
Key Takeaways
- Traditional testing fails for agentic apps because LLM outputs are non-deterministic. Evals replace eyeballing with quantitative scores, giving you the same confidence for LLM code that unit tests give deterministic code.
- The EDD inner loop (run, analyze, fix, re-run) is mechanical enough to automate. A coding agent can handle iteration autonomously, reverting regressions via git and stopping when scores plateau or converge.
- Modular agent design is a prerequisite. If your agent does everything in one prompt and one tool loop, there is nothing to eval in isolation. Discrete nodes make each step independently testable and improvable.
Agentic applications built with large language models are inherently non-deterministic. The same input can produce different outputs on every run. This makes traditional testing methods fall short, which is why evals serve as automated evaluations that score an agent’s outputs quantitatively, the same way tests validate deterministic code.
Eval-Driven Development (EDD) is a natural way to use evals to iteratively improve the outcomes of non-deterministic agentic code. In this post, we show how to automate the full EDD cycle using Fiddler Evals for quantitative scoring and OpenCode agents for autonomous improvement.
The Workflow That Doesn't Work
Here's how most teams ship agentic applications today:

You write some LLM-powered code, consisting of a prompt, tool definitions, an orchestration harness, you deploy it, and you monitor how this application behaves in production. Maybe you run it a few times locally first. If the outputs look reasonable, you ship it.
This workflow, that doesn’t include any tests, would seldom be recommended by anyone for deterministic software deployed on production. And if this doesn't work for traditional applications with deterministic outcomes, why would this be any different for agentic applications where there are several non-deterministic outcomes.
For example, ask an LLM agent to generate a database query from a natural language question, and it might produce a different query on every invocation. The output is non-deterministic. Running it three times locally and eyeballing the results tells you almost nothing about how it will behave across hundreds of real inputs in production.
You don't find out until users report broken results.
Evals: Tests for Non-Deterministic Code
So what are tests for non-deterministic code? Well, the answer is evals, automated evaluations that score your agent's outputs quantitatively, the same way tests validate deterministic code. In essence it tries to give you the same confidence for non-deterministic LLM outputs that tests give you for deterministic code.
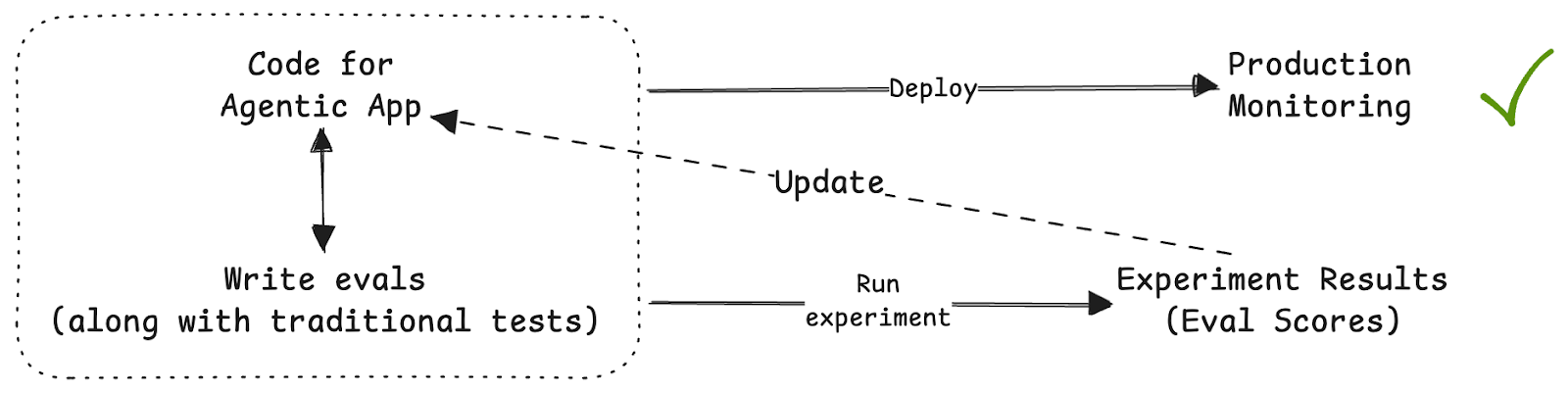
So now, before you deploy, you:
- Write evals alongside your agentic code, just as you'd write tests alongside application code. Each eval defines test cases (input questions and expected outputs) and evaluators that score the agent's actual output against what's expected.
- Run Experiments: Execute the agent against your test cases and score every output. Instead of "does this look right?", you get numbers. For example, a score to judge how close the generated SQL query is to the expected SQL.
- Use the Scores to Update the Code: Low scores tell you that the agentic code doesn’t work as well as expected, and that a prompt might need to be updated to ensure that the scores improve.
- Re-Run and Verify: And after updating the code, run the experiment again. Did scores improve? Did anything regress?
The Manual Iteration Problem
This is a promising approach, but doing it by hand is painful in practice where we need to go through the following steps manually before we get some confidence in how the non-deterministic code behaves:
- Run the eval suite
- Analyze the scores
- Identify which cases are failing and form a hypothesis about why
- Edit the prompt or harness code
- Run the eval again
- Compare scores to the previous run — did things improve? Did anything regress?
- Repeat
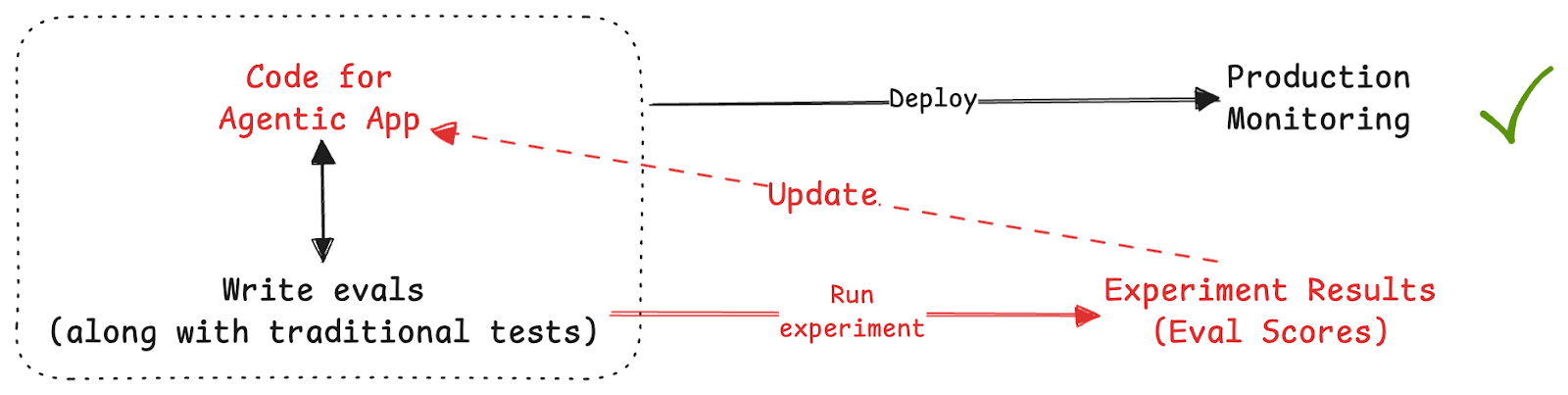
Each iteration takes real time. Reading through 150 scored SQL generation test cases to find patterns in the failures isn't quick. And after you make a change, you need to re-run everything and carefully compare results from previous run, because a prompt edit that improves on something might quietly break error-rate queries.
Due to its mechanical nature, this cycle is an obvious candidate for automation.
Automating the Inner Loop
So, what if a coding agent could handle the iteration cycle for you?
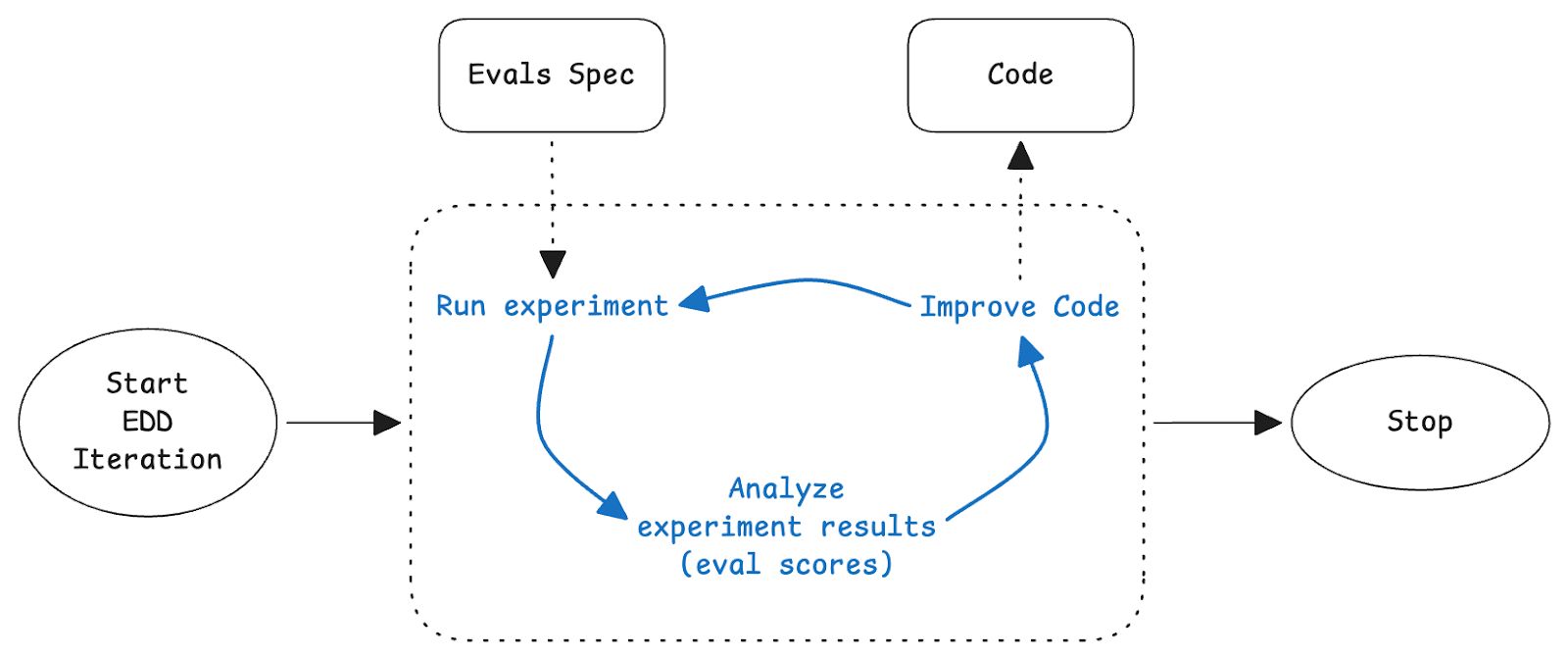
The agent handles the tedious part: running experiments, analyzing scores, updating the agentic code, and re-running to verify. The developer writes the evals (the specification of correct behavior) and reviews the final result before deploying.
This pattern, similar to test-driven development (TDD), but adapted for non-deterministic code, can sometimes be referred to as Eval-driven development (EDD). Here the eval is the spec. The agent's job is to make the code satisfy the spec. When scores converge or plateau, the agent stops and presents its changes for human review.
Example: Automated EDD with Fiddler Evals and OpenCode
We tested this automated loop through an OpenCode agent paired with Fiddler Evals for quantitative scoring to improve outcomes of an agentic application, obs-query, that takes a question from a user related to live infrastructure, and responds with insights derived from relevant metrics data.
This is the workflow that is followed by the application:
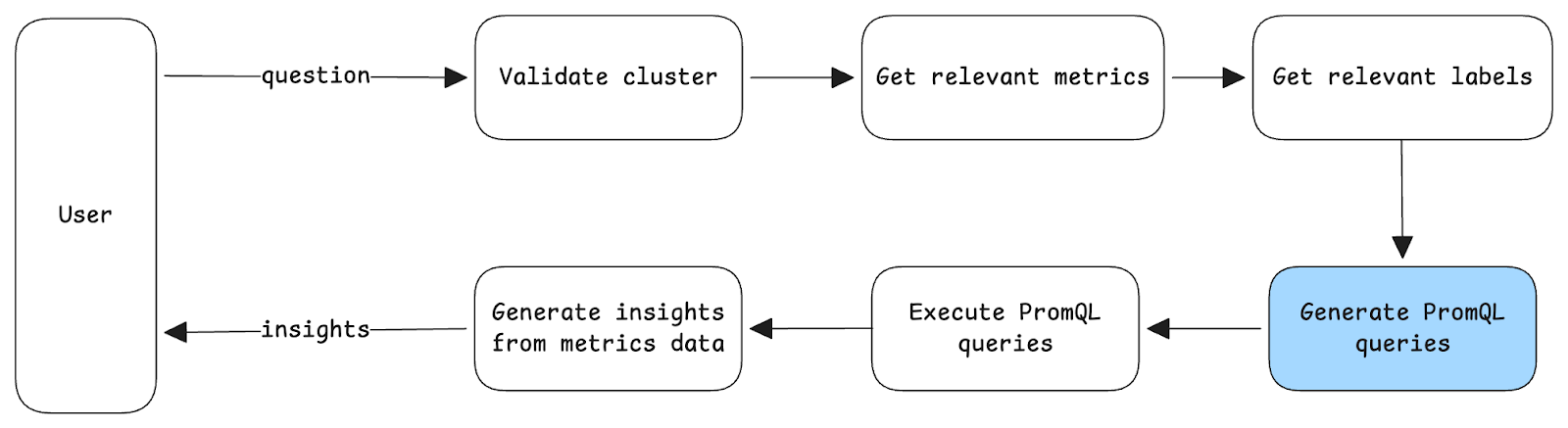
While each of these steps are modular units that can be individually tested, let us consider the node that generates Prometheus (PromQL) queries to fetch metrics data.
This node implements a generate_promql() function containing the core logic where a prompt is fed to an LLM along with relevant metrics and filters so that the LLM can generate the PromQL queries.
We need to evaluate if the queries generated are semantically correct against what is expected. For this an eval spec (defined in eval_promql_generation.py) specifies the expected behaviour through a dataset that contains a sample of input parameters, and a set of expected PromQL queries.
Here is an example of a test case from the dataset:
{
"inputs": {
"question": "What is the CPU usage of the fiddler-api container in staging?",
"cluster_name": "staging",
"metrics": [
"container_cpu_usage_seconds_total",
"container_memory_working_set_bytes",
"container_spec_cpu_quota",
"..."
],
"labels": [
"cluster", "namespace", "pod", "container",
"node", "service", "..."
]
},
"expected": {
"expected_promql": "rate(container_cpu_usage_seconds_total{cluster=\"staging\", container=\"fiddler-api\"}[5m])"
},
"category": "cpu_basic"
}We initiate an EDD session through the OpenCode agent:
This initiates the following loop that improves the logic implemented in generate_promql() iteratively over sequential experiment runs against the eval spec.
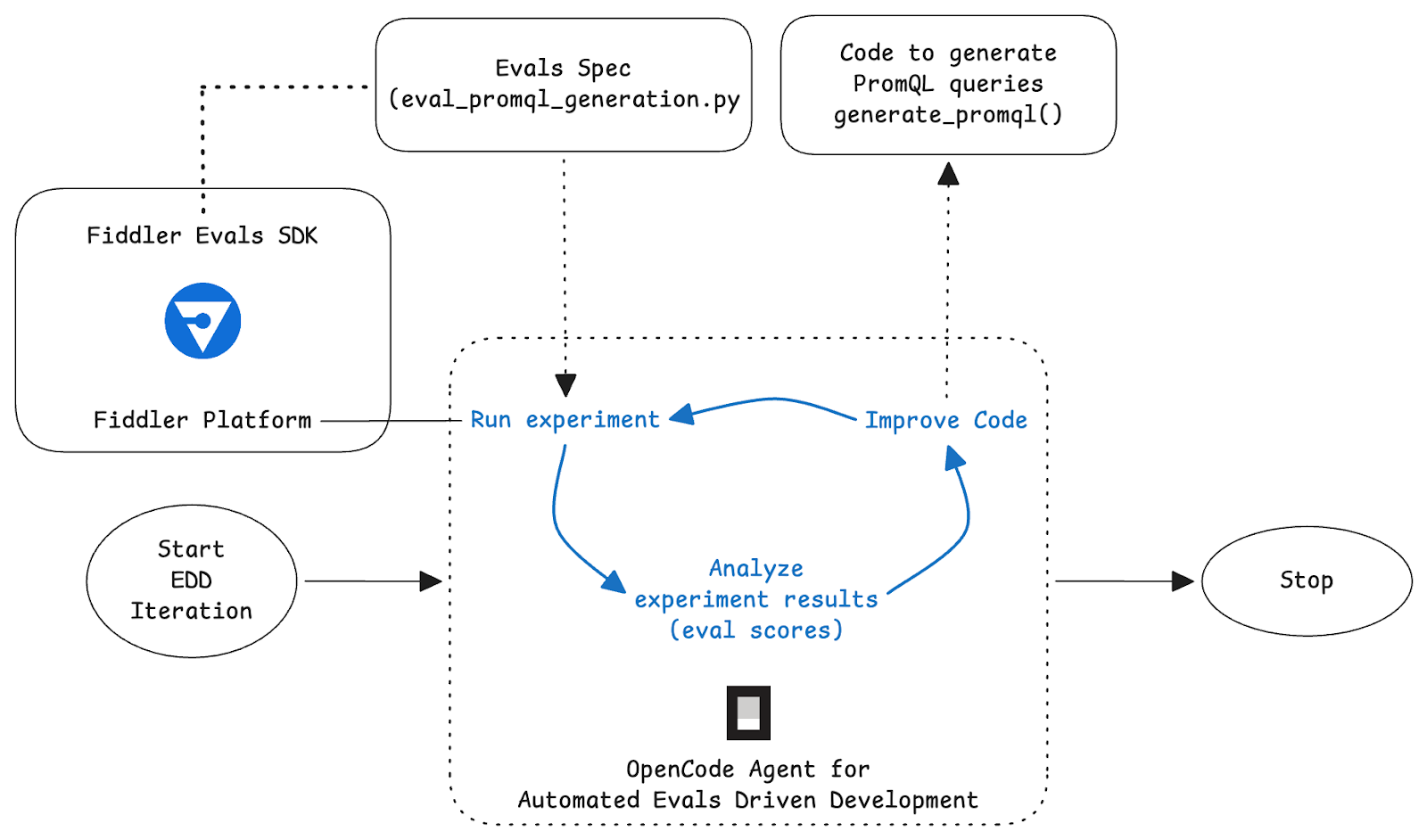
The Loop
Step 1: Run Experiment. The agent executes the eval. Each test case, a natural language question paired with an expected PromQL query, is run through the generate_promql() function. The generated queries are scored by Fiddler Evals using an LLM-as-judge evaluator that rates semantic correctness on a 0.0-1.0 scale.
Step 2: Analyze Scores. The agent reads the per-case and aggregate results from the experiment run and examines which test cases scored lowest and looks for patterns. It reads the source code consisting of the system prompt, the context-construction logic, and forms a hypothesis about what to change.
Step 3: Improve or Stop. Based on the analysis, the agent either:
- Improves the harness code by editing the system prompt, the context passed to the LLM, or the post-processing logic and then loops back to Step 1.
- Or Reports and stops if scores are satisfactory, or if the agent has hit a stopping condition.
Stop Conditions
The agent checks three conditions after every run:
- Satisfactory: Scores meet the threshold. The agent reports the final scores and changes made. Done.
- Regression: The aggregate score dropped below the best seen score. The agent auto-reverts its changes via
gitrestore and stops. This prevents a bad edit from shipping. - Plateau: No improvement for a configurable number of consecutive runs. The agent reports that prompt-level changes have hit their ceiling. Further improvements like architectural changes (better context, different tools, restructured agent design) would involve a human to make the decisions.
What Makes This Possible: Modular Agent Design
The automated EDD loop only works if you can evaluate individual parts of your agent in isolation. An agent that does everything in a single `run()` function is hard to eval because when the end-to-end output is wrong, there is no way to tell which step failed.
For example, the original obs-query agent had a single system prompt responsible for everything: metric discovery, PromQL generation, query execution, and insight generation, all driven by tool calls in an unpredictable sequence:
SYSTEM_PROMPT = """You are an expert observability agent specializing in Prometheus/Mimir metrics.
Your job is to answer user questions about their infrastructure by querying metrics data.
## Workflow
1. EXPLORE FIRST: use search_metrics, discover_labels, and
get_label_values to understand what's available.
2. VALIDATE: After executing a query, check if results are
meaningful. Adjust and try again if needed.
3. ITERATE: You may need multiple attempts to find the right
metric and label combination.
4. RENDER: Once you have validated data, call render_chart
exactly once with the final results.
## PromQL Guidelines
- Use rate() for counter metrics ...
- Use avg(), sum(), max(), min() for aggregations ...
## Time Range Guidelines ...
## Cluster Scoping ...
## Important Rules ...
"""There was no way to evaluate whether PromQL generation was working correctly because it wasn't a discrete step. Metric discovery, query construction, and insight generation were all interleaved in the same prompt and tool loop.
Refactoring to a modular pipeline made each step independently testable:
builder.add_node("validate_cluster", self.validate_cluster)
builder.add_node("discover_metrics", self.discover_metrics)
builder.add_node("generate_promql", self.generate_promql)
builder.add_node("execute_query", self.execute_query)
builder.add_node("generate_insight", self.generate_insight)
builder.add_edge(START, "validate_cluster")
builder.add_edge("discover_metrics", "generate_promql")
builder.add_edge("generate_promql", "execute_query")
builder.add_edge("execute_query", "generate_insight")Now to eval a single node, you build a minimal subgraph containing just that node, pass it fixture data, and run test cases against it in isolation:
# Minimal graph: just the PromQL generation node
builder = StateGraph(AgentState)
builder.add_node("generate_promql", agent.generate_query)
builder.add_edge(START, "generate_promql")
builder.add_edge("generate_promql", END)
graph = builder.compile()When the EDD agent identifies low scores, it knows exactly which node's prompt to update.
Conclusion
As agentic applications move from prototypes to production systems, EDD could become as standard as TDD is for traditional software.
By pairing Fiddler Evals with coding agents like OpenCode, the tedious inner loop of running experiments, analyzing failures, iterating on prompts, and verifying improvements can happen automatically while safely reverting regressions.
The obs-query example shows how modular design makes this practical and powerful. The question is no longer whether we need evals, but whether we still need to run the EDD loop manually.
Frequently Asked Questions
What is an LLM evaluation pipeline and how does it work?
An LLM evaluation pipeline is an automated system that runs test cases through an AI agent, scores the outputs using defined evaluators (such as LLM-as-judge), and returns quantitative results. It replaces manual output review with repeatable, measurable scoring across every input in your test dataset.
How do you test non-deterministic AI agent outputs?
You use evals, automated evaluations that score agent outputs against expected results on a defined scale. Unlike unit tests for deterministic code, evals account for variability by measuring semantic correctness across many inputs rather than checking for an exact match.
What is the difference between TDD and eval-driven development?
Test-driven development (TDD) validates deterministic code with pass/fail assertions. Eval-driven development (EDD) adapts this approach for agentic AI, where outputs are non-deterministic. Instead of binary pass/fail, EDD uses scored evaluations to measure correctness and guide iterative prompt and code improvements.
How do you prevent regressions when iterating on prompts?
Use a scoring threshold and auto-revert logic in your eval loop. After each prompt edit, re-run the full eval suite and compare aggregate scores against the best-seen run. If scores drop below that baseline, automatically restore the previous version via version control before any changes ship.
Why does modular agent design matter for LLM evaluations?
Modular agent design breaks an agentic application into discrete, independently testable nodes. When each step (such as query generation or metric discovery) runs as a separate unit, you can eval it in isolation, identify exactly which node is underperforming, and improve it without noise from unrelated steps. A monolithic single-prompt agent makes it impossible to pinpoint failures.