AI Agent Monitoring: Key Steps and Methods to Ensure Performance and Reliability
Min Read
AI agents are quickly becoming essential components of enterprise applications, driving customer support, data analysis, automation, and decision-making. As these agents grow more capable and complex, so does the need to ensure they operate reliably, ethically, and in alignment with business objectives. Agentic Observability lays the groundwork for systematically monitoring, assessing, and improving agent performance throughout the development and production stages.
With the rise of agentic AI and increasingly sophisticated multi-agent systems powered by large language models (LLMs), enterprises need advanced evaluation frameworks and observability solutions to support responsible, scalable deployment. These solutions must also provide visibility and transparency into agentic workflows, where agents reason, plan, and interact dynamically across tools and tasks.
This blog will explore how to monitor AI agents using proven methods and metrics — and how the Fiddler AI Observability and Security platform, through its agentic monitoring, enables teams to build secure, high-performing multi-agent systems with confidence, transparency, and control.
What is Agentic Observability?
Agentic observability refers to the structured monitoring of AI agents' behaviors, decisions, and interactions with other agents across sessions. It allows enterprises to:
- Assess how agents perform tasks and respond to inputs.
- Ensure alignment with key criteria like efficiency, ethical compliance, and user satisfaction.
- Evaluate agents based on responsible AI principles like trust, data privacy, and transparency.
With the right visibility into agent behavior, organizations can confidently ship AI-powered systems, knowing they meet performance standards and safeguard users from potential harm.
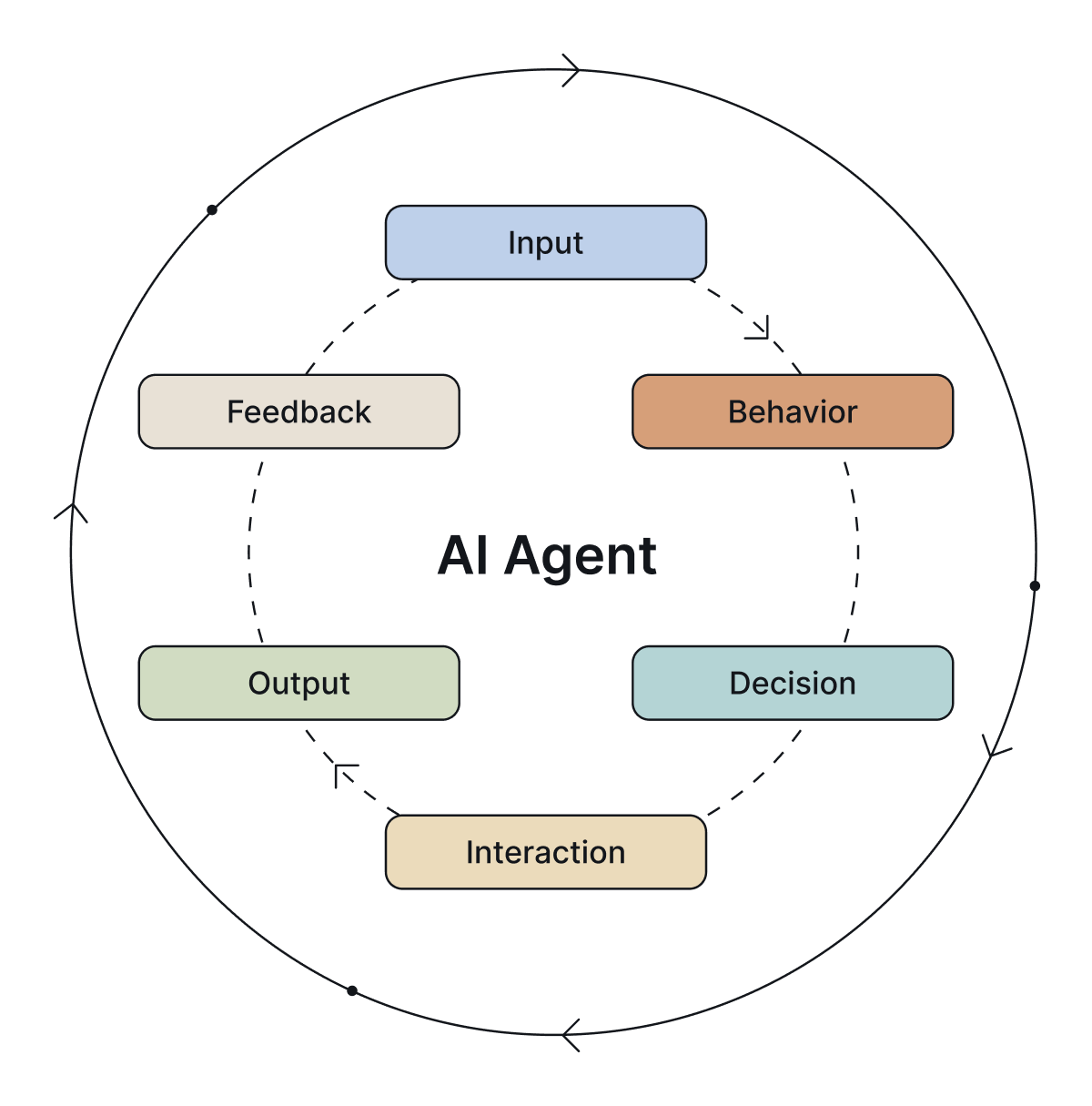
Why Monitor AI Agents?
