduplication Strategy: From API to Database
Fiddler uses a multi-stage deduplication approach, removing duplicates early in the ingestion pipeline to reduce costs before data reaches ClickHouse.
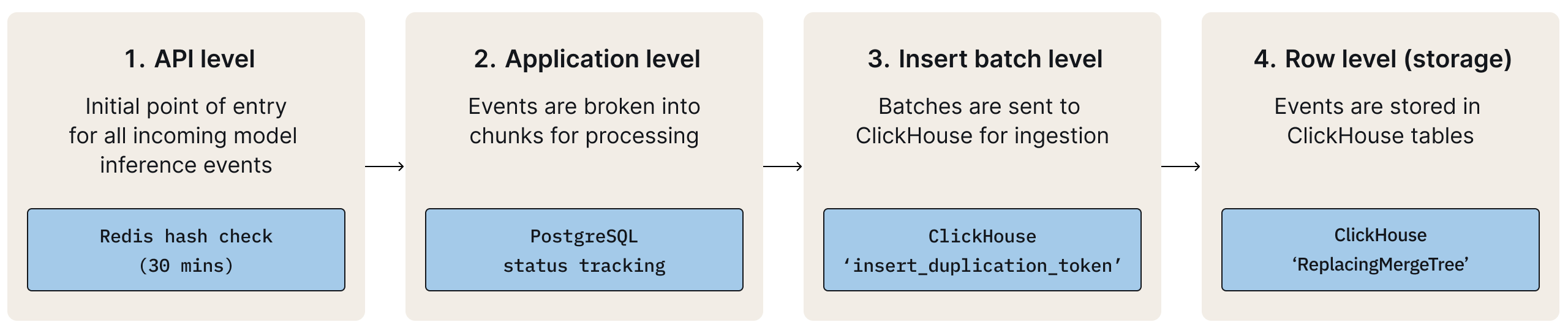
1. API Level Deduplication with Redis*
- When and Why it Happens: This initial defense against duplicates occurs immediately upon event data reaching Fiddler's ingestion APIs, often due to client retries caused by network failures or other issues.
- How it Works: For every incoming event, Fiddler calculates a unique hash of the events data. This hash is then stored in a Redis cache for a short, effective duration (e.g., 30 minutes). If an event with an identical hash arrives within this timeframe, it is immediately identified as a duplicate and dropped at the API gateway level, preventing it from entering the rest of the ingestion pipeline.
* Recently, Fiddler moved from Redis to Valkey, an open-source fork of Redis version 7.2.4.
Fiddler performs the initial deduplication of events at the API gateway using Redis for hash storage.

This immediate check at the API level significantly reduces redundant processes and ensures efficient resource utilization.
2. Application-Level Micro-Batch Status Tracking (PostgreSQL)
- When and Why it Happens: After API deduplication, events are batched for persistent storage. Duplication can occur if ingestion workers restart (e.g., due to node rotation) or if a batch is reprocessed following a service interruption, leading to this layer ensuring logical batches are processed only once.
- How it Works: Fiddler maintains a separate record in a PostgreSQL database for the status of each ingested micro-batch (chunk) of events. Before attempting to write a chunk to ClickHouse, the ingestion service first checks its status in PostgreSQL. If that specific chunk has already been marked as successfully processed, the ingestion process for that chunk is skipped entirely.
Fiddler's application layer prevents re-processing of micro-batches using a status tracker in PostgreSQL.
This prevents redundant application-level work and ensures logical batches are handled exactly once.
3. Idempotent Inserts with ClickHouse
- When and Why it Happens: Duplicate messages can rarely occur during write operations to ClickHouse, even after initial deduplication layers. This typically happens when messages are redelivered due to unreceived acknowledgments or service interruptions before the batch status is recorded in Postgres.
- How it Works: When Fiddler's ingestion service sends a batch of events to ClickHouse, it attaches a unique
insert_deduplication_tokento that specific batch. If the network drops or ClickHouse is momentarily unavailable and the client retries the insert with the same token, ClickHouse recognizes it. It checks its internal state and, if that token has already been successfully processed, it simply acknowledges the "new" insert without actually writing the data again.
You can learn more about this powerful setting in the ClickHouse documentation.
The database ingestion layer prevents duplicate inserts during retries using an idempotency token.
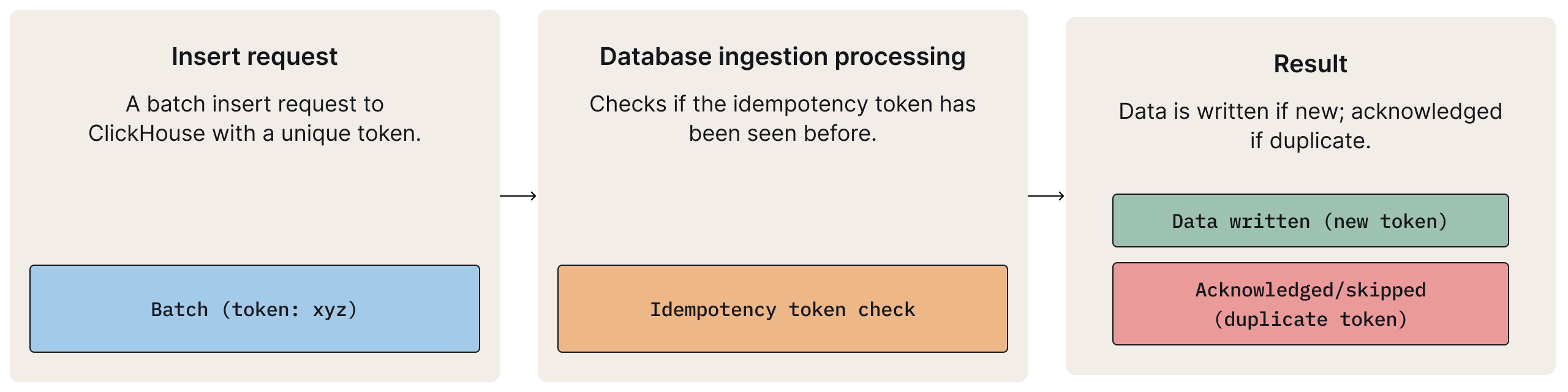
This ensures "at-most-once" delivery for each logical insert batch, even with transient network issues.
