
This blog series focuses on unfairness that can be obscured when looking at data or the behavior of an AI model according to a single attribute at a time, such as race or gender. We first describe a real-world example of bias in AI and then discuss fairness, intersectional fairness, and their connection to the example. Finally, we dive into a demonstration with a simple example.
A real-world example of bias in AI
As Machine Learning (ML) and Artificial Intelligence (AI) become more integrated into our everyday lives, they must not replicate or amplify existing societal biases, such as those rooted in differences in race, gender, or sexual orientation.
Consider a real-world manifestation of model bias discussed by Buolamwini and Gebru [1]. They found that gender classification algorithms for facial image data performed substantially better on men’s faces than women’s. Naturally, such a manifestation of bias is unfair to women. More generally, the notion of fairness at its heart advocates for similar treatment of various groups based on attributes such as gender, race, sexual orientation, and disability.
Further, Buolamwini and Gebru [1] found that the most significant performance drops of the gender classification algorithms for facial image data came when both race and gender were considered, with darker-skinned women disproportionately affected, having a misclassification rate of about 30%. Such a manifestation of amplifying biases within subgroups is referred to as intersectional unfairness. Even when biases are not evident for a specific attribute, biases can be observed when intersections or combinations of attributes are considered.
Intersectionality
In the context of fairness, the term "intersectional" comes from the social and political sciences. It was introduced as Intersectionality by Kimberlé Williams Crenshaw, a prominent lawyer and scholar in the social and political sciences advocating for civil rights focusing on race and gender issues [2]. Formally, intersectionality refers to how aspects of a person's social and political identities create different forms of discrimination and privilege [2]. Such identities include gender, caste, sex, race, class, sexuality, religion, disability, physical appearance, and height. For example, while an organization may not be discriminating against the Black community or women in general, it may end up discriminating against Black women who are at the intersection of both these groups.
Given that intersectionality from social and political sciences provides a well-documented framework of how both privilege and discrimination can manifest within society by humans themselves, it is crucial to understand the impact of such human biases on ML models.
As AI practitioners and enthusiasts, it shouldn't be surprising that joint distributions reveal structure in data that marginal distributions might hide. Simplistic characterizations can be dangerous oversimplifications, which AI can consequently learn.
Intersectional fairness in AI
Intersectional analysis aims to ensure fairness within subgroups that overlap across various protected attributes such as gender and race. Thus, the notion of fairness across gender or races, for example, would be extended via intersectional fairness to investigate subgroups such as Black women and Asian men. Such notions of intersectionality apply to any overlapping groups of interest, possibly formed by more than two groups.
Let’s take the example of intersectional fairness of a simple ML model that predicts credit card approval given input data such as personal information and credit repayment history. We leveraged a publicly available dataset on Kaggle. However, the data on certain attributes such as gender, race, and income were modified such that they were sampled from a synthetic distribution. For example, income was a bimodal distribution conditional on the gender and race of an individual. The model’s output is binary: approve (will repay) or reject (will default). We use a logistic regression model from scikit-learn to regress the input data to the binary outputs.
Model inputs
We have the following information about 45,985 clients (rows in the dataset):
- Their financial assets
- Do they own a car?
- Do they own real estate?
- Sources of their income?
- Their personal history
- Their education level?
- Single or married?
- Type of dwelling/housing?
- Birthdate
- Employment history
- Family members
- Their protected information
- Gender – synthetically modified to ensure 50% men and 50% women
- Race – synthetically generated such that we sample from a weighted distribution as follows: 70% Caucasian, 10% Black, 10% Asian, 5% Pacific Islanders, and 5% Others
- Credit health-relevant Information
- How much do they earn? 'Income' – synthetically modified such that we draw from a bimodal distribution conditioned on race and gender
- How many times did they pay off their credit cards on time?
- How many times did they not pay off their credit on time?
- How many times did they not use their credit card?
Model output
The model simply predicts whether to approve or reject credit requests taken as a “target” column in the dataset with either 1 (approve) or 0 (reject).