Monitoring AI agents is foundational to any robust AI agent evaluation framework. Without continuous visibility into an agent's behavior and decision-making processes, blind spots can emerge, jeopardizing user trust, business outcomes, and regulatory compliance.
Key benefits of monitoring AI agents include:
- Behavioral alignment: Ensures agents act according to predefined business rules, ethical standards, and organizational goals, allowing teams to verify that each agent's action aligns with intended outcomes.
- Performance visibility: Enables real-time identification of issues such as model drift, degraded response quality, or execution bottlenecks, which are critical for maintaining consistent performance.
- Compliance assurance: Helps ensure adherence to regulatory frameworks and responsible AI practices, including trust, transparency, and data privacy.
- Continuous improvement: Drives ongoing optimization by feeding usage and performance data back into retraining loops, allowing for refinement of models and agent logic over time.
Whether deploying a single virtual assistant or managing a sophisticated, multi-agent architecture, monitoring AI agents is essential to sustaining system reliability, reducing risk, and supporting scalable enterprise adoption.
How to Evaluate AI Agents
AI agent evaluation is a structured, formal process embedded within broader AI observability and governance strategies. To be effective, consistent, repeatable, and tailored to the agent's role, complexity, and risk profile.

1. Build a Comprehensive Test Suite
Develop a test environment that simulates typical and edge-case scenarios to assess the agent's performance thoroughly. Incorporate:
- Deterministic tasks with clear, expected outcomes.
- Open-ended prompts to evaluate generative AI capabilities.
- Load testing to determine performance under stress and concurrent interactions.
Use a diverse evaluation dataset that reflects real-world conditions to ensure robust and meaningful assessments.
2. Map the Agent's Workflow and Decision Logic
Before running evaluations, clearly define the agent's:
- Input processing and interpretation logic.
- Internal reasoning process and decision-making paths.
- External tool and API interactions.
- Expected outputs across various use cases.
This operational blueprint improves coverage and helps isolate issues in the workflow during testing.
3. Choose the Right Evaluation Methods
Select methods that align with the agent's function and the level of risk involved:
- Automated testing: Ideal for efficiency, scalability, and baseline validations.
- Human-in-the-loop (HITL): Necessary for nuanced, subjective, or high-impact tasks.
- Hybrid approaches: Combine automation with human oversight for complex or safety-critical agents.
These methods provide structured evaluation results that inform decisions in AI development pipelines.
4. Address Agent-Specific Challenges
Each agent functions within a unique context that must be accounted for during evaluation:
- Planning complexity: Agents with multi-step logic require deeper assessments of task decomposition and execution paths.
- Tool dependencies: Evaluate the reliability, latency, and availability of external APIs or third-party systems.
- Dynamic environments: Test performance under shifting conditions, including real-time data inputs and varying user behavior.
Identifying these factors early reduces blind spots and strengthens deployment readiness.
5. Iterate, Optimize, and Re-Evaluate Continuously
Evaluation is not a one-time task but an ongoing process supporting continuous learning and adaptation. Teams should:
- Monitor agents regularly in production settings.
- Reassess after software updates or retraining.
- Use feedback loops to refine models and logic.
By tracking performance and evaluation results over time, organizations can track progress, ensure alignment with objectives, and maintain reliable operation as systems scale.
Common AI Agent Evaluation Metrics
Evaluating AI agents requires clearly defined, objective metrics to assess performance, reliability, and user impact. Here are some of the most important metrics to consider:
- Task Success Rate: Measures how accurately the agent completes assigned objectives based on predefined success criteria.
- Response Time: Assesses the speed of the agent's responses, which directly impacts user experience and system efficiency.
- Scalability: Evaluates the agent's ability to maintain consistent performance under increasing load or concurrent sessions.
