The rapid rise of Generative AI has made it a topic of Enterprise board-level conversations. As a result, business teams are rushing in to pilot and productize use cases to leverage what is seen as a once in a decade technology paradigm shift — one that can materially change the competitive landscape for incumbents.
Amazon Bedrock is one of the primary ways for enterprises to build and deploy these generative AI applications in a secure and scalable way. It offers a large selection of text and image foundation models (FMs) across open source (LLaMa), closed source (Anthropic, Stability) and home grown (Titan) solutions.
Deploying generative AI, however, comes with increased risks over predictive AI.

As with predictive models, use cases building on top of LLMs can decay in silence taking in prompts that don't provide correct responses catching ML teams unaware and impacting business metrics that depend on these models. Statistical drift measures can be used to stay on top of this performance degradation.
LLMs bring new AI concerns, like correctness (hallucinations), privacy (PII), safety (toxicity) and LLM robustness, which cause business risks. Hallucinations, for example, hinder end-users from receiving correct information to make better decisions, and negatively impact your business. Without observability, your use cases can not just negatively impact key metrics but also increase brand and PR risk.
This blog post shows how your LLMOps team can improve data scientist productivity and reduce time to detect issues for your LLM deployments in Amazon Bedrock by integrating with the Fiddler AI Observability platform to validate, monitor, and analyze them in a few simple steps discussed below.
Amazon Bedrock and Fiddler Solution Overview

The reference architecture above highlights the primary points of integration. Fiddler exists as a “sidecar” to your existing Bedrock generative AI workflow. In the steps below, you will register information about your Bedrock model, upload your test or fine-tuning dataset with Fiddler, and publish your model’s prompts, responses, embeddings and any metadata into Fiddler.
How to Integrate Amazon Bedrock with Fiddler
This post assumes that you have set up Bedrock for your LLM deployment. The remainder of this post will walk you through the simple steps to integrate your LLM with Fiddler:
- Enable Model Invocation Logging for your Bedrock account
- Onboard information about your LLM application’s “model schema” in your Fiddler environment
- Create an AWS Lambda to publish Bedrock logging to Fiddler
- Explore Fiddler’s LLM Monitoring capabilities in your Fiddler trial environment
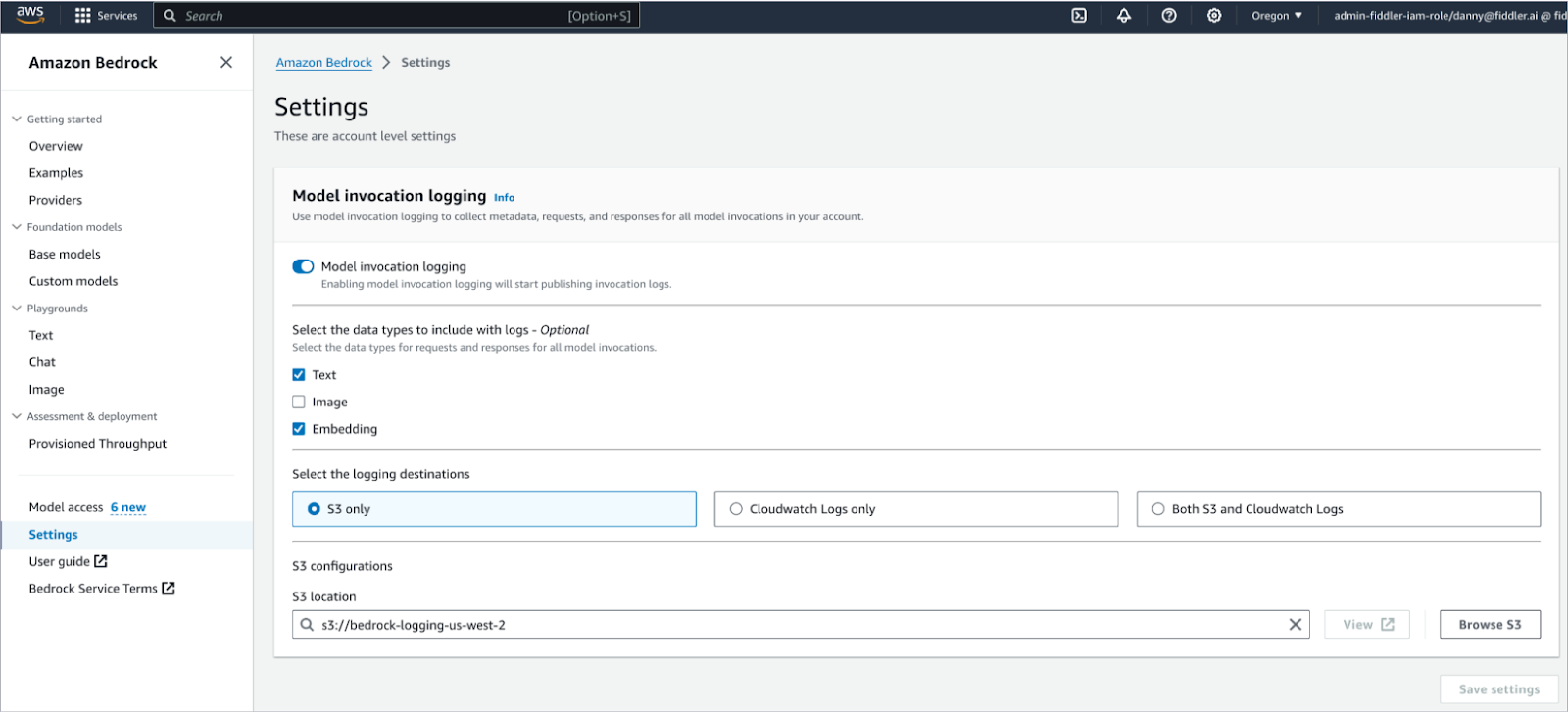
1 - Enable Model Invocation Logging in Bedrock