4. Eventually Consistent Deduplication with ReplacingMergeTree (ClickHouse)
- When and Why it Happens: This final layer of deduplication is handled directly by the ClickHouse database engine in the background. Duplication is extremely rare but can occur if an insert operation is retried outside the configured deduplication window, allowing the duplicate batch to pass through.
- How it Works:
- Fiddler uses Clickhouse’s
ReplacingMergeTreeto store inference events for each model. A key aspect of this setup is defining theORDER BYclause, which serves as the primary key for merges. This clause uniquely identifies an event, typically through anevent_id. To ensure that the "latest" version of an event is retained, Fiddler defines a version column with a timestamp with millisecond precision (UsesNOW64()function). - During the background merges,
ReplacingMergeTreeidentifies rows with identical values in theirORDER BYcolumns and retains the row with the newest timestamp..
- Fiddler uses Clickhouse’s
For more details, refer to the ClickHouse documentation on ReplacingMergeTree.
The storage layer automatically handles deduplication during background data merges, specifically in ClickHouse using ReplacingMergeTree.
.png)
This provides eventual consistency and keeps data clean without requiring manual intervention or query-time overhead for most analytical use cases.
How Multi-Layered Data Deduplication Powers Scalable AI Performance
Effective data deduplication is essential for maintaining trustworthy insights and reliable AI performance at scale. At Fiddler AI, this is achieved through a multi-layered strategy that addresses duplicates at every stage of the ingestion and storage pipeline. Each level plays a distinct role in ensuring accuracy, efficiency, and long-term consistency.
API-level: First Line of Defense
This level is crucial for Fiddler AI's ingestion pipeline, which often receives a high volume of rapidly arriving events. By minimizing the immediate impact of duplicates, it reduces the load on downstream systems and ensures a smoother, more efficient flow of data into Fiddler AI for analysis and model monitoring. It’s particularly effective for bursty traffic scenarios common in real-time data streams.
Application-Level: Preventing Redundant Processing
This level is vital for preventing redundant processing within Fiddler AI's internal logic. Even if external retries occur, this layer ensures that data confirmed as ingested isn't re-processed unnecessarily. This contributes to resource efficiency and data integrity within Fiddler AI's core application, preventing unnecessary computations and storage.
ClickHouse-Level: Ensuring Reliable Storage
This is paramount for Fiddler AI's robust data storage. It directly addresses the challenges of transient network issues or timeouts that can lead to retries of insert operations. By guaranteeing "at most once" delivery at the ClickHouse interface, it ensures the reliability and accuracy of the data stored, which is fundamental for Fiddler AI's analytics and model performance tracking.
Table Engine Level: Long-Term Consistency
This final level provides Fiddler AI with an out-of-the-box solution for long-term data consistency. It handles duplicates originating from any external sources, historical data reprocessing, or events that may arrive through different paths or at different times. This ensures the eventual uniqueness of Fiddler AI's event data without manual intervention, maintaining data quality for historical analysis and long-term model performance monitoring.
How Fiddler AI Ensures Reliable Insights with Data Deduplication
Fiddler AI has developed a highly scalable and dependable system for ingesting and deduplicating customer model inference events. This is achieved through strategic deduplication at multiple levels, guaranteeing the accuracy and integrity of the insights provided. As a result, our users are empowered to make confident decisions regarding their AI models and applications.
Love diving deep into technical challenges? Come work with engineers who are passionate about AI, data infrastructure, and distributed systems. Check out our careers page.
Frequently Asked Questions
What is the best deduplication appliance?
Instead of a single hardware appliance, modern enterprises rely on AI-driven data deduplication solutions integrated into their infrastructure. For example, the Fiddler AI Observability and Security Platform uses multi-layered deduplication across APIs, applications, and the ClickHouse database, providing scalable and flexible data integrity protection without specialized hardware.
How do you perform deduplication at scale?
Scalable deduplication requires a multi-layered approach to catch and prevent duplicates from impacting downstream systems early.
This can include:
- API-level deduplication to filter retry traffic.
- Application-level status tracking to avoid reprocessing.
- Database-level idempotency checks in ClickHouse.
- Storage-engine deduplication using techniques like ReplacingMergeTree for eventual consistency.
What are the drawbacks of deduplication?
While deduplication improves accuracy and reduces storage costs, it can introduce computational overhead and complexity if not implemented efficiently. Relying only on query-time deduplication in a database can slow down performance. That’s why layered strategies, like those used in production systems in AI, are more effective.
When should you avoid deduplication?
Deduplication may not be necessary for small-scale or temporary datasets where duplicates do not impact downstream analytics or AI performance. In these cases, the overhead of implementing complex deduplication pipelines may outweigh the benefits. However, ensuring clean, unique data is essential for trustworthy insights in enterprise-scale AI monitoring platforms.