- Hallucination Metric: This is especially critical for LLM-powered agents, as it tracks the frequency of fabricated, incorrect, or nonsensical outputs.
- Toxicity Metric: Identifies potentially harmful, offensive, or biased content in the agent's responses to ensure responsible interaction.
- User Satisfaction (CSAT/NPS): Captures human feedback to assess perceived usefulness, trustworthiness, and overall experience with the agent.
Custom Agent Considerations
Off-the-shelf evaluation metrics are great for assessing AI agents for general application use cases. Enterprises building AI agents with unique use cases require custom metrics, capabilities, and objectives. Enterprises should customize their evaluation approach to the agent's role and operating context to generate meaningful, actionable insights.
Key strategies include:
- Define custom metrics: Establish domain-specific KPIs that reflect the agent's intended function, success criteria, and application nuances.
- Simulate real-world tasks: Create evaluation scenarios that accurately replicate production environments, including variable inputs, edge cases, and evolving user interactions.
- Use skill-based evaluations: Design performance assessments that align with domain-relevant tasks and expected expertise for specialized agents — such as coding assistants or research agents.
- Implement continuous monitoring: Track agent behavior over time to identify regressions, performance drift, or new failure patterns that may emerge in dynamic settings.
Agent Workflow Integration
Integrated AI agents often rely on external tools, APIs, and complex planning algorithms to complete tasks. Effective AI agent monitoring requires a comprehensive evaluation of how these components interact within the agent's operational workflow.
Key areas to assess include:
- Reviewing reasoning paths and execution sequences: Trace the agent's logic and decision-making process to ensure alignment with intended outcomes.
- Assessing training data quality and coverage: Evaluate whether the training data is sufficient, representative, and appropriate for the agent's tasks.
- Testing external tool usage: Monitor how the agent interacts with APIs, databases, or third-party services, including how it handles failures or fallback scenarios.
- Measuring convergence rates: Determine how consistently the agent reaches correct or optimal outcomes across different inputs and conditions.
Evaluation Methods
Evaluation techniques span from classic testing to advanced simulations:
- Static testing: Ideal for known inputs and expected outputs.
- Dynamic interaction: Real-time testing with users or simulated environments.
- HITL evaluations: For nuanced or sensitive use cases.
- Scenario-based simulations: Mimic complex, evolving environments.
- Logic tracing: Tracks how decisions are made and identifies reasoning flaws.
Common Challenges in Evaluating AI Agents
Even with a well-designed framework, evaluating AI agents presents several complex challenges. Addressing these issues is critical to successfully monitoring AI agents in both development and production environments:
- Adversarial inputs: Agents must be robust against manipulative, ambiguous, or intentionally misleading queries that could exploit system weaknesses.
- Tool dependency: External APIs and third-party tools introduce variability and latency, impacting performance and evaluation reliability.
- Multi-agent interactions: In systems where multiple agents collaborate, failures in one agent can propagate to others, complicating evaluation and troubleshooting.
- Scalability: Testing agents at production scale requires infrastructure and tooling capable of simulating real-world conditions and heavy workloads.
- Iterative drift: As agents adapt, retrain, or learn over time, evaluation criteria must evolve to remain practical and relevant.
Evaluating Multi-Agent Systems and Inter-Agent Dependencies
Modern AI systems often consist of multiple interconnected agents, each responsible for specific tasks but dependent on the outputs of others. These agentic AI workflows introduce added complexity, making comprehensive evaluation essential to ensure system reliability and coordination.
Key areas to assess include:
- Dependency tracing: Monitor how one agent's output influences the behavior and decisions of downstream agents.
- Error propagation analysis: Identify where failures or hallucinations originate and how they cascade through the agent network.
- Inter-agent trust scoring: Measure the reliability of individual agents within the system and assess their influence on overall task completion.
- Workflow resilience testing: Simulate disruptions or input failures to evaluate the system's robustness and ability to recover gracefully.
Agentic Observability for Multi-Agent Systems
The Fiddler AI Observability and Security platform offers a robust foundation for monitoring and scaling agentic AI within enterprise-grade LLM applications. Through its multi-agent application, monitoring Fiddler delivers:
- Complete visibility into the agentic hierarchy, including agent workflows, behaviors, and decision paths.
- Faster issue identification and resolution with interactive root cause analysis allows teams to isolate and resolve performance or logic issues across the application, session, agent, and span levels.