Within Bedrock, navigate to your Bedrock settings and ensure that you have enabled data capture into an Amazon S3 bucket. This will store the invocation logging for your Bedrock FMs (queries, prompts with source documents, and responses) your model makes each day as JSON files in S3.
2 - Register Information About Your Model in Your Fiddler Environment
Before you can begin publishing events from this Amazon Bedrock model into Fiddler, you will need to create a project within your Fiddler environment and provide Fiddler details about our model through a step called model registration. Note: If you want to use a premade SageMaker Studio Lab notebook rather than copy and paste the steps below, you can reference the Fiddler Quickstart notebook from here.
First, you must install the Fiddler Python Client in your SageMaker notebook and instantiate the Fiddler client. You can get the <code>AUTH_TOKEN</code> from the ‘Settings’ page in your Fiddler trial environment.
# Connect to the Fiddler Environment
import fiddler as fdl
import pandas as pd
URL = 'https://yourcompany.try.fiddler.ai'
ORG_ID = 'yourcompany'
AUTH_TOKEN = ''
client = fdl.FiddlerApi(URL, ORG_ID, AUTH_TOKEN)Next, create a project within your Fiddler trial environment
# Create Project
PROJECT_ID = 'chatbot'
DATASET_ID = 'typical-questions'
MODEL_ID = 'model_3'
client.create_project(PROJECT_ID)Now let’s upload a baseline dataset that Fiddler can use as a point of reference. The baseline dataset should represent a handful of “common” LLM application queries and responses. Thus, when the nature of the questions and responses starts to change, Fiddler can compare the new data distributions to the baseline as a point of reference and detect outliers, shifts in topics (i.e. data drift), and problematic anomalies.
# Upload historical queries and responses to serve as a baseline
df_baseline = pd.read_csv('historical-questions-responses.csv')
df_schema = fdl.DatasetInfo.from_dataframe(df,max_inferred_cardinality=1000)
client.upload_dataset(dataset={'baseline' : df_baseline}, dataset_id=DATASET_ID, info=df_schema)Lastly, before you can start publishing LLM conversations into Fiddler for observability, you need to onboard a “model” that represents the inputs, outputs and metadata used by your LLM application. Let’s first create a <code>model_info</code> object which contains the schema for your application.
Fiddler will create the embeddings for our unstructured inputs, like query, response and the source documents passed to our Bedrock FM retrieved via RAG. Fiddler offers a variety of “enrichments” that can flag your LLM-applications for potential safety issues like hallucinations, toxicity, and PII leakage. Additionally, you can pass any other metadata to Fiddler like end user feedback (likes/dislikes), FM costs, FM latencies, and source documents from the RAG-retrieval.
