Businesses are projected to double their spending in AI systems over the next three years. But productionizing machine learning models behind the AI solutions can be challenging and pose business risks if done incorrectly. Machine learning fairness is one of those key concerns. Recent news stories around AI bias and resulting regulatory probes in credit-lending, hiring, and healthcare applications highlight this problem. 2020 made us especially aware of the challenges that bias poses in society and brought AI’s bias dilemma to the forefront.
Besides the need to comply with existing regulations in some verticals (Equal Credit Opportunity Act (ECOA), The Fair Housing Act, Civil Rights Act, Age Discrimination in Employment Act, etc.), consumers are holding companies accountable, like the case of biased facial recognition that caused providers to exit the market altogether.
ML models are trained on real-world examples so they can generalize historical outcomes on new data. This training data itself could be biased for several reasons, including the limited number of data items representing protected groups and the potential for human bias to creep in during data curation. In addition, models can themselves perpetuate or amplify the training data bias or introduce new bias altogether depending on the training process and the production data. This latter part means that models can become biased even after deployment, given the dynamic nature of data, and need to be checked.
Fairness is a difficult topic that is subjective depending on the domain context. In fact, we have over 20 different notions of fairness. There are some open source packages today that offer what we call a “kitchen sink” solution with limited reliable, secure, and scalable options.
At Fiddler, we view machine learning fairness in the context of three questions:
- How is my model working?
- Is it working correctly?
- How do I fix it?
Building a fair AI process requires a two-step process (1) Assess Bias and (2) Mitigate Bias. Today, we’re launching “Bias Detector” in Preview to help teams address the first step for their Machine learning Fairness - Assess Bias. Let’s walk through to see how Bias Detector is uniquely positioned to enable users to assess and solve for bias in their AI models.
- Bias can be introduced during model training or during model inference. Bias Detector can, therefore, evaluate bias both in the static context of your training set and in the dynamic context of your live prediction data. This ensures that you can assess bias in your models not only in pre-deployment for validation but also in production for an ongoing real-time assessment.

- To run Bias Detector, you need access to the protected attributes since they form the reference against which you’re evaluating for bias. Depending on the use case, you may or may not be able to use protected fields in the model training. Fiddler allows you to upload these fields as metadata with the model and then use it for post hoc analysis.

- Differentiating between Data and Model bias - while bias can exist in the data, the model it's trained on can have another representation of it. Fiddler offers fairness insights into both of these entities.
Many times, a model can inadvertently absorb relationships from the data that may be correlated with a protected field even though the field itself might not be used in the model training. For example, if you hypothetically trained a home lending model with a zip code, it would lead to a racial bias given historical redlining challenges.
For data bias, the Bias Detector highlights feature correlations to understand direct or indirect (proxy) relationships. Even if the data is unbiased, the model might be trained for high accuracy that prioritizes certain relationships making the model biased. In this case, the Detector highlights model metrics across protected classes to discern how it may be behaving differently for each class. For example, in the most recent facial recognition bias problem where the model incorrectly classified people with darker skin tones more often, a simple False Positive Rate for each race class would have surfaced the problem.

- Fairness metrics - While there can be over twenty notions to assess fairness, our Bias Detector starts with the four that have legal precedence. These are:
- Disparate Impact: Measures a form of indirect and unintentional discrimination in which certain decisions disproportionately affect members of a protected group.
- Demographic Parity: Compares whether the proportion of each segment of a protected class receives the positive outcome at equal rates.
- Equal Opportunity: Assesses if all people are being treated equally or similarly and not disadvantaged by prejudices or bias based on the true positive rate.
- Group Benefit: Calculates the rate at which a particular event is predicted to occur within a subgroup compared to the rate at which it actually occurs.