Model information
We use the sklearn.linear_model.LogisticRegression classifier with default parameter values for arguments that can be passed within it.
Model training
We reserve 20% of the dataset for testing (9,197 rows) and train the model with the remaining 80% (36,788 rows). We get the following confusion matrix and performance metrics on test data upon training the model.

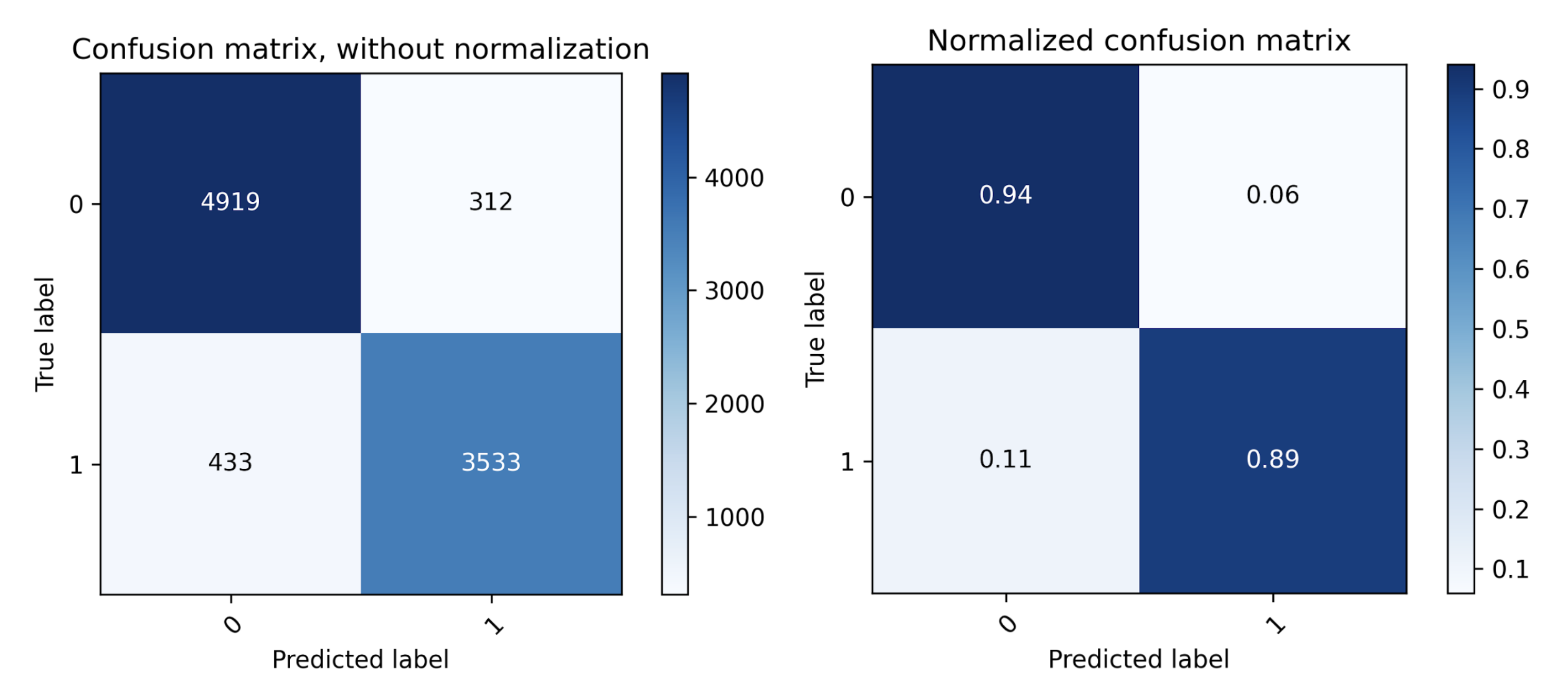
So far, so good. The model performs well according to AUC, F1 score, and other standard metrics.
