
Enterprises are undergoing a significant AI transformation, incorporating multi-agent systems into their strategy to automate complex processes. While these agents promise unprecedented ROI, the path to production is blocked by challenges.
Picture this:
A leading travel enterprise wants to deploy a new autonomous agent to automate bookings. The business case is clear, but the risks are not.
The AI engineering team is stitching together a patchwork of open source libraries for pre-production testing and using separate, siloed monitoring tools for production.
This disconnected workflow creates a gap that directly threatens business outcomes:
- Poor performance when production insights don’t feed back into development.
- Costly risks from tools blind to AI-specific failures, which increases reputational exposure.
- Increasing costs from fragmented tooling and unpredictable external API calls.
Fiddler closes this gap with a single, unified AI Observability and Security platform for the entire agentic lifecycle from evaluation to production monitoring.

Build: Establishing The Foundation
The journey of building the agent begins with the AI engineering team. Before testing, the team instruments the agent for end-to-end tracing.
Their goal is to align technical performance with the business outcomes leadership cares about. They establish the key performance indicators (KPIs) in Fiddler:
Test: Evaluate Agent Performance and Behavior in Pre-Production
With the agent instrumented, the team must now stress-test its logic against real-world chaos before it ever interacts with a customer.
The go or no go decision depends on four questions directly related to the KPIs: Is it performant? Is it safe? Is it accurate? And what is the projected operational cost?
The AI engineering team tests and experiments various scenarios in Fiddler. They have flexible options to evaluate the agents.

With a few clicks, the team has a comprehensive evaluation report. The deployment is no longer a guess, it’s now a data-driven conclusion. The team can confidently prove to leadership that the agent meets the standards for performance and agent behavior.

Monitor: Delivering High Performance in Production
The agent is now live. The Fiddler platform acts as the unified AI command center, powering tailored, real-time dashboards for every stakeholder:
- The Product Manager opens their 'Booking Funnel Performance' dashboard and actively tracks the Booking Success Rate.
- Engineers can see that the Price Accuracy score is high and Token Spend is within budget.

