
A new class of software is quietly becoming part of how people work and communicate. Autonomous AI assistants or “super agents,” platforms that connect large language models to messaging channels, tools, and real-world actions, are no longer experiments. They are running continuously on personal hardware, fielding messages across WhatsApp, Slack, Discord, and iMessage, executing browser actions, writing and running code, and making decisions on behalf of their users around the clock.
OpenClaw is a leading example of this new generation. It is a sophisticated, open-source AI gateway that routes conversations across a dozen messaging platforms simultaneously, coordinates multiple agent sessions, and provides a rich toolkit of autonomous capabilities: browser control, file management, scheduled tasks, cross-platform messaging. It is the kind of system that, once deployed, runs in the background of a person's digital life, handling real interactions with real consequences.
And like most platforms in this emerging category, it has a significant gap: observability.
Agents are Opaque by Nature
Traditional software is, at its core, deterministic. Given the same input, a conventional application follows the same code path and produces the same output. Debugging is hard, but it is at least bounded: you can reason about what should have happened and compare it to what did.
AI agents break that assumption fundamentally. An agent deciding which tool to call, how to interpret ambiguous intent, whether to ask a clarifying question or make an assumption, these are not deterministic choices. They emerge from a model's learned behavior, shaped by context, conversation history, system prompt, and the particular state of the world at the moment of inference. Two identical-looking inputs can produce meaningfully different outputs. The same agent can behave differently across sessions, across model versions, or simply across time.
That unpredictability is not a bug. It is what makes agents genuinely useful. But it creates an observability problem that has no parallel in classical software engineering: you cannot reason about what an agent should have done the way you can reason about what a function should have returned. You need to observe what it actually did, at every step, with enough context to understand why.
Without that visibility, operating an AI agent in production is closer to faith than engineering.
Where the Gap Shows Up in Practice
OpenClaw's architecture compounds the observability challenge in several ways worth naming directly.