- System-level intelligence and performance attribution through aggregated metrics and intelligent issue prioritization
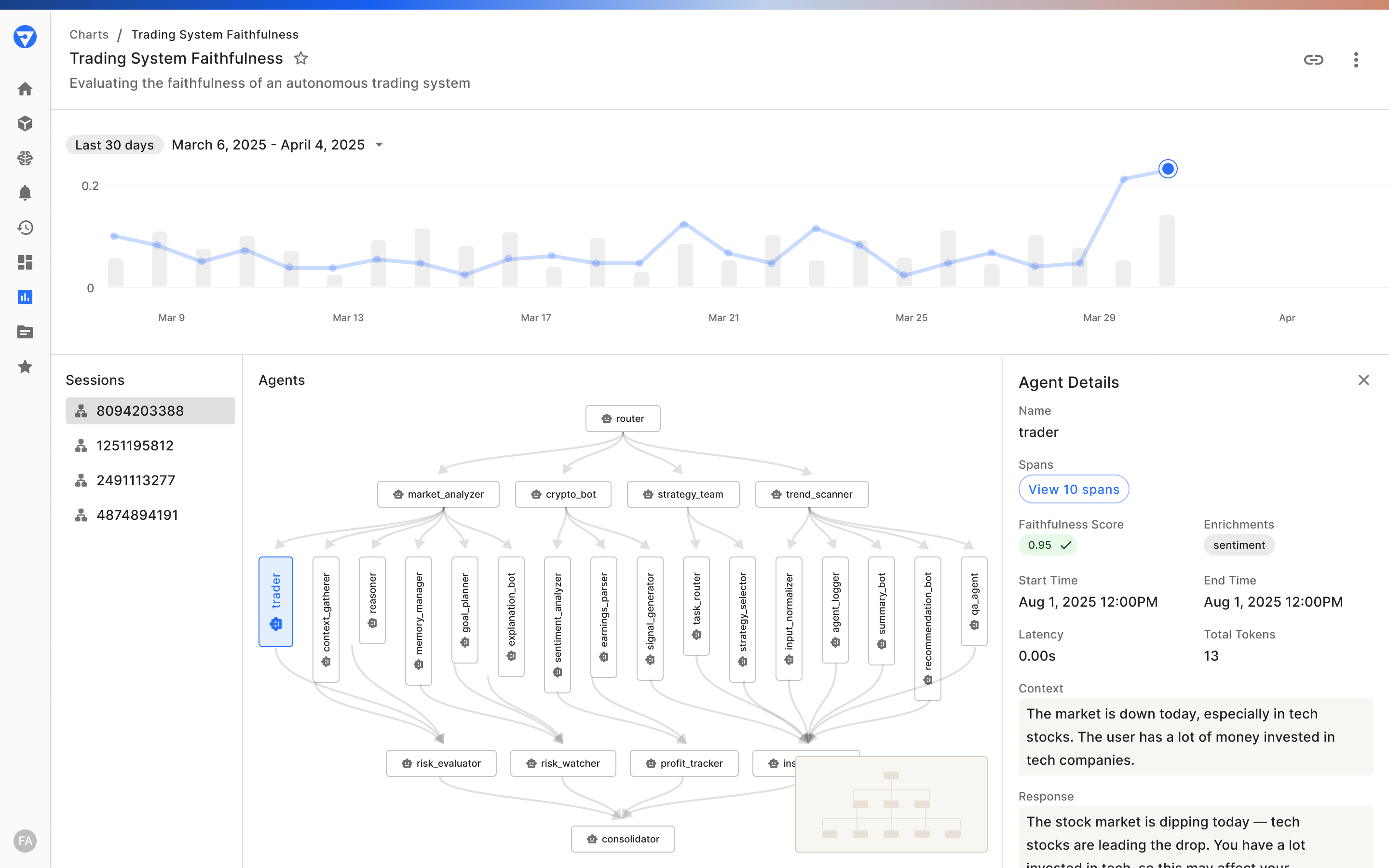
These capabilities empower enterprises to confidently develop, test, and deploy AI agents while maintaining complete control, trust, and accountability throughout the system lifecycle.
Comprehensive, Multi-Level Tracing
Fiddler delivers observability across four key dimensions:
- Application Level: High-level insights into app-wide performance and health.
- Session Level: Tracks user sessions for consistency and flow.
- Agent Level: Detailed metrics and logs for each agent.
- Span Level: Fine-grained visibility into every function call or decision point.
Root Cause Analysis and Diagnostics
When issues come up in production, enterprise teams need immediate visibility and precision to resolve them before they escalate. The Fiddler AI Observability and Security platform equips organizations with powerful diagnostics to streamline the evaluation process:
- Context-aware diagnostics: Surface detailed insights into agent behavior to pinpoint misalignments, bottlenecks, or execution failures.