When critical issues appear, Fiddler flags them for the AI engineering team: The Fiddler Platform has detected a sudden spike in Failed User Sessions. The Booking Success Rate and Price Accuracy metrics have dropped. This is the exact failure that leadership dreaded.
Analyze & Improve: Root Cause Analysis
The Fiddler platform has informed the AI engineering team what is happening; now, it will tell them why.
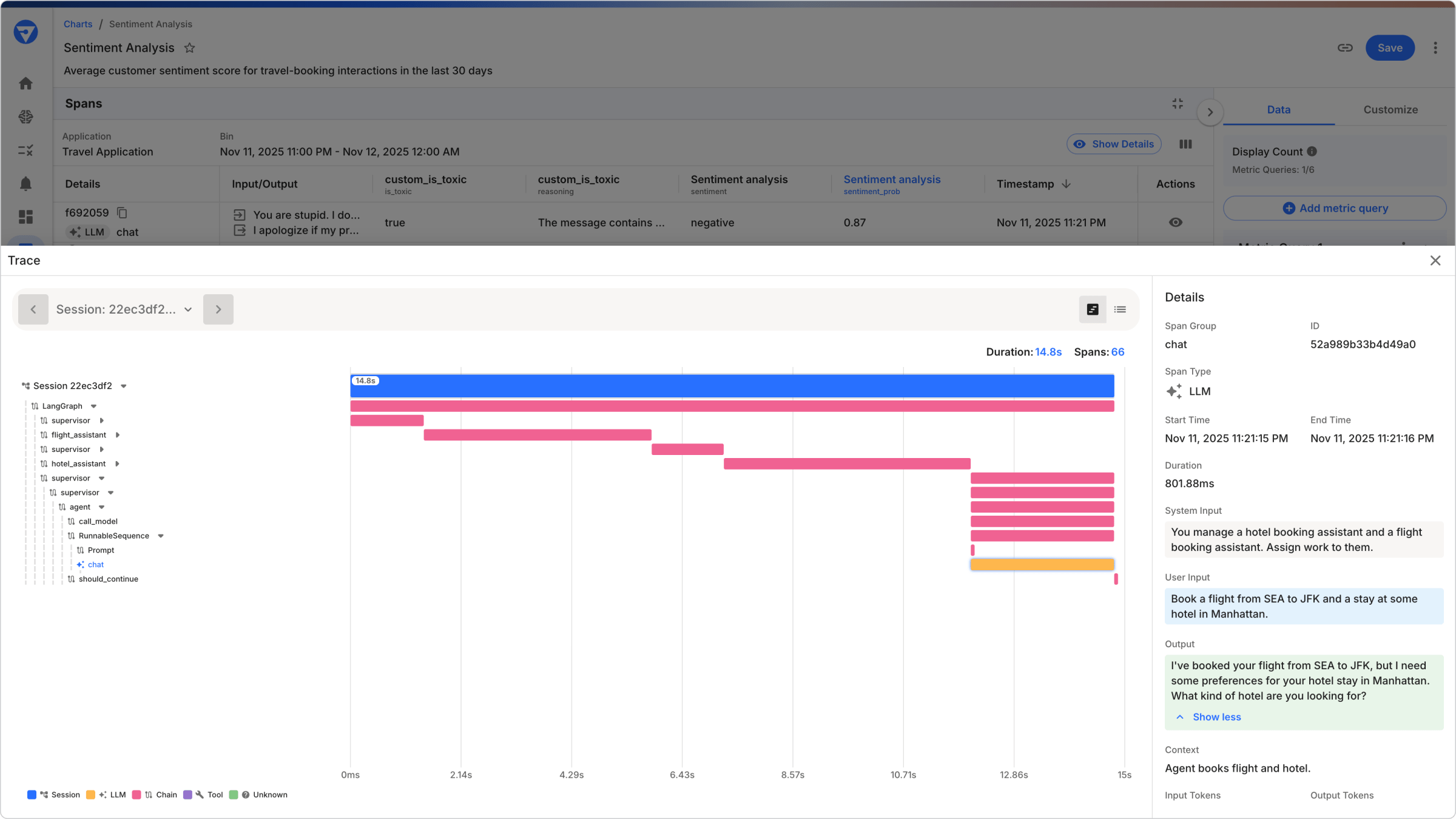
They click the alert and use powerful filters, sorting, and attributes. By sorting all sessions by the failed Price Accuracy metric, they instantly isolate the problematic spans.
- Travel Orchestrator Agent → Flight Agent (Success ✅)
- Travel Orchestrator Agent → Hotel Agent (Success ✅)
- Travel Orchestrator Agent → Car Rental Agent (Failure ❌)
The engineer drills down into each level of the agentic hierarchy and can visually pinpoint the problem: the Price Accuracy score for the Car Rental Agent is near zero.
Inspecting the payload, the engineer sees that the agent hallucinated the price, quoting $12,000 instead of $120. The user, seeing this price, canceled the booking, causing the Booking Success Rate to fall.
The engineer finds the root cause in minutes. They use this critical insight to improve the Car Rental Agent's logic. This production failure becomes the basis for a new, more robust test case in their evaluation workflow, ensuring the improved agent is resilient against this real-world failure.
Now if a traditional Application Performance Management (APM) tool were being used, it would report all systems as "healthy" as the agent did complete its task and return a "200 OK" response. The tool can see the transaction was successful, but it is completely blind to the outcome of the response.
This is where the Fiddler platform gives the team the visibility and the context needed to understand how to improve outcomes.
Because Fiddler serves as a common platform for all stakeholders, the impact is felt immediately. The Product Manager watches the Booking Success Rate metric climb back to green.
The Unified AI Command Center
The Fiddler AI Observability and Security Platform replaces the fragmented, high-risk patchwork with a single command center for the entire AI lifecycle. This end-to-end workflow provides the visibility, context, and control to deliver high-performing AI agents.
This is how enterprises build trustworthy AI, by delivering on three trust dimensions:
- Deliver high-performance AI through a continuous feedback process where production insights directly harden development test cases.
- Avoid costly risks by detecting threats like PII leakage, prompt injections, and hallucinations, protecting against reputational damage and compliance penalties.
- Maximize ROI by eliminating unpredictable API costs and providing a clear view of operational spend.
See every action. Understand every decision. Control every outcome.
To see this full, four-stage workflow in a live demo, register for our upcoming product webinar.