Multi-Agent Coordination Failures
OpenClaw supports multiple concurrent agent sessions that can interact with each other. When something goes wrong in a multi-agent workflow, a message routed to the wrong session, a coordination loop that never terminates, a sub-agent that fails silently, tracing the failure back to its origin requires correlation across the entire chain of events. Without it, the root cause is opaque.
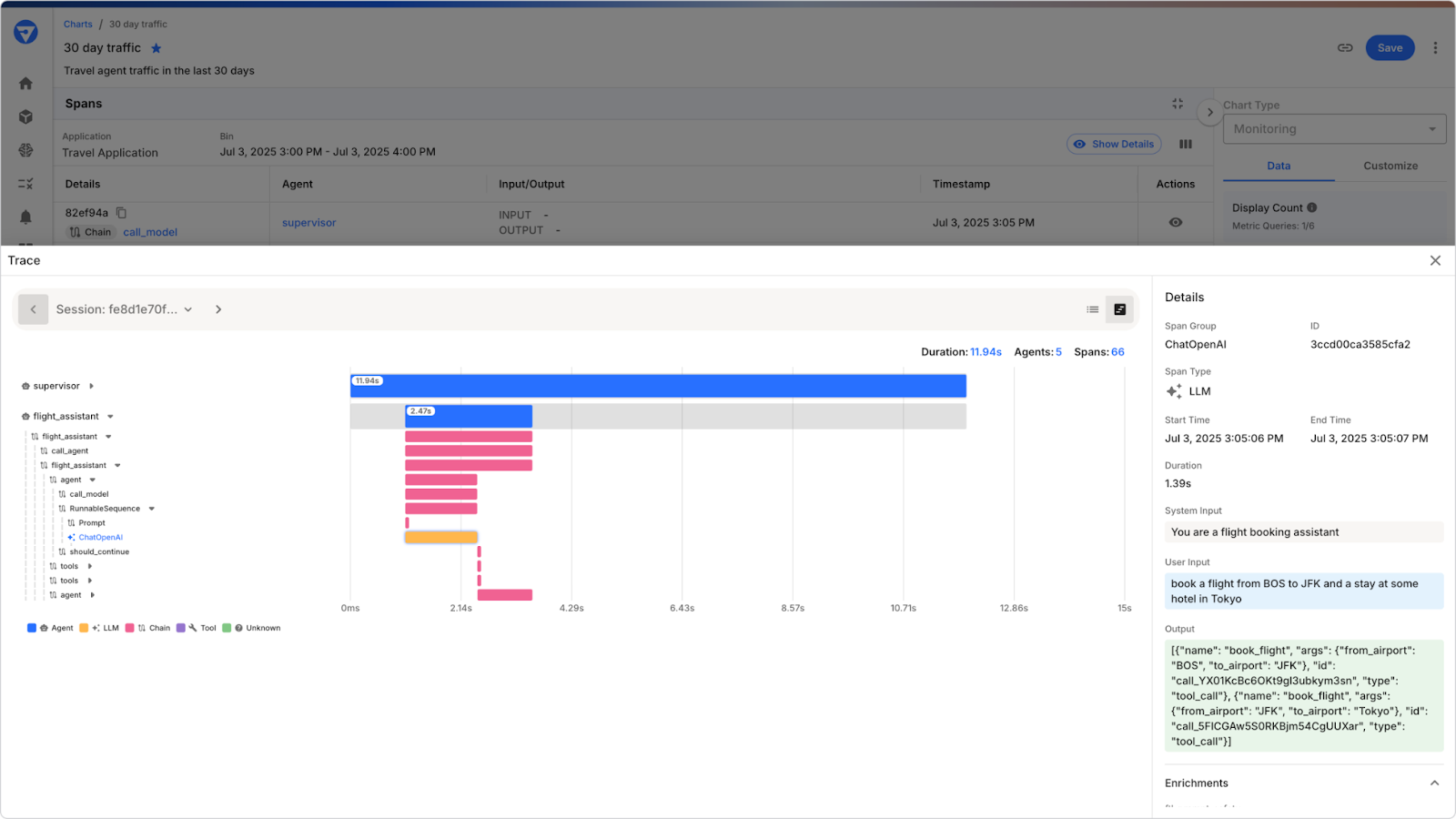
Multi-Channel Behavioral Inconsistency
OpenClaw routes the same agent logic across WhatsApp, Telegram, Slack, Discord, and others. Each channel has different message formats, media handling capabilities, threading models, and delivery guarantees. An agent that behaves reliably on one channel can behave differently on another not because the agent changed, but because the context it receives changed. Without per-channel behavioral monitoring, these inconsistencies accumulate invisibly.
Tool Execution Without Accountability
OpenClaw agents can execute bash commands, control browsers, manage files, and invoke external APIs. These are high-consequence actions. A tool that is called with the wrong parameters, a browser action that produces an unexpected result, a scheduled task that runs when it shouldn't, these failures have real effects in the real world. Logging that something happened is not the same as understanding whether it happened correctly, what it cost, and whether it should be flagged for review.
Cost, Latency and Token Attribution
OpenClaw manages multiple concurrent agent sessions, potentially across multiple model providers. Token usage accumulates across every message, every tool call, every context retrieval. Without instrumentation that attributes cost to specific sessions, channels, and task types, there is no way to understand where spend is concentrating, which workflows are inefficient, or when usage is anomalous.
Behavioral Drift Over Time
Model providers update their underlying models continuously. A system prompt that produced reliable behavior in January may produce subtly different behavior by March not because the prompt changed, but because the model did. Detecting this kind of drift requires a behavioral baseline: a record of how the agent responded historically that can be compared against how it responds today. Without that record, drift is undetectable until it becomes a visible failure.
Why This is Harder for Agents Than for Traditional Software
The distributed nature of agentic systems compounds the observability challenge in ways that matter at scale.