You’ll note in the <code>model_info</code> object below, we’re defining the primary features as the query and the response, as well as a list of metadata we will be tracking too — some passed to Fiddler like docs, feedback, cost and latency and some calculated by Fiddler like toxicity and PII leakage.
# Specify task
model_task = fdl.ModelTask.LLM
# Specify column types, Fiddler will create the embedding vectors for us for our unstructured inputs
features = ['query', 'response']
metadata = ['doc_0', 'doc_1', 'doc_2', 'cost', \
'latency', 'feedback', 'fdl_query_toxicity', \
'fdl_response_toxicity', 'fdl_query_pii', 'fdl_response_pii']
# Generate ModelInfo Object
model_info = fdl.ModelInfo.from_dataset_info(
dataset_info=df_schema,
dataset_id=DATASET_ID,
model_task=model_task,
metadata_cols=metadata
features=features
)
model_infoThen, you can onboard the LLM application “model” using your new <code>model_info</code> object.
# Register Info about your model with Fiddler
client.add_model(
project_id=PROJECT_ID,
model_id=MODEL_ID,
dataset_id=DATASET_ID,
model_info=model_info
)After this onboarding, you should see the schema of your LLM application in Fiddler like so:

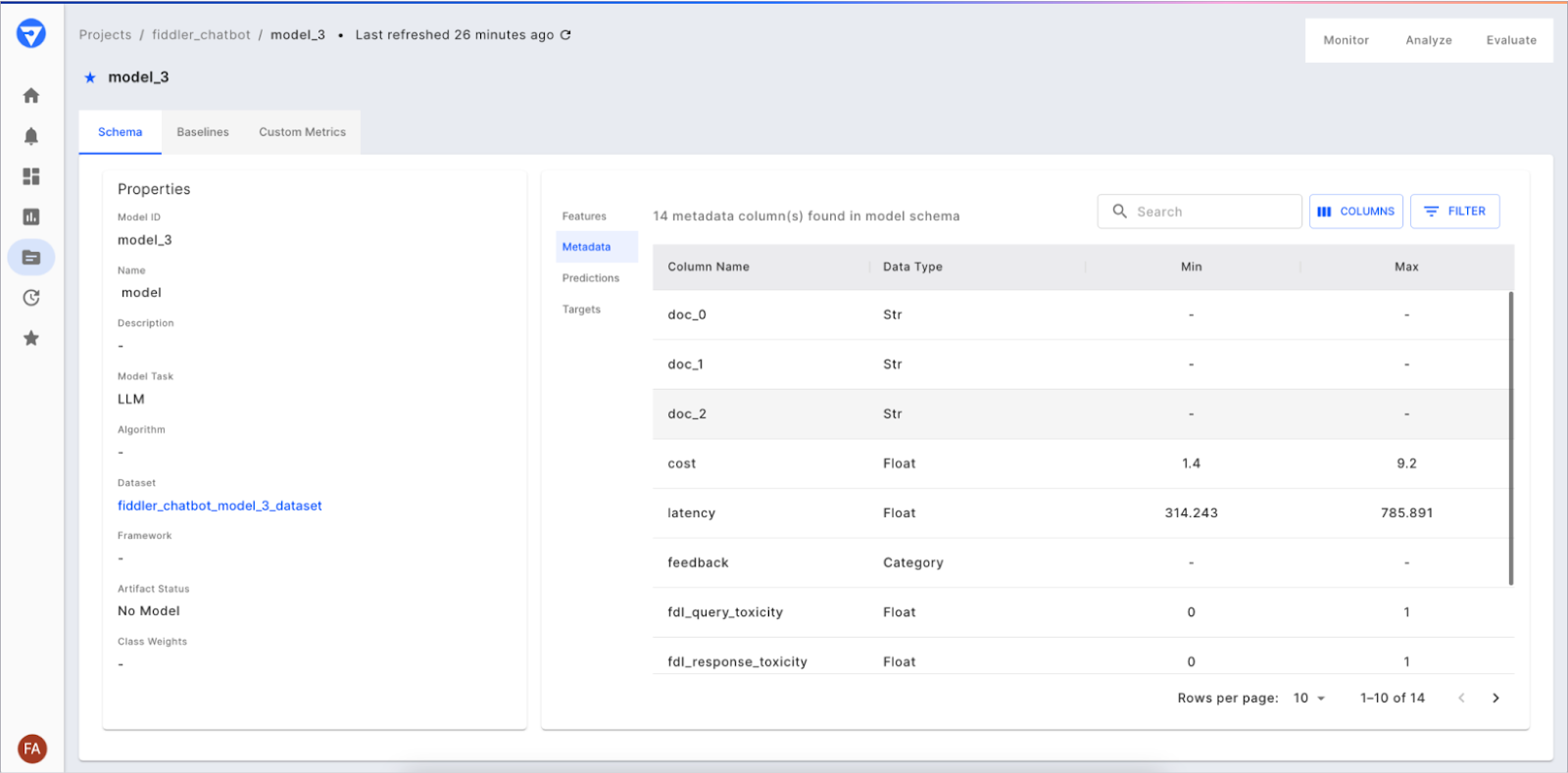
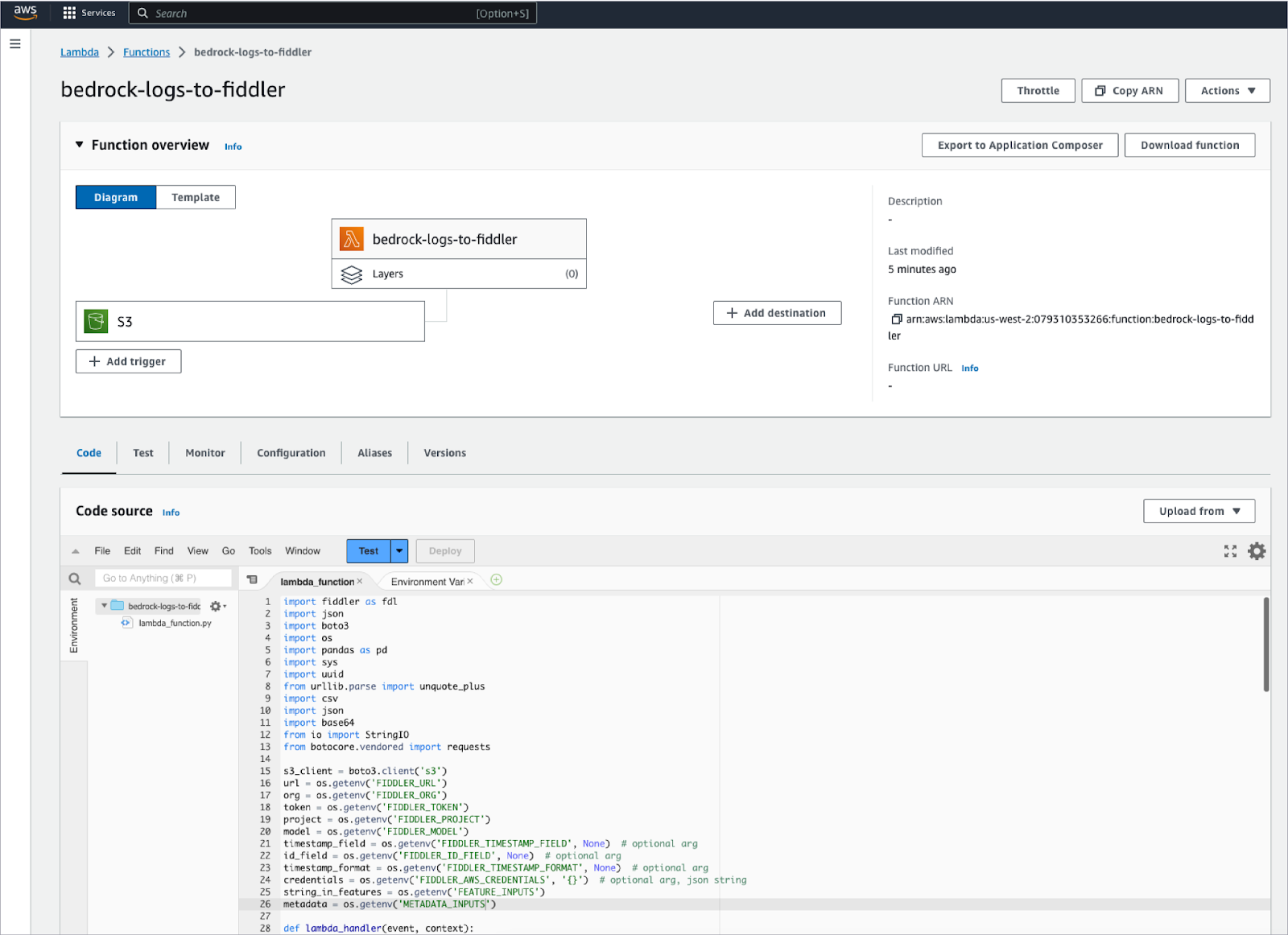
3 - Create an AWS Lambda Function to Publish Bedrock Logs to Fiddler
Using the simple-to-deploy serverless architecture of AWS Lambda, you can quickly build the mechanism required to move the logging from your Bedrock FMs from the S3 bucket (setup in step 1 above), into your newly provisioned Fiddler trial environment. This Lambda function will be responsible for opening any new JSON event log files in your model’s S3 bucket, parsing and formatting the appropriate fields from your JSON logs into a dataframe and then publishing that dataframe of events to your Fiddler trial environment.
