
The launch of GPT-3 and DALL-E ushered in the age of Generative AI and Large Language Models (LLM). With 175 billion parameters and trained on 45 TB of text data, GPT-3 was over 100x the 1.5 billion parameters of its predecessor. It validated OpenAI’s hypothesis that models trained on larger corpora of data grew non-linearly in their capabilities. The next 18 months saw a cascade of innovation, with ever larger models, capped by the launch of ChatGPT at the tail end of 2022.

ChatGPT proved that AI is now poised to cross the technology chasm after decades of inching forward. All that remains is to operationalize this technology at scale. However, as we’ve seen with adoption of AI in general, the last mile is the hardest.
Path to Adopting Generative AI (LLMOps)
While Generative AI offers huge upside for enterprises, many blockers remain before it is used by a broad range of industries.
LLMs, especially the most recent models, have a large footprint and slow inference times, which require sophisticated and expensive infrastructure to run. Only companies with experienced ML teams with large resources can afford to bring models like these to market. OpenAI, Anthropic, and Cohere have raised billions in capital to productize these models.
Thankfully, the barrier to entry to productize Generative AI is quickly diminishing. Like ML Operations (MLOps), Generative AI needs an operationalized workflow to accelerate adoption. But which additional capabilities or tooling do we need to complete this workflow?
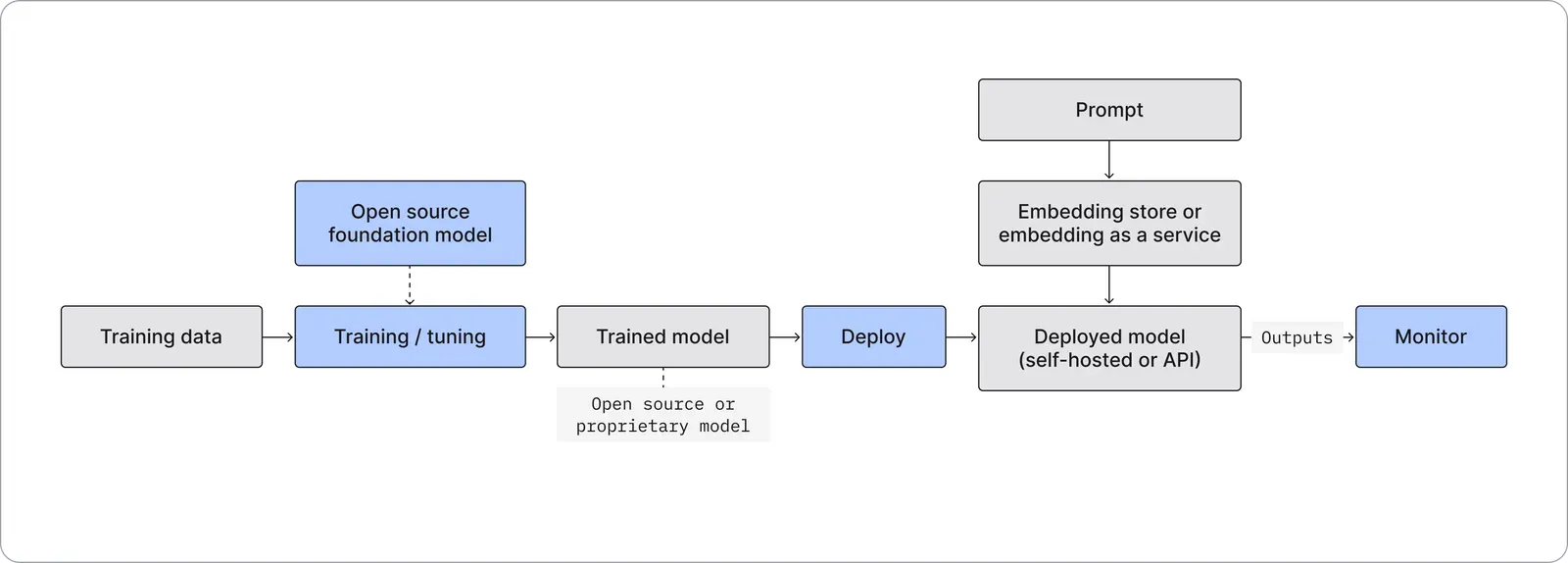
Model Training
Recent AI breakthroughs are only possible by training with a large amount of advanced computational resources on a large corpora of data — prohibitively expensive for any company except ones with vast AI budgets. All LLMs from GPT-3 to the recently released LLaMa (Meta) have cost between $1M-$10M to train. For example, Meta’s latest 65B LLaMa model training took 1,022,362 hours on 2048 NVidia A100-80GB’s (approximately $4/hr on cloud platforms) costing approximately $4M. Besides the cost, building these model architectures demands an expert team of engineering and data science talent. For these reasons, new LLMs will be dominated by well capitalized companies in the near term.
Cost-efficient LLM training requires more efficient compute or new model architectures to unlock a sub-$10,000 cost for large models like the ones generating headlines today. This would accelerate a long tail of domain-specific use cases unlocking troves of data. With cloud providers dominating LLM training, one can hope these efficiencies develop over time.