Fairness metrics on the Fiddler platform
Given such an ML model, Fiddler allows one to evaluate their model for fairness based on a variety of metrics. Since there is no single definition of fairness, we allow model designers to make decisions on which metric is most appropriate based on their application context and use cases. Our built-in fairness metrics include disparate impact, demographic parity, equal opportunity, and group benefit.
The pass rate is the rate of positive outcomes for a given group. It is defined as the ratio of the number of people predicted to have a positive outcome to the total number of people in the group.
True positive rate (TPR) is the probability that an actual positive label will test positive. The true positive rate is defined as follows:
TPR = (TP) / (TP + FN).
Where,
TP = The number of True Positives: Correctly classified examples with positive labels.
FN = The number of False Negatives: Incorrectly classified examples with positive labels.
Disparate impact requires the pass rate to be similar across different groups. It is quantified by taking the proportion of the pass rate of the group of interest to that of a baseline group. Typically, in the context of fairness, the group of interest is an underprivileged group, and a baseline group is a privileged group.
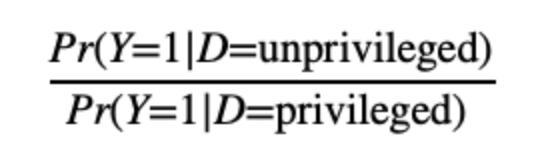
In the context of disparate impact, it may be desirable for the pass rates to be similar across groups and hence, for the above measure to be closer to 1.
Demographic parity is similar to disparate impact and is in some contexts indicative of fairness. Disparity is defined as the difference between the pass rates of two groups and in the context of demographic parity it should be ideally zero and in practice minimized.
Equal opportunity compares the true positive rate (TPR) between two groups. The rationale here is that since an algorithm may have some false negatives (incorrectly providing a negative outcome to someone even though they deserved otherwise), it is crucial to consider the proportion of people who actually receive a positive outcome in the subgroup that deserved the positive outcome. Thus, the focus here is on the algorithm's ability to provide opportunities to the deserving subgroup and its performance across different groups.
Group benefit aims to measure the rate at which a particular event is predicted to occur within a subgroup compared to the rate it actually occurs.
Fairness evaluation — test for gender bias
Given these metrics, one can specify one or more protected variables such as gender or race. Multiple selections would be considered intersectional.
To test for gender bias, we specify gender as the protected variable. This divides a specified dataset such as test data based on gender and enables us to compare how the given model performs for each gender category. For simplicity, we consider only two genders (men and women); we acknowledge that the notion of gender is a lot more nuanced and cannot be captured by just two labels.
We get the following results for fairness metrics on the model’s performance across genders:

The result shows no indication of unfairness across the provided fairness metrics. The model has similar pass rates, true positive rates, etc., across men and women.
Fairness evaluation — test for racial bias
Similarly, to test for racial bias, we specify race as the protected variable. This divides a specified dataset such as test data based on race and enables us to compare how the given model performs for each racial category. In this case, we had 5 categories including Caucasian, Black, Asian, Pacific Islander, and Others.
We get the following results for fairness metrics on model performance across racial groups:

Three of the four fairness metrics indicate unfairness, whereas the group benefit metric suggests that the model is fair. Let’s assume that the model’s designer had predetermined that the group benefit metric is the right metric to optimize as the designer is focused on the benefits that each subgroup receives given the model. In this context, the model is fair and devoid of racial unfairness. On a side note, we mention that it may be a futile effort to optimize all fairness metrics as it has been shown that they may not all hold well simultaneously [PDF].
So let’s assume that group benefit is the fairness metric in consideration and that our model is fair for gender and fair for race. The question is whether our model is fair for gender and race? While superficially, this seemingly innocuous question may have a naive answer that if the model is doing well for gender and is doing well for race, then there is little room for doubt for both being considered together. However, we cannot be sure until we test our model. So let’s do that!
Fairness evaluation — test for intersectional fairness across race and gender
Fiddler allows you to specify multiple attributes of interest. In this case, we specify both gender and race and run the evaluation.
