Total Cost of Ownership for Evaluating Agents
Every observability platform promises visibility into your agents. But most don't tell you what it actually costs to evaluate them at scale. Your evaluation TCO is more than you may realize: there is a hidden cost called the Evaluation Trust Tax, incident risk exposure, and operational overhead.
How Platforms Evaluate Agents with LLMs
- Your trace is generated by your agent
- The trace triggers API calls to an LLM provider for evaluation (OpenAI, Anthropic, etc.)
- The API costs show up on the bill from your LLM provider
- You pay the Evaluation Trust Tax
What Your Evaluation Cost Looks Like At Scale
Evaluation costs grow with trace volume, tokens per trace, and the number of evaluations per trace. Sampling plays a role too with LLMs. Centor Models do not sample and their costs are a step function compared to LLM costs that grow linearly. As your deployment sizes grow, the cost difference compounds at scale.
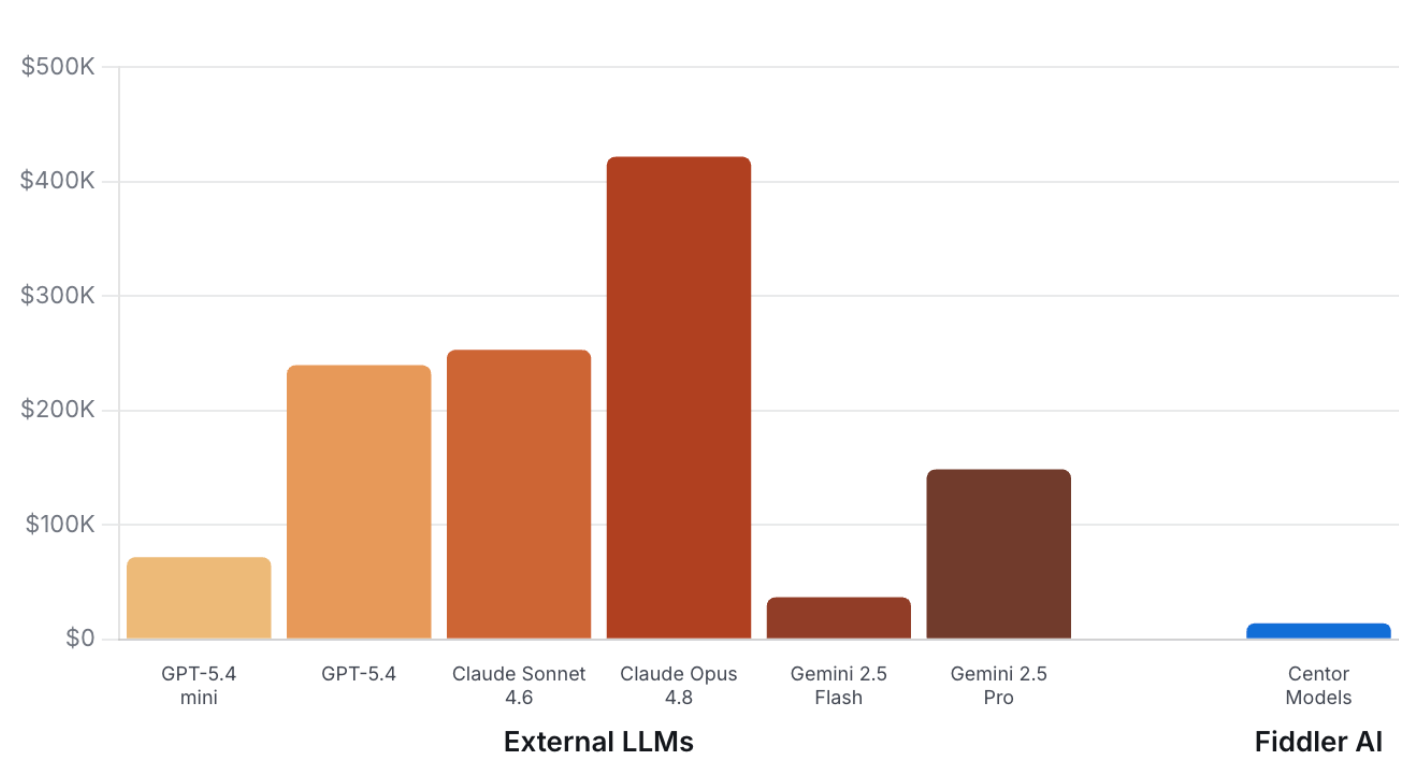
98% Cheaper
Fiddler Centor Models evaluate every trace, yet cost up to 98% less than external LLMs that sample 10% of the traces.
