
Much has been written about the importance of addressing risks in AI—whether it's trying to avoid high-profile snafus or keeping models stable during sudden changes in the data. For solutions to these issues, the financial services industry is one to watch. They pioneered the idea of Model Risk Management (MRM) more than 15 years ago. But models have changed drastically since then, and the needs and solutions have changed as well. At the Ai4 2021 Finance Summit, Fiddler Founder & CEO Krishna Gade chatted with Sri Krishnamurthy, Founder of QuantUniversity, to learn more about how financial institutions are tackling the problems with black box ML. Watch the full conversation here.
From Model Risk Management to Responsible AI
"Managing models in the financial industry is not something new," Sri said. As he explained, the financial industry led the way in establishing a process for evaluating the implication of models. In the past, with stochastic models, the basic idea was to sample the population and make assumptions that would be applied more broadly. These relatively linear, simplistic assumptions could be explained clearly—and fully described in a tool like MatLab.
However, machine learning has introduced entirely new methodologies. AI models are much more complex. They are high-dimensional and constantly adapt to the environment. How do you explain to the end-user what the model is doing behind the scenes? Responsible AI is about being able to perform this contextualization, and also putting a well-defined framework behind the adoption and integration of these newer technologies.
Responsible AI essentially goes hand in hand with fiduciary responsibility. Decisions made by models can affect individual assets and even society as a whole. "If you are a company which gives millions and millions of credit cards to people, and you have built a model which has either an explicit or an implicit bias in it, there are systemic effects," Sri said. That’s why it’s so important for the financial industry to really understand models and have the right practices in place, rather than just rushing to adopt the latest AutoML or deep neural network technologies.
The challenges of validating ML models
When we asked Sri about the challenges of validating models, a key factor was the variation in how teams are adopting ML across the industry. For example, one organization might have 15 PhDs developing models internally, while another might have their MRM team of 1-2 individuals, who are probably not experts in ML, using machine learning as a service, calling an API, and consuming the output. Or they might be integrating an open source model that they didn’t build themselves.
Teams who are developing models internally are better prepared to understand how the models work, but traditional MRM teams may not be as well-equipped. Their goals are twofold: to verify that the model is robust, and to validate that the model is applied in the right scenarios and can handle any potential challenges from an end-user. With black box models, "you’re kind of flying in the dark," Krishnamurthy said. Tools for Explainable AI are an important piece of the puzzle.
Human error can complicate model validation as well. "Models are not necessarily automated—there are always humans in the loop," Sri explained. This can lead to the so-called "fat finger effect" where an analyst makes a mistake in the model input: instead of .01, they enter 0.1. With MRM teams demanding a seat at the table to address these kinds of problems, the model validation field itself is evolving.
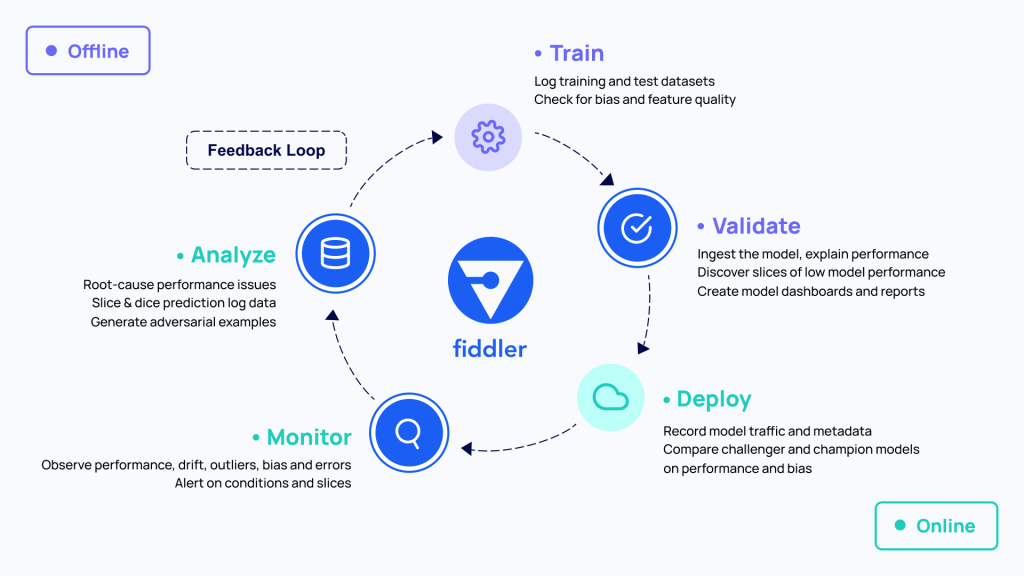
Model lifecycle management
Bad input data, whether it’s caused by a human or automated process, is just one thing that organizations have to be prepared for when implementing AI. Sri identified four main areas of focus: (1) the code, (2) the data, (3) the environment where the model runs (on-prem, in the cloud, etc.), and (4) the process of deploying, monitoring, and iterating on the model. Sri summed it up by saying "It’s not model management anymore—it’s model lifecycle management."
At Fiddler, we’ve come to the same realization. "We started with AI explainability to unlock the black box," said Krishna, "but then we wondered—at what point should we explain it? Before training? Post-production deployment?" We had to step back and consider the entire lifecycle, from the data to validating and comparing models, and on to deployment and monitoring. What’s needed in the ML toolkit is a dashboard that sits at the center of the ML lifecycle and watches throughout, tracking all the metadata. From working in the industry, we’ve seen how common silos are: the data science team builds a model, ships it over to risk management, and then a separate MLOps team may be responsible for productionization. A consistent, shared dashboard can bring teams together by giving everyone insight into the model.
As Sri explained, when teams are just "scratching the surface and trying to understand what ML is," it can be quite a pragmatic challenge to also implement AI responsibly. Doing everything in-house probably isn’t realistic for a lot of teams. Consultants and external validators can help, and having the right tools available will go a long way towards making Responsible AI accessible—not just for finance, but for every industry.