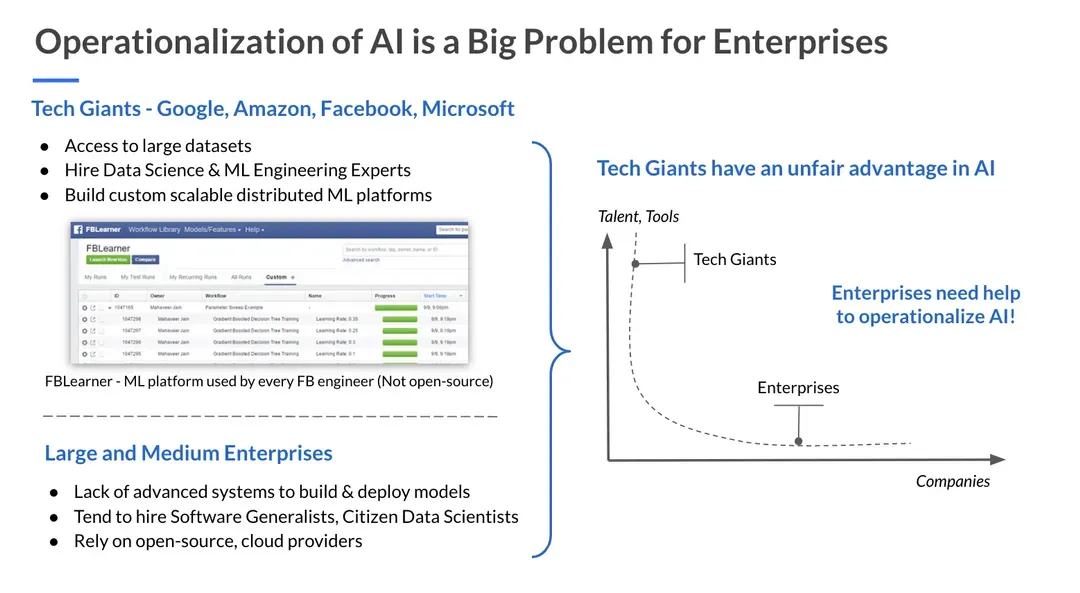
In today’s world, data has played a huge role in the success of technology giants like Google, Amazon, and Facebook. All of these companies have built massively scalable infrastructure to process data and provide great product experiences for their users. In the last 5 years, we’ve seen a real emergence of AI as a new technology stack. For example, Facebook built an end-to-end platform called FBLearner that enables an ML Engineer or a Data Scientist build Machine Learning pipelines, run lots of experiments, share model architectures and datasets with team members, scale ML algorithms for billions of Facebook users worldwide. Since its inception, millions of models have been trained on FBLearner and every day these models answer billions of real-time queries to personalize News Feed, show relevant Ads, recommend Friend connections, etc.
However, for most other companies building AI applications remains extremely expensive. This is primarily due to a lack of systems and tools for supporting end-to-end machine learning (ML) application development — from data preparation and labeling to operationalization and monitoring [1][9][10][11].
The goal of this post is 2-fold:
- List the challenges with adopting AI successfully: data management, model training, evaluation, deployment, and monitoring;
- List the tools I think we need to create to allow developers to meet these challenges: a data-centric IDE with capabilities like explainable recommendations, robust dataset management, model-aware testing, model deployment, measurement, and monitoring capabilities.
Challenges of adopting AI
In order to build an end-to-end ML platform, a data scientist has to go through multiple hoops of the following workflow [3].
End-to-End ML Workflow
A big challenge to building AI applications is that different stages of the workflow require new software abstractions that can accommodate complex interactions with the underlying data used in AI training or prediction. For example:
Data Management requires a data scientist to build and operate systems like Hive, Hadoop, Airflow, Kafka, Spark etc to assemble data from different tables, clean datasets, procure labeling data, construct features and make them ready for training. In most companies, data scientists rely on their data engineering teams to maintain this infrastructure and help build ETL pipelines to get feature datasets ready.
Training models is more of an art than science. It requires understanding which features work and what modeling algorithms are suitable to the problem at hand. Although there are libraries like PyTorch, TensorFlow, Scikit-Learn etc, there is a lot of manual work in feature selection, parameter optimization, and experimentation.
Model evaluation is often performed as a team activity since it requires other people to review the model performance across a variety of metrics from AUC, ROC, Precision/Recall and ensure that model is calibrated well, etc. In the case of Facebook, this was built into FBLearner, where every model created on the platform would get an auto-generated dashboard showing all these statistics.
Deploying models requires data scientists to first pick the optimal model and make it ready to be deployed to production. If the model is going to impact business metrics of the product and will be consumed in a realtime manner, we need to deploy it to only a small % of traffic and run an A/B test with an existing production model. Once the A/B test is positive in terms of business metrics, the model gets rolled out to 100% of production traffic.
Inference of the models is closely tied with deployment, there can be 2 ways a model can be made available for consumption to make predictions.
- batch inference, where a data pipeline is built to scan through a dataset and make predictions on each record or a batch of records.
- realtime inference, where a micro-service hosts the model and makes predictions in a low-latency manner.
Monitoring predictions is very important because unlike traditional applications, model performance is non-deterministic and depends on various factors such as seasonality, new user behavior trends, data pipeline unreliability leading to broken features. For example, a perfectly functioning Ads model might need to be updated when a new holiday season arrives or a model trained to show content recommendations in the US may not do very well for users signing up internationally. There is also a need for alerts and notifications to detect model degradation quickly and take action.
As we can see, the workflow to build machine learning models is significantly different from building general software applications. If models are becoming first-class citizens in the modern enterprise stack, they need better tools. As Tesla’s Director of AI Andrej Karpathy succinctly puts it, AI is Software 2.0 and it needs new tools [2].