Model Selection
Cost-effective model training is, however, not a deterrent to large scale Generative AI operationalization for two reasons (1) availability of open source that can be tuned (2) hosted proprietary models that can be invoked via API, i.e. AI-as-a-Service. For now, these are the two approaches that most AI teams will need to select from for their Generative AI use cases
- Hosted Open Source Model - Majority of Generative AI innovation has come through models like Stable Diffusion which are open source. These “foundation models'' will perform without needing any changes for the majority of use cases. However, they will still need to be finetuned with domain relevant data for use cases that require industry or function-specific context, i.e. medical chat, etc. We are seeing new fine tuning infrastructure being added at HuggingFace, Baseten Blueprint, etc. This tuning infrastructure is a key need for building foundational model “flavors”.
- Closed Source Model via API - While hosted open source models will be the norm in the long term given their lower cost and in-house ownership, OpenAI and Cohere have pioneered a new way to consume proprietary models via APIs. This approach will work well for a large number of AI teams that don’t want to or don't have expertise to own these ML models. Eventually, companies similar to OpenAI will emerge. Instead of building new models, they will finetune foundational models for domain specific use cases and make them available to others via API.
Model Deployment
Model invocation cost is one of the biggest hurdles to adoption. The costs can be twofold: (1) inference speed and (2) expense driven by compute. For example, Stable Diffusion inference benchmarking shows a latency of well over 5 secs for 512 X 512 resolution images even on state of the art GPUs. Widespread adoption would require newer model architectures so that models can provide much faster inference speeds at lower deployment sizes while enabling comparable performance.
Coincidentally, companies are already making significant advances. Google AI recently introduced Muse, a new Text-To-Image approach that uses a masked generative transformer model instead of pixel-space diffusion or autoregressive models to create visuals. Not only does this run 10 times faster than Imagen and 3 times faster than Stable Diffusion, but it also accomplishes this with only 900 million parameters.
Embedding Ops
With Generative AI’s focus on unstructured data, the representation of that data is a critical piece of the data flow. Embeddings represent this data and are typically the input currency of these models. How information is represented in these embeddings is a competitive advantage and can bring more efficient and effective inferences, especially for text models. In this sense, embeddings are equally (if not more) important than the models themselves.
Efficient embeddings are, however, non trivial to build and maintain. The rise of Generative AI APIs have also given rise to embedding APIs. Third party embedding APIs are bridging the gap in the interim by providing easy access to efficient embeddings at a cost. OpenAI, for example, provides an embeddings model, Ada, which costs $400 for every 1M calls for 1K tokens which can quickly add up at scale. In the long term, Generative AI deployments will need cheaper open source embedding models (eg. SentenceTransformers) that can easily be hosted to provide embeddings along with an embedding store, similar to a feature store, to manage them.
AI Monitoring and Safety
As we’ve discussed, Generative AI is not cheap. On OpenAI’s Foundry platform, running a lightweight version of GPT-3.5 will cost $78,000 for a three-month commitment or $264,000 over a one-year commitment. To put that into perspective, one of Nvidia’s recent-gen supercomputers, the DGX Station, runs $149,000 per unit. Therefore, a high performance and low cost Generative AI application will need comprehensive monitoring infrastructure irrespective of whether the models are self-hosted or are being invoked via API from a third party.
It’s well known that model performance degrades over time, known as model drift, resulting in models losing their predictive power, failing silently, or harboring risks for businesses and their customers. Companies typically employ model monitoring to ensure their ML powered businesses are not impacted by the underlying model’s operational issues. Like other ML models, Generative AI models can bring similar and even new risks to users.
The most common problem plaguing these models is correctness of the output. Some prominent examples have been both Google Bard and Microsoft Bing’s errors and AI’s flawed generation of human fingers. The impact of inaccuracies is amplified for critical use cases that could lead to potential harm eg. incorrect or misleading medical information, encouraging self-harm etc. These incorrect outputs need to be recorded to improve the model’s quality.
Prompts are the most common way end users interact with Generative AI models, and the second biggest issue is prompt iteration to reach a desired output. Some prompts might give ineffective outputs while other prompts might not have sufficient data to generate a good output. In both cases, this results in customer dissatisfaction that needs to be captured to assess if the model is performing poorly in some areas after its release.
Generative AI models can also encounter several other operational issues. Data or embeddings going into the models can shift over time impacting model performance — this is typically evaluated with comparison metrics like data drift. Model bias and output transparency are lingering concerns for all ML models and are especially exacerbated with large data and complex Generative AI models. Performance might change between versions, so customers need to run tests to find the most effective models. Costs can catch up quickly, so monitoring expenses of these API calls and finding the most effective provider is important. Safety is another new concern either from the model’s objectionable outputs or from the user’s adversarial inputs. Monitoring solutions can provide Generative AI users visibility into all these operational challenges.
The onset of Generative AI will see an explosion of API driven users given the ease of API integrations, soon followed by a rapid increase of hosted custom Generative AI models. Infrastructure tooling will therefore follow a similar arc that will enable the “AI-as-a-service” use case first and the hosted custom AI use case next. Over time the maturation of this infrastructure in training, tuning, deploying, and monitoring will bring Generative AI to the wider masses.
Want to learn more about MLOps for Generative AI? Join us at the Generative AI Meets Responsible AI virtual summit.