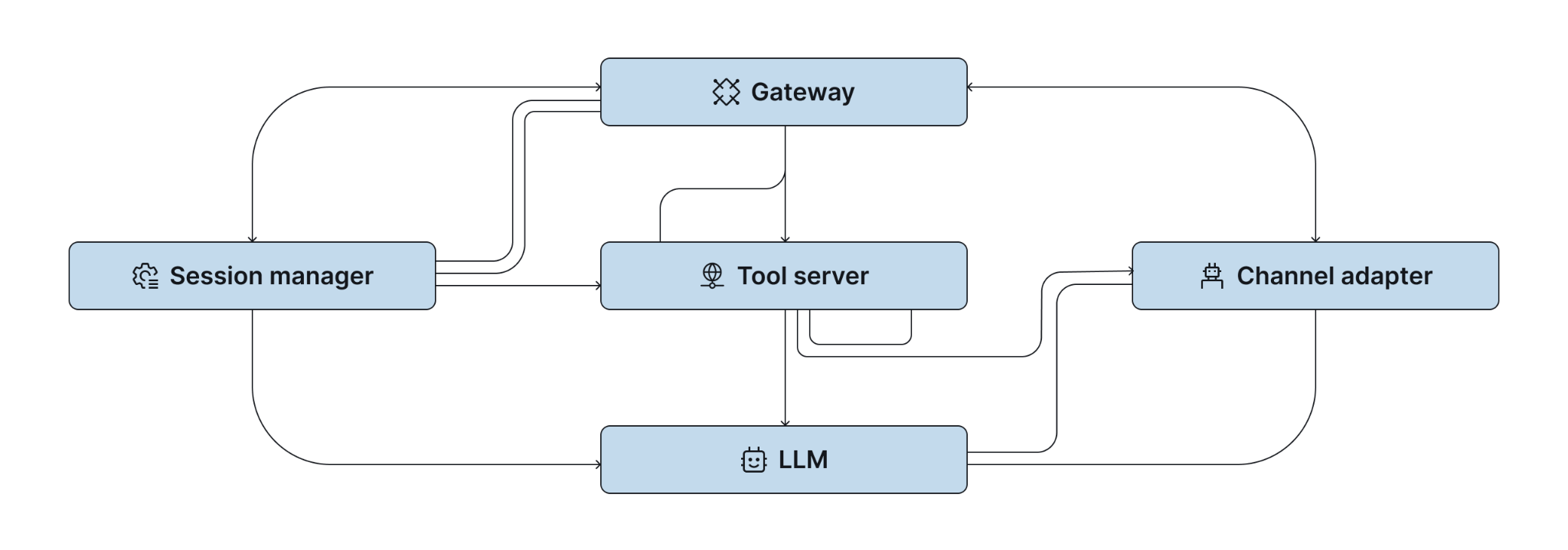
A single user interaction with OpenClaw might involve the Gateway receiving a message, a session manager selecting the right agent context, a tool server executing a browser action, an LLM provider generating a response, and a channel adapter formatting and delivering the output. These components run across different processes, potentially different machines, and different runtime environments. Each hand-off is a potential point of failure and a potential source of latency.
Connecting these steps into a coherent picture, understanding that the slow response a user experienced on Discord at 3pm was caused by a browser tool timeout that cascaded into a retry loop that exhausted the context window, requires observability that spans the entire chain. Not just logging at each component, but correlation across them.
This is the infrastructure problem that makes agentic observability genuinely hard, and genuinely important. It is also why platforms that invest in it early earn a significant operational advantage over those that treat it as a future concern.
Why This Gap is an Industry-Wide Challenge
The observability gap is a characteristic of the entire emerging category of autonomous AI agent platforms, not a specific failure of any one project.
These platforms were, almost universally, built first for capability; for the breadth of channels they could connect, the tools they could execute, the models they could route to. Observability was deferred, reasonably, in favor of getting the core functionality working. That prioritization made sense at the prototype stage, but that stage has changed.
As autonomous AI assistants move from personal tools to critical infrastructure, managing business communications, executing workflows, representing organizations to customers, the operational requirements change with it. The question is no longer whether the agent can do the thing. It is whether you can verify that it did the thing correctly, detect when it didn't, and understand why.
That is an observability problem. And in this category, it largely remains unsolved.
The Standard That Serious Platforms Will Have to Meet
For autonomous AI agents to be trusted at scale, observability cannot be an afterthought. It needs to be foundational, instrumented into the platform from the routing layer through the tool execution layer through the model provider interface.
Concretely, that means: traces that correlate a user's message to every decision and action taken in response. Metrics that surface latency, cost, and success rates by channel, session, and task type. Behavioral monitoring that detects when agent outputs drift from established baselines. Real-time guardrails that catch safety violations and policy breaches before they reach users. Audit trails that answer the question "what did this agent do, and why?" with data rather than inference.
This is not a distant aspiration. It is the baseline that enterprise deployment requires — and as autonomous AI assistants become mainstream, it will become the baseline that any serious deployment requires.
Platforms that build this infrastructure early will earn the operational trust that converts early adopters into long-term users. Those that defer it will find that trust increasingly difficult to establish as the stakes of agentic deployment rise.
Closing the Gap
The distributed nature of these systems, multiple channels, multiple tools, multiple model providers, multiple concurrent sessions, creates a telemetry surface that is genuinely complex to instrument correctly and to correlate meaningfully.
But the complexity is not a reason to defer. It is a reason to take it seriously now, before the systems running on these platforms are handling workflows where the cost of invisible failures is high.
OpenClaw represents some of the best thinking in open-source AI agent architecture. Closing its observability gap and the broader gap across this category is the work that will determine whether these platforms earn the trust their capabilities deserve.