How External LLM Calls Drive Up Your Evaluation TCO
- The Evaluation Trust Tax: You are charged every time a trace is evaluated via an external LLM call. This shows up on your LLM provider’s bill. At enterprise scale, it compounds fast.
- Incident Risk Exposure: To control costs, some teams may consider sampling, but the traces you skip could be the ones that matter most. These are low-frequency, high-impact events that sampling can miss.
- Operational Overhead: Engineering time and effort should go to building agents, not maintaining evaluation infrastructure: API orchestration, model hosting, prompt versioning, and calibration.
Fiddler Centor Models For Evals and Policy Enforcement
Fiddler Centor Models (formerly known as Fiddler Trust Models) are cost-effective and secure models integral to the Fiddler AI Control Plane. They power the industry's fastest guardrails and evaluations, with no sampling, and no external LLM API costs. Whether evaluations require low-latency, task-specific evaluators or complex reasoning evaluators with high accuracy, Centor Models keep evaluation TCO low as agent traffic scales.
Teams can also bring their own judges (BYOJ) into Fiddler to use preferred LLMs alongside Centor Models, fitting the right evaluator to each agent and LLM project.
Centor Models come in two types:
- Out-of-the-Box Models
- Hallucination detection, safety scoring, toxicity, jailbreak detection, and PII/PHI identification
- Ultra low-latency, cost-effective, and task-specific
- Customizable Models
- Domain-specific prompt-based evaluators
- Built for complex, high accuracy reasoning
Trusted by Industry Leaders and Developers
Frequently Asked Questions
What is the Evaluation Trust Tax?
External LLM-as-a-Judge is a common approach to evaluating AI outputs: you use a large language model like GPT-5.4 to evaluate the quality, safety, or accuracy of another model's responses. It's flexible and easy to set up, but it breaks down at scale. Every evaluation is an external API call, which means unpredictable costs, added latency, and data leaving your environment. For enterprises running millions of traces per day, those API calls become a material line item. That's the evaluation Trust Tax: these external LLM API costs grow as you evaluate more metrics and agent traffic grows, and show up on your OpenAI or Anthropic invoice (not your observability vendor's). AI teams down sample to control evaluation costs but this approach introduces risks from unevaluated traces.
What is External LLM-as-a-judge and why does it create a Trust Tax?
External LLM-as-a-Judge is a common approach to evaluating AI outputs: you use a large language model like GPT-5.4 to evaluate the quality, safety, or accuracy of another model's responses. It's flexible and easy to set up, but it breaks down at scale. Every evaluation is an external API call, which means unpredictable costs, added latency, and data leaving your environment. For enterprises running millions of traces per day, those API calls become a material line item. That's the evaluation Trust Tax: these external LLM API costs grow as you evaluate more metrics and agent traffic grows, and show up on your OpenAI or Anthropic invoice (not your observability vendor's). AI teams down sample to control evaluation costs but this approach introduces risks from unevaluated traces.
Does the Trust Tax apply to agentic workflows?
Yes, and the impact compounds. Agentic workflows generate multiple traces per interaction as agents plan, reason, and take actions across steps. Each trace evaluated via an external LLM is another API call. The more complex your agent workflows, the faster the Trust Tax grows. Fiddler Centor Models evaluate every trace in your environment without external LLM API costs, regardless of how many steps your agents take.
What questions should I ask an AI observability vendor about the Trust Tax?
- Where do your evaluation models run: in my environment, or through an external API?
- What does each evaluation cost at my expected trace volume, and how does that scale?
- What percentage of traces do you evaluate by default? What happens to the ones you skip?
- Does your platform send any of my AI output data to a third-party provider for evaluation?
- Can you provide a total cost of ownership estimate that includes evaluation costs, not just platform fees?
What are the risks beyond the evaluation Trust Tax?
External evaluation calls create three problems beyond the bill:
- Incident Risk Exposure: Aggressive sampling to control costs means you're not evaluating every trace, and the ones you skip may be the ones that matter most: jailbreaks, policy violations, rare hallucinations.
- Operational overhead: Without built-in evaluation models, your team owns model selection, prompt versioning, and calibration. That's engineering time that doesn't ship products.
- Data exposure: Sending AI outputs to a third-party API means your data, potentially including sensitive customer information, leaves your environment on every evaluation call.