The Lambda function needs to be configured to trigger off of newly created files in your S3 bucket. This makes it a snap to ensure that any time your model makes new inferences, those events will be stored in S3 and will be well on their way to Fiddler to drive the model observability your company needs.
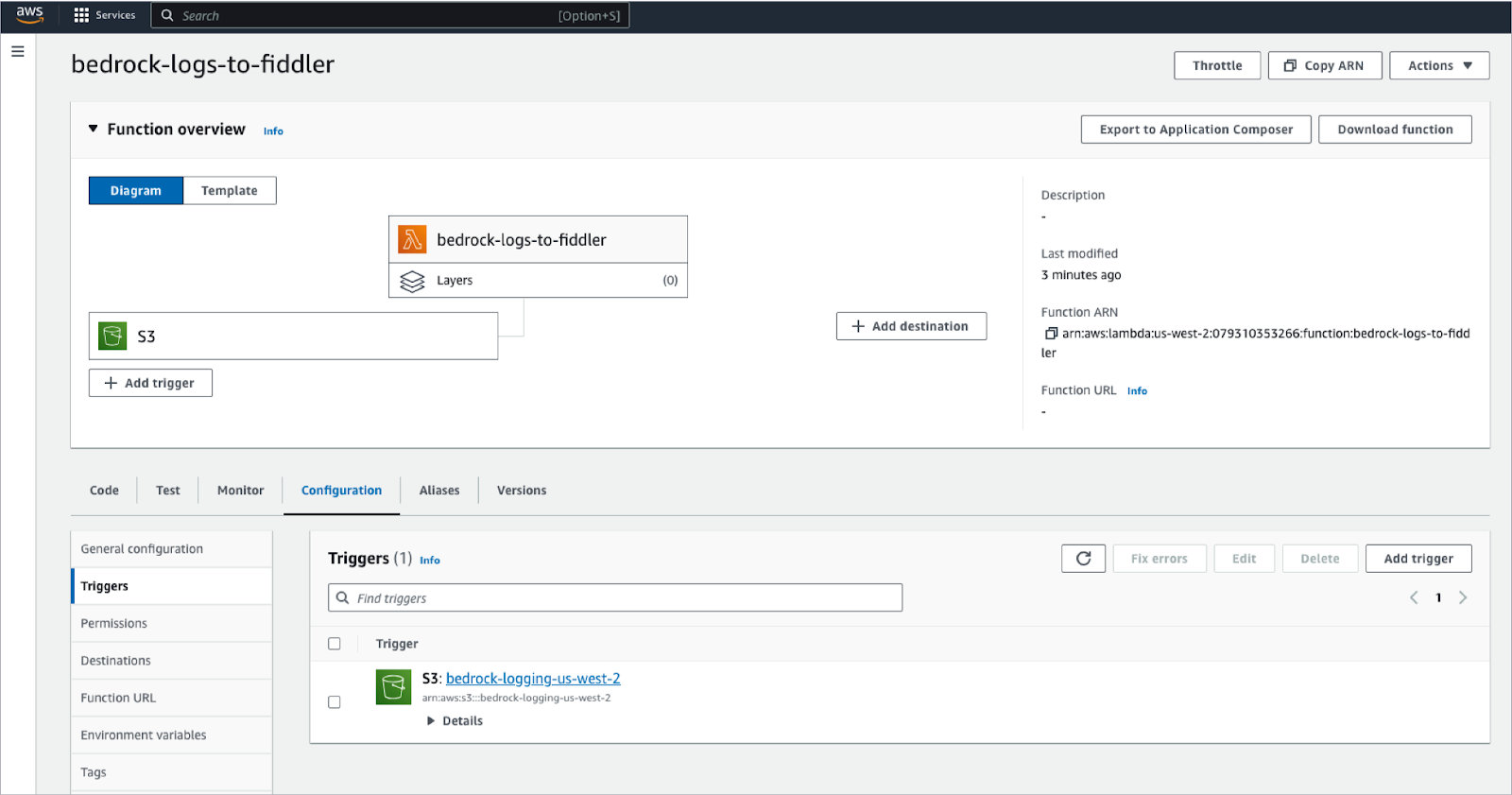
To simplify this further, the code for this AWS Lambda function can be accessed by contacting the Fiddler sales team. This code can be quickly tailored to meet the specific needs of your LLM application.
You will also need to specify Lambda environment variables so the Lambda function knows how to connect to your Fiddler trial environment, and what the inputs and outputs are within the JSON files being captured by your model.
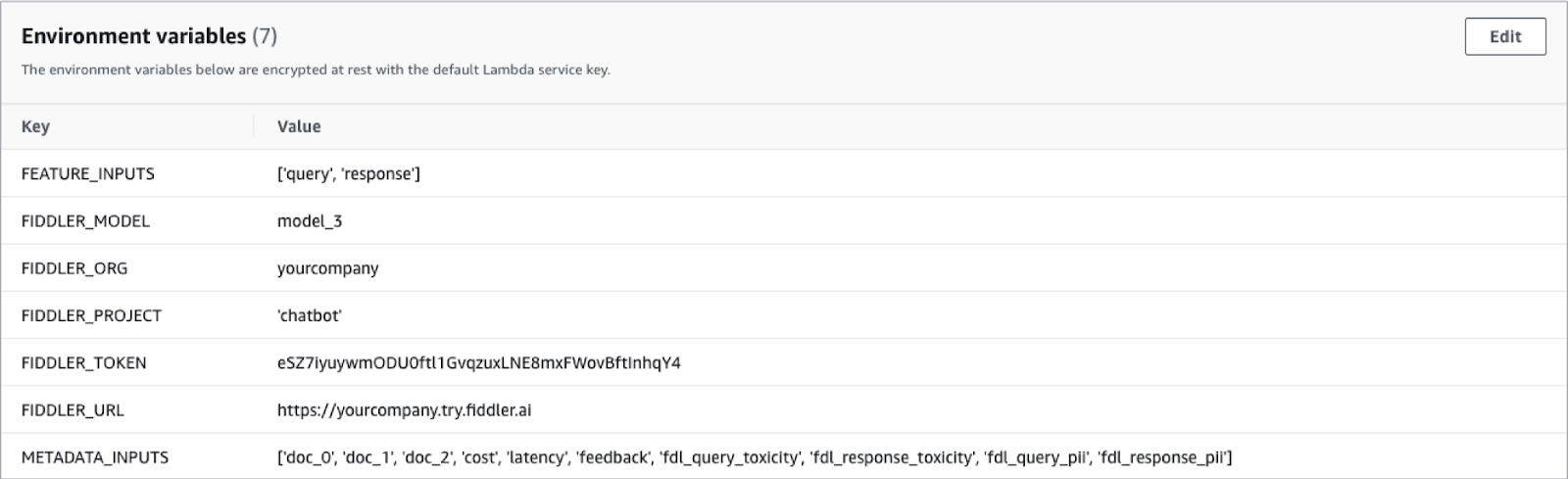
With this Lambda function in place, the logs captured in S3 by your Bedrock FMs will automatically start flowing into your Fiddler environment providing you with world-class LLM observability.
4 - Explore Fiddler’s Monitoring Capabilities in Your Fiddler Environment

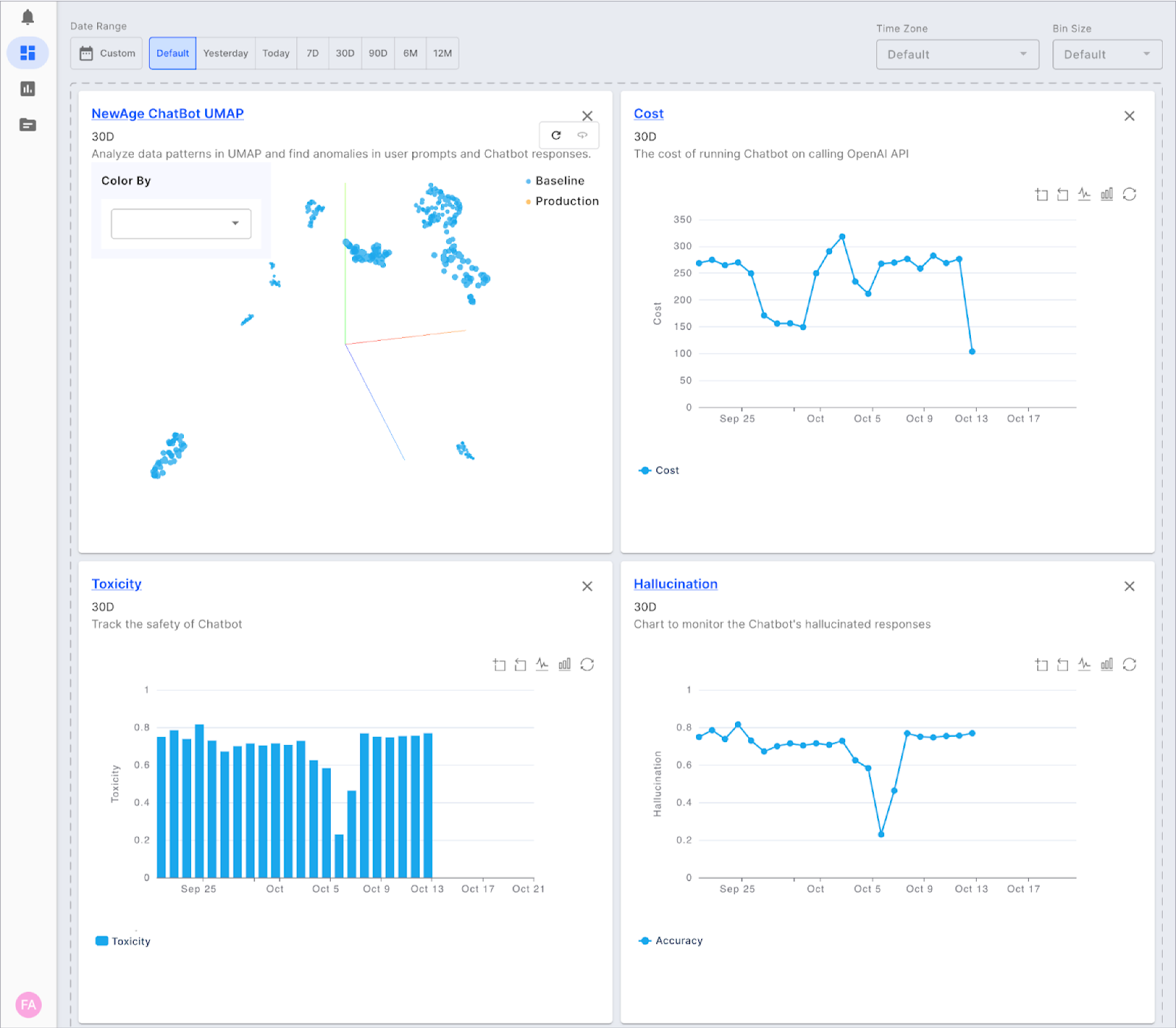
Now that you have Fiddler AI Observability for LLMOps connected in your environment, you have an end-to-end LLMOps workflow spanning from pre-production to production, creating a continuous feedback loop to improve your LLMs.

You can further explore the Fiddler platform by validating LLMs and monitoring LLM metrics like hallucination, PII, toxicity and other LLM-specific metrics, analyzing trends and patterns using a 3D UMAP, and gaining insights on how to improve LLMs with better prompt engineering and fine-tuning techniques. Create dashboards and reports within Fiddler to share and review with other ML teams and business stakeholders to improve LLM outcomes.
Request a demo to chat with our AI experts. Fiddler is an AWS APN partner and available on the AWS Marketplace.