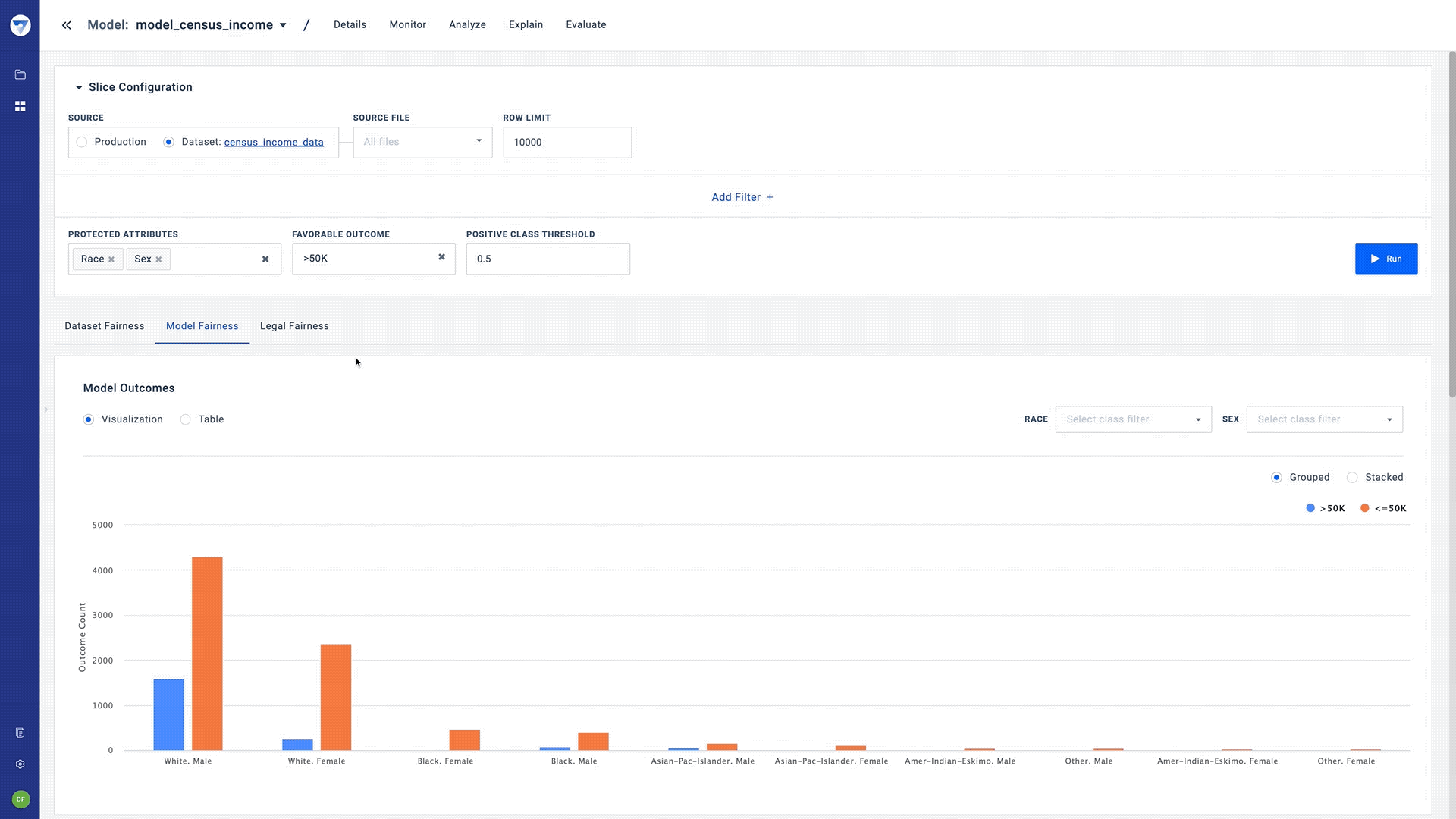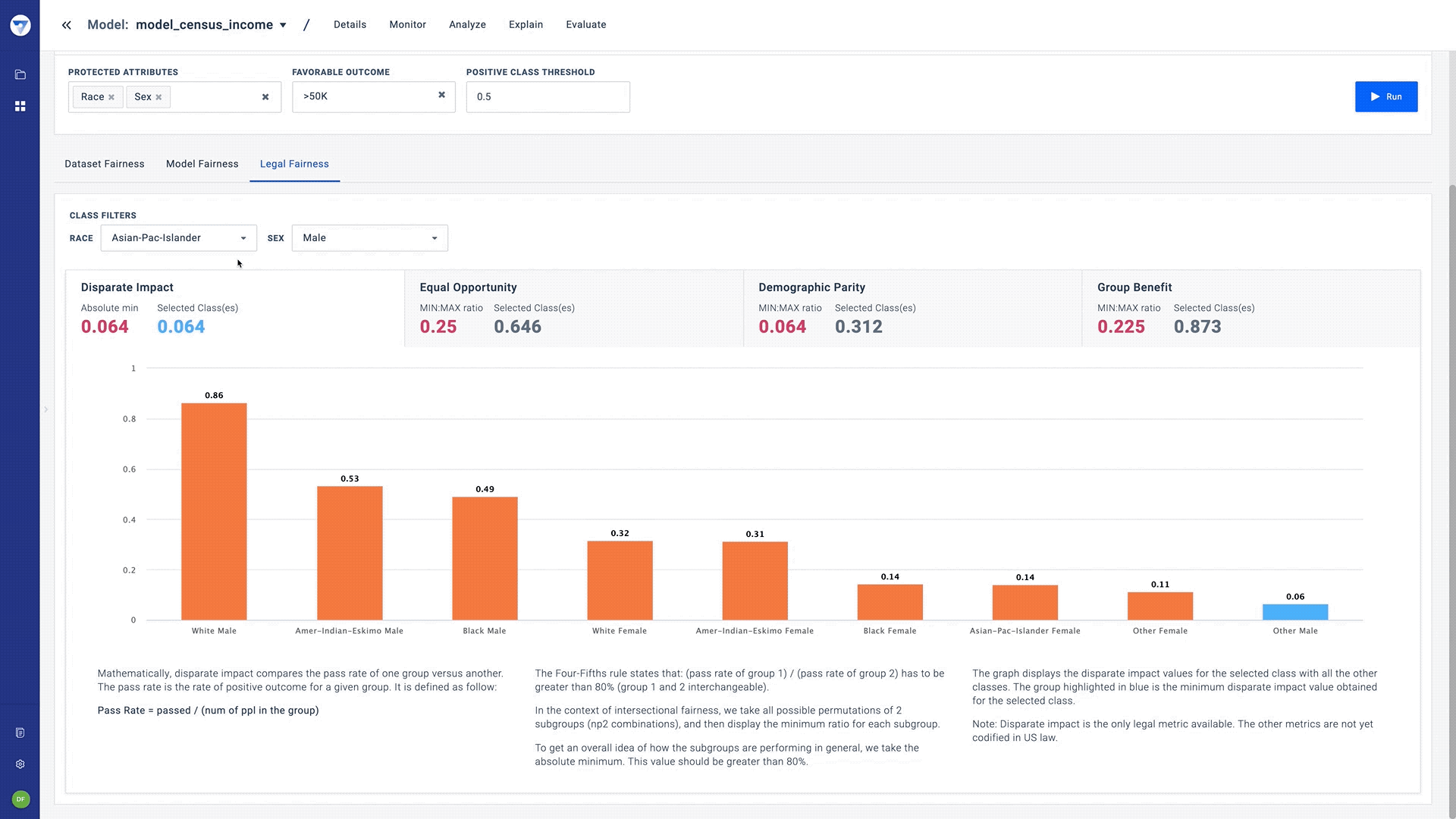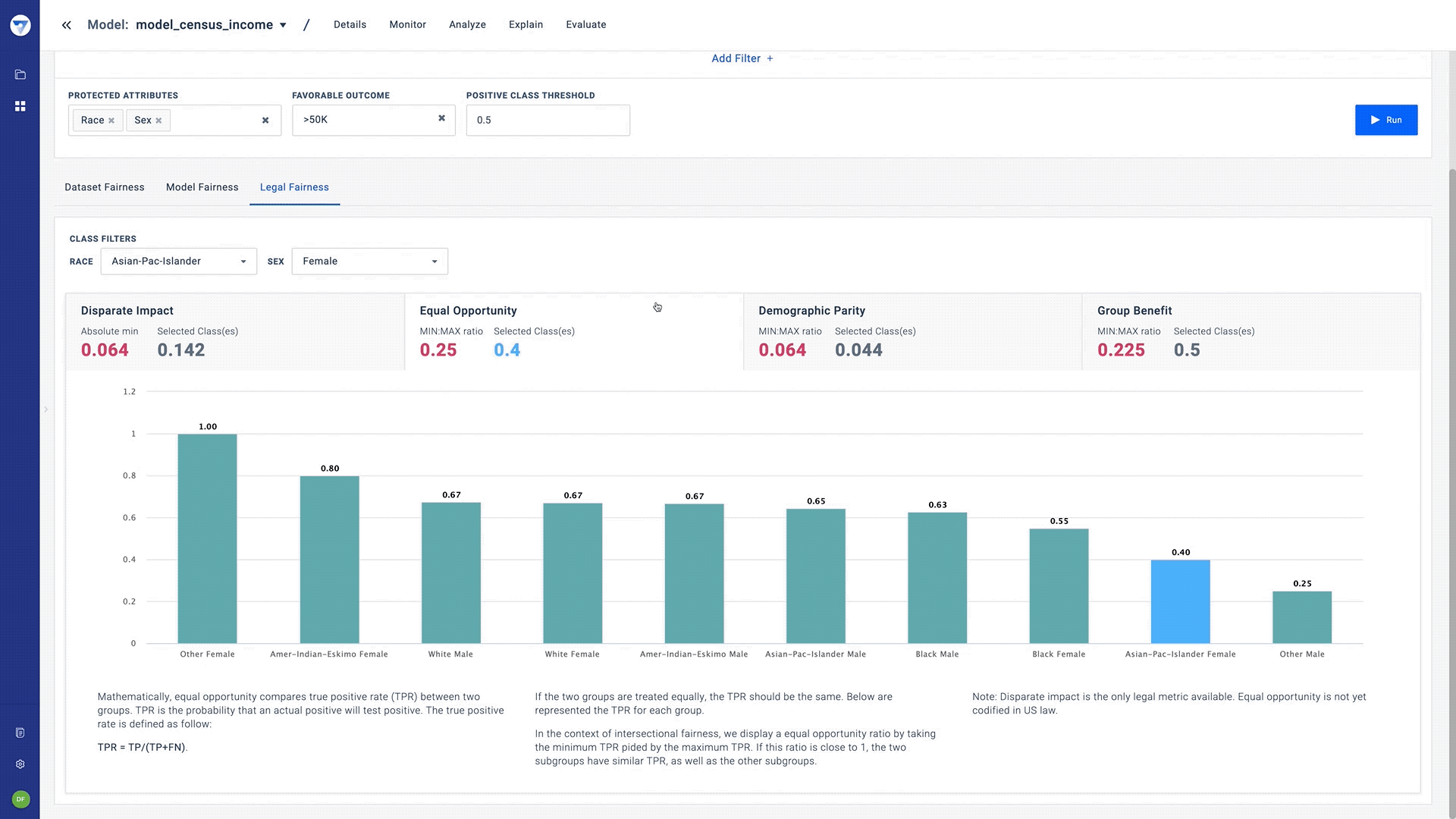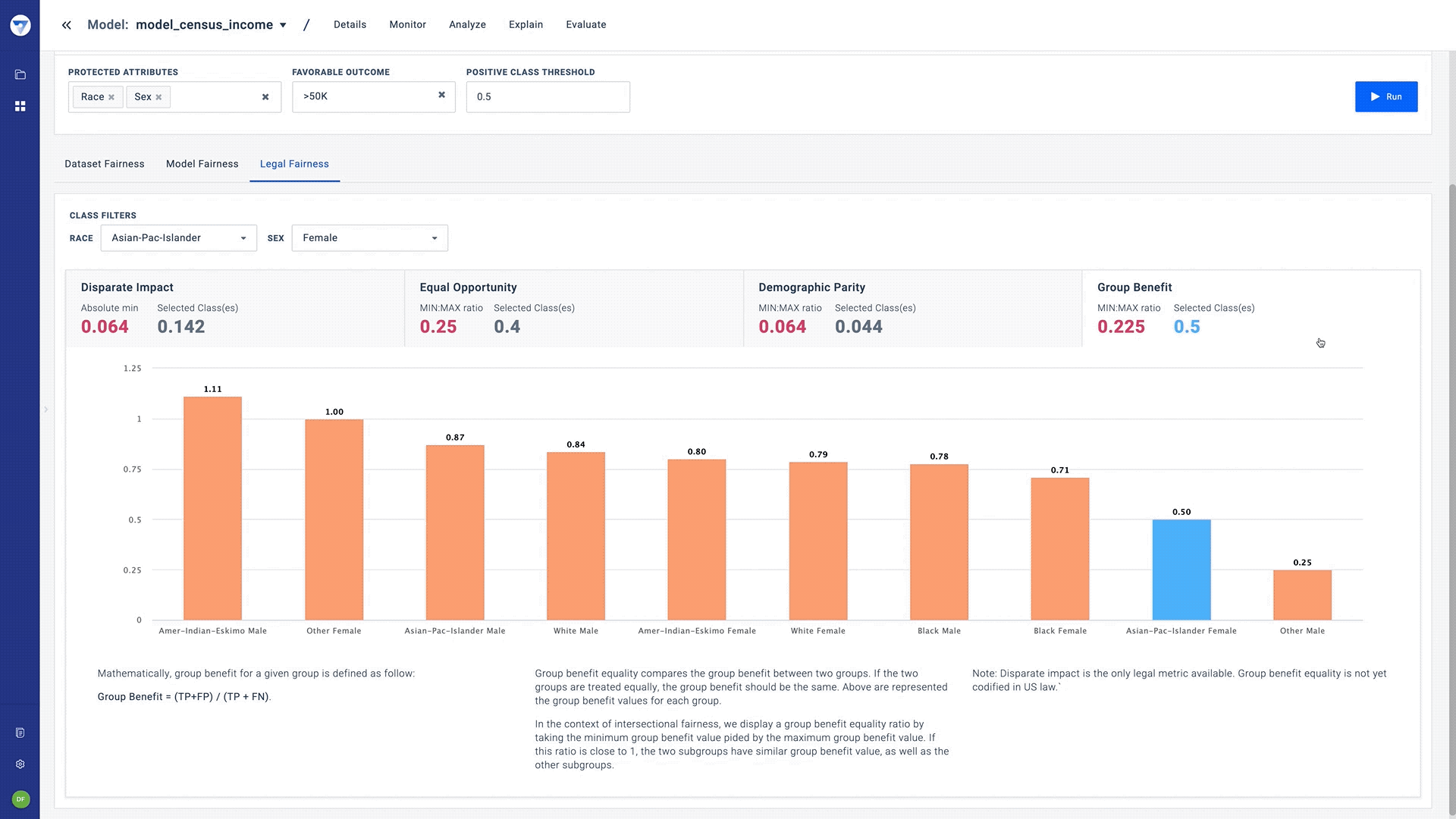
- Intersectional fairness - Fairness solutions today offer the ability to view bias in the context of one protected field. However, practical fairness is often more complicated and needs to be viewed under the lens of multiple fields, simultaneously.
The example below describes the importance of intersectional fairness. In the figure, we observe an equal number of black and white people classified as ‘pass’ by the model. Similarly, the model classified an equal number of women and men as ‘pass’. However, this classification is unfair because we observe some bias with the subgroups when we take Race and Gender as protected attributes.
While fairness metrics today are only defined under the context of one protected attribute, Bias Detector allows teams to assess bias using two or more protected attributes. The Fiddler team proposed and implemented a unique “worst-case framework” that provides a way to evaluate bias with the same fairness metrics under intersectional fairness. Our paper on this topic was recently published at AAAI for the AIDBEI 2021 workshop.
Bias Detector helps data scientists, ML practitioners, and decision makers understand bias in their ML systems so they can confidently mitigate it. If you’d like to learn more about how to unlock your AI black box and monitor it for high operational performance, let us know.