We get the following results for fairness metrics on model performance across racial and gender subgroups:
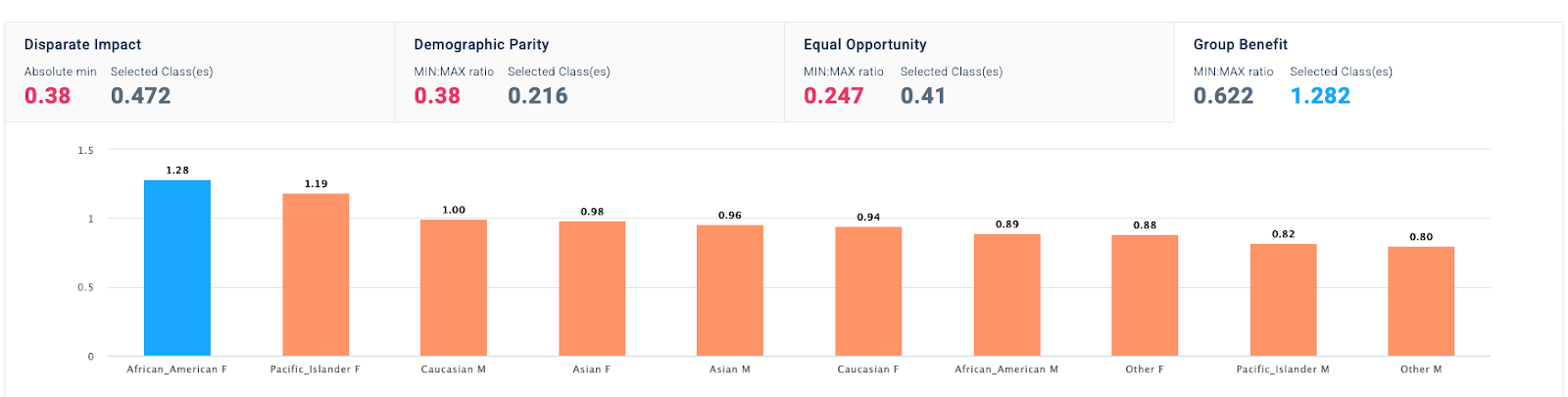
We note that the model is now evaluated to perform poorly on all the fairness metrics, including group benefit, which was the metric in focus for the designer. This result contrasts with fairness evaluations on individual groups such as gender and race, where we noticed that at least one fairness metric indicated that the model evaluations are fair. However, under the lens of intersectionality, where both gender and race are considered in combination, the model is evaluated to be unfair as it performs very poorly for certain groups, e.g., Pacific Islander men, and much better for some others, e.g., Caucasian men. These are real groups of people whose disparate treatment would likely be overlooked in a conventional assessment.
Conclusions and implications
In this blog, we introduced and demonstrated one of the ways in which intersectional unfairness can manifest in ML applications and affect real subgroups in easily overlooked ways. We illustrated how the evaluation of fairness according to single attributes can obscure the treatment of subgroups. This implies that designers of ML models need to both a) carefully consider the key performance metrics upfront and b) develop workflows that are sensitive to these metrics at the intersections of protected attributes.
We also note that our toy example demonstrates only one particular manifestation of intersectionality where we evaluated the intersectional fairness of the outcomes. Fairness and intersectionality can also manifest in the process of designing ML systems and creep up due to human decision-making while updating and maintaining such ML systems. We'll dig deeper into these ideas in a subsequent post.
Through these discussions on fairness, it is clear that practitioners are often faced with difficult choices regarding measuring and mitigating biases in their ML models. While it may be tempting to dismiss considerations of fairness due to complexities in fairness evaluations or prioritization of business objectives, we emphasize that it is crucial to make careful choices and develop problem-solving pathways that approach ethics and fairness in AI with the appropriate considerations in mind.
References
- Joy Buolamwini and Timnit Gebru. Gender shades: Intersectional accuracy disparities in commercial gender classification. In Conference on fairness, accountability and transparency, pages 77–91, 2018.
- Crenshaw, K. W. (2017). On intersectionality: Essential writings. The New Press.