See What Your Agents are Actually Doing
When your agents are making decisions on behalf of your organization, you need more than logs. You need visibility. Production-grade agentic observability means understanding not just what your agents did, but whether they did it correctly, safely, and within the boundaries your organization requires.
That is what Fiddler is built for. As the AI Control Plane for enterprise teams, Fiddler brings full-lifecycle observability to agentic systems, from pre-deployment evaluation through production monitoring, with in-environment guardrails that operate at under 100ms without sending your data to a third party.
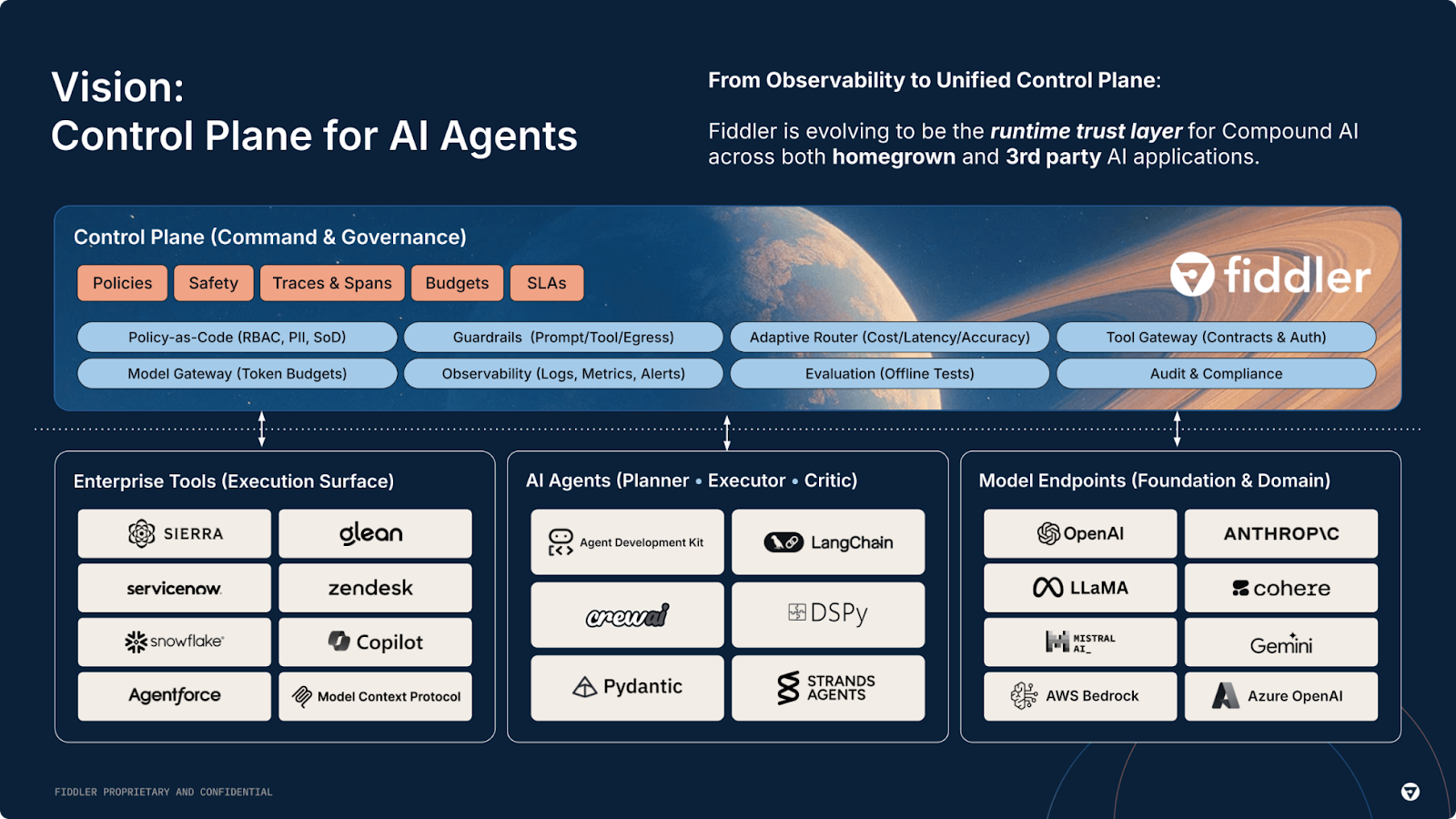
If you are serious about running AI agents in production, see how Fiddler approaches agentic observability.