If we compare the developer stack of Software 1.0 with 2.0, I claim we require transformational thinking to build the new developer AI stack.
We need new tools for AI engineering
In Software 1.0, we have seen a vast amount of tooling built in the past few decades to help developers write code, share it with other developers, get it reviewed, debug it, release it to production and monitor its performance. If we were to map these tools in the 2.0 stack, there is a big gap!
What would an ideal Developer Toolkit look like for an AI engineer?
To start with, we need to take a data-first approach as we build this toolkit because, unlike Software 1.0, the fundamental unit of input for 2.0 is data.
Integrated Development Environment (IDE): Traditional IDEs focus on helping developers write code, focus on features like syntax highlighting, code checkpointing, unit testing, code refactoring, etc.
For machine learning, we need an IDE that allows easy import and exploration of data, cleaning and massaging of tables. Jupyter notebooks are somewhat useful, but they have their own problems, including the lack of versioning and review tools. A powerful 2.0 IDE would be more data-centric, starts with allowing the data scientist to slice and dice data, edit the model architecture either via code or UI and debug the model on egregious cases where it might be not performing well. I see traction in this space with products like StreamLit [13] reimagining IDEs for ML.
Tools like Git, Jenkins, Puppet, Docker have been very successful in traditional software development by taking care of continuous integration and deployment of software. When it comes to machine learning, the following steps would constitute the release process.
Model Versioning: As more models get into production, managing the various versions of them becomes important. Git can be reused for models, however, it won’t scale for large datasets. The reason to version datasets is that to be able to reproduce a model, we need the snapshot of the data the model was trained upon. Naive implementations of this could explode the amount of data we’re versioning, think 1-copy-of-dataset-per-model-version. DVC [12] which is an open-source version control system is a good start and is gaining momentum.
Unit Testing is another important part of the build & release cycle. For ML, we need unit tests that catch not only code quality bugs but also data quality bugs.

Canary Tests are minimal tests to quickly and automatically verify that the everything we depend on is ready. We typically run Canary tests before other time-consuming tests, and before wasting time investigating the code when the other tests are failing [8]. In Machine Learning, it means being able to replay a previous set of examples on the new Model and ensuring that it meets certain minimal set of conditions.
A/B Testing is a method of comparing two versions of an application change to determine which one performs better [7]. For ML, AB testing is an experiment where two or more variations of the ML model are exposed to users at random, and statistical analysis is used to determine which variation performs better for a given conversion goal. For example in the dashboard below, we’re measuring click conversion on an A/B experiment dashboard that my team built at Pinterest, and it shows the performance of the ML experiments against business metrics like repins, likes, etc. CometML [14] lets data scientists keep track of ML experiments and collaborate with their team members.
Debugging: One of the main features of an IDE is the ability to debug the code and find exactly the line where the error occurred. For machine learning, this becomes a hard problem because models are often opaque and therefore exactly pinpointing why a particular example was misclassified is difficult. However, if we can understand the relationship between feature variables and the target variable in a consistent manner, it goes a long way in debugging models, also called model interpretability, which is an active area of research. At Fiddler, we're working on a product offering that allows data scientists to debug any kind of models and perform root cause analysis.
Profiling: Performance analysis is an important part of SDLC in 1.0 and profiling tools allow engineers to figure out slowness of an application and improve it. For models, it is also about improving performance metrics like AUC, log loss, etc. Often times, a given model could have a higher score on an aggregate metric but it can be performing poorly on certain instances or subsets of the dataset. This is where tools like Manifold [5] can enhance the capabilities of traditional performance analysis.
Monitoring: While superficially, application monitoring might seem similar to model monitoring and could actually be a good place to start, we need to track a different class of metrics for machine learning. Monitoring is crucial for models that automatically incorporate new data in a continual or ongoing fashion at training time, and is always needed for models that serve predictions in an on-demand fashion. We can categorize monitoring into 4 broad classes:
- Feature Monitoring: This is to ensure that features are stable over time, certain data invariants are upheld, any checks w.r.t privacy can be made as well as continuous insight into statistics like feature correlations.
- Model Ops Monitoring: Staleness, regressions in serving latency, throughput, RAM usage, etc.
- Model Performance Monitoring: Regressions in prediction quality at inference time.
- Model Bias Monitoring: Unknown introductions of bias both direct and latent.
Conclusion
I walked through 1) some challenges to successfully deploying AI (data management, model training, evaluation, deployment, and monitoring), 2) some tools I propose we need to meet these challenges (a data-centric IDE with capabilities like slicing & dicing of data, robust dataset management, model-aware testing, and model deployment, measurement, and monitoring capabilities). If you are interested in some of these tools or an Artificial Intelligence technology stack, we’re working on them at Fiddler Labs. And if you're interested in building these tools, we would love to hear from you at https://angel.co/fiddler-labs
References
- https://arxiv.org/pdf/1705.07538.pdf
- https://medium.com/@karpathy/software-2-0-a64152b37c35
- https://towardsdatascience.com/technology-fridays-how-michelangelo-horovod-and-pyro-are-helping-build-machine-learning-at-uber-28f49fea55a6
- https://christophm.github.io/interpretable-ml-book/
- https://eng.uber.com/manifold/
- https://www.fiddler.ai
- https://www.optimizely.com/optimization-glossary/ab-testing/
- https://dzone.com/articles/canary-tests
- https://research.fb.com/wp-content/uploads/2017/12/hpca-2018-facebook.pdf
- http://stevenwhang.com/tfx_paper.pdf
- https://papers.nips.cc/paper/5656-hidden-technical-debt-in-machine-learning-systems.pdf
- https://dvc.org/
- https://streamlit.io/
- https://www.comet.ml/