- Cross-agent correlation: This capability is critical in multi-agent environments, as it traces how errors in one agent may propagate and impact other agents’ decision paths and tasks.
- Anomaly detection: Identify early signs of hallucinations, underperformance, or unsafe outputs before they affect users or business outcomes.
These advanced diagnostic tools significantly reduce time to resolution, enabling faster iteration cycles and more reliable agent performance at scale.
Cross-Application and Multi-Agent Insights
In modern enterprise environments, AI systems often span multiple applications and agents, each with unique responsibilities and dependencies. The Fiddler AI Observability and Security platform supports teams with the following:
- Unified analytics: A centralized dashboard for analyzing application and agent performance in distributed environments.
- Comprehensive aggregation of metrics: Visualize operational trends, outliers, and patterns through aggregated metrics across the application, not just logs or spans.
- Agent-to-agent interaction tracking: Gain visibility into how agents interact, share outputs, and impact one another's reliability in complex workflows.
Final Thoughts
Evaluating and monitoring AI agents is no longer optional; it's a business-critical capability for any enterprise embracing intelligent automation. As AI systems become increasingly agentic, autonomous, and interconnected, robust evaluation and monitoring are essential to ensure performance, trust, and alignment with business objectives and regulatory requirements.
The Fiddler AI Observability and Security platform provides enterprise teams with the comprehensive tools needed for success. From full-stack observability and root cause diagnostics to cross-agent correlation and performance tracking, Fiddler empowers organizations to excel at monitoring AI agents across development, deployment, and production.
Whether you're fine-tuning a single virtual assistant or orchestrating a complex network of LLM-powered agents, Fiddler delivers the transparency and control required to deploy AI responsibly and at scale.
Ready to elevate your AI agent evaluation strategy? Discover how our Trust Service for LLM application monitoring helps your team confidently evaluate, optimize, and scale enterprise AI systems — while maintaining trust, accountability, and reliability.
FAQs about AI Agent Evaluation
1. What is AI Agent Evaluation?
AI agent evaluation systematically assesses how well an AI agent performs assigned tasks, makes decisions, and interacts with users or systems. The goal is to determine whether the agent is reliable, efficient, and aligned with business, ethical, and regulatory standards. Evaluation typically involves a combination of testing methods, performance metrics, and continuous monitoring to ensure the agent remains effective throughout development and production.
2. How do you measure the performance of an agent in AI?
To measure the performance of an AI agent, organizations use a combination of quantitative and qualitative AI agent evaluation metrics, including:
- Task success rate – how accurately the agent completes defined objectives.
- Response time – assessing latency and system efficiency.
- Hallucination rate – especially relevant for LLM-powered agents to track inaccurate outputs.
- User satisfaction (CSAT/NPS) – for gauging perceived usefulness and trust.
- Scalability and reliability – evaluating performance under increased workload or real-world complexity.
These metrics are typically tracked through continuous monitoring of AI agents, enabling proactive optimization and issue resolution.
3. How do we create AI agents?
Creating AI agents involves designing systems that can autonomously perceive, reason, and act within a given environment or task. The process generally includes:
- Defining the agent's goal: Clarify the specific problem the agent will solve.
- Selecting the architecture: Choose between rule-based systems, machine learning models, or LLM-driven agents.
- Integrating tools and data: Connect APIs, databases, or knowledge sources the agent will rely on.
- Training and fine-tuning: Use relevant datasets to train models or configure behavior patterns.
- Testing and evaluation: Apply an agent evaluation framework to validate performance before deployment.
- Monitoring in production: Continuously track behavior through real-time metrics and feedback loops.
4. How do you build AI agents?
To build AI agents, teams must combine software development, machine learning, and system integration within a structured development lifecycle. Key steps include:
- Problem Scoping: Clearly define the agent's use case, goals, and success criteria.
- Model Selection: Based on the complexity and nature of the task, choose the most suitable approach, such as decision trees, reinforcement learning, or LLMs.
- Workflow Design: Outline the agent's decision-making logic, tool interactions, and action sequences to ensure operational coherence.
- Data Preparation: Collect and preprocess the relevant data required for model training, fine-tuning, or inference.
- Development and Integration: Build agents by coding core functionalities, integrating APIs or third-party tools, and maintaining modular, scalable design.
- Evaluation and Monitoring: Use AI agent evaluation methods and continuously monitor performance to ensure the agent remains effective, reliable, and aligned with its objectives in real-world environments.
By following these steps, organizations can build robust, adaptable agents ready for production-